Deploy and use shared-data StarRocks
This topic describes how to deploy and use a shared-data StarRocks cluster.
The shared-data StarRocks cluster is specifically engineered for the cloud on the premise of separation of storage and compute. It allows data to be stored in object storage that is compatible with the S3 protocol (for example, AWS S3 and MinIO). You can achieve not only cheaper storage and better resource isolation, but elastic scalability for your cluster. The query performance of the shared-data StarRocks cluster aligns with that of a shared-nothing StarRocks cluster when the local disk cache is hit.
Compared to the classic StarRocks architecture, separation of storage and compute offers a wide range of benefits. By decoupling these components, StarRocks provides:
- Inexpensive and seamlessly scalable storage.
- Elastic scalable compute. Because data is no longer stored in BE nodes, scaling can be done without data migration or shuffling across nodes.
- Local disk cache for hot data to boost query performance.
- Adjustable time-to-live (TTL) for cached hot data. StarRocks automatically removes the expired cached data to save the local disk space.
- Asynchronous data ingestion into object storage, allowing a significant improvement in loading performance.
The architecture of the shared-data StarRocks cluster is as follows:
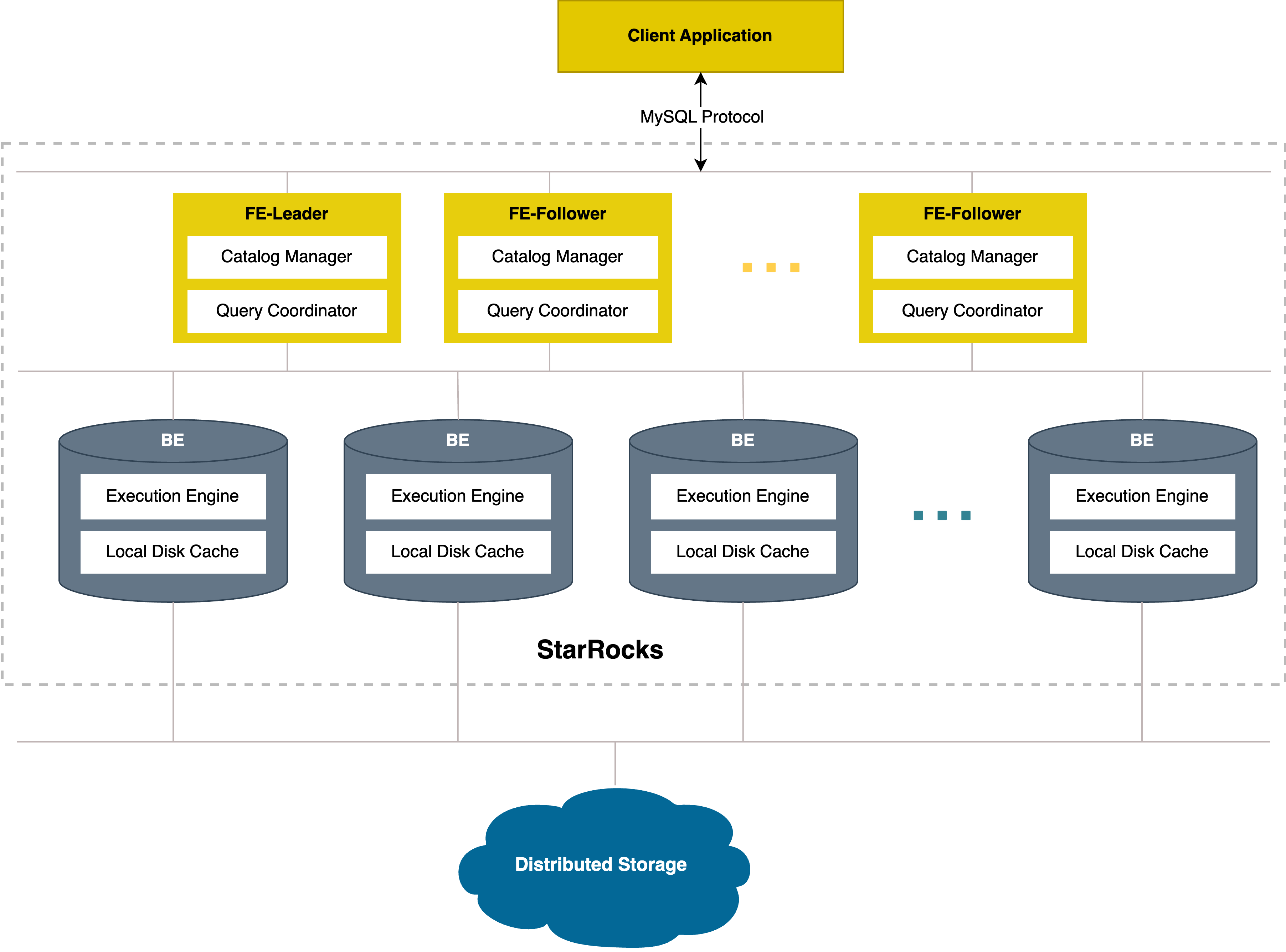
This feature is supported from v3.0.
Deploy a shared-data StarRocks cluster
The deployment of a shared-data StarRocks cluster is similar to that of a shared-nothing StarRocks cluster. The only difference is the parameters in the configuration files of FE and BE fe.conf and be.conf. This section only lists the FE and BE configuration items you need to add to the configuration files when you deploy a shared-data StarRocks cluster. For detailed instructions on deploying a shared-nothing StarRocks cluster, see Deploy StarRocks.
Configure FE nodes for shared-data StarRocks
Before starting FEs, add the following configuration items in the FE configuration file fe.conf:
| Configuration item | Description |
|---|---|
| run_mode | The running mode of the StarRocks cluster. Valid values: shared_data and shared_nothing (Default). shared_data indicates running StarRocks in shared-data mode. shared_nothing indicates running StarRocks in shared-nothing mode.CAUTION You cannot adopt the shared_data and shared_nothing modes simultaneously for a StarRocks cluster. Mixed deployment is not supported.DO NOT change run_mode after the cluster is deployed. Otherwise, the cluster fails to restart. The transformation from a shared-nothing cluster to a shared-data cluster or vice versa is not supported. |
| cloud_native_meta_port | The cloud-native meta service RPC port. Default: 6090. |
| cloud_native_storage_type | The type of object storage you use. Valid value: S3 (Default). |
| aws_s3_path | The S3 path used to store data. It consists of the name of your S3 bucket and the sub-path (if any) under it, for example, testbucket/subpath. |
| aws_s3_endpoint | The endpoint used to access your S3 bucket, for example, https://s3.us-west-2.amazonaws.com. |
| aws_s3_region | The region in which your S3 bucket resides, for example, us-west-2. |
| aws_s3_use_aws_sdk_default_behavior | Whether to use the default authentication credential of AWS SDK. Valid values: true and false (Default). |
| aws_s3_use_instance_profile | Whether to use Instance Profile and Assumed Role as credential methods for accessing S3. Valid values: true and false (Default).
|
| aws_s3_access_key | The Access Key ID used to access your S3 bucket. |
| aws_s3_secret_key | The Secret Access Key used to access your S3 bucket. |
| aws_s3_iam_role_arn | The ARN of the IAM role that has privileges on your S3 bucket in which your data files are stored. |
| aws_s3_external_id | The external ID of the AWS account that is used for cross-account access to your S3 bucket. |
-
If you use AWS S3
-
If you use the default authentication credential of AWS SDK to access S3, add the following configuration items:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example, us-west-2
aws_s3_region = <region>
# For example, https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_aws_sdk_default_behavior = true -
If you use IAM user-based credential (Access Key and Secret Key) to access S3, add the following configuration items:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example, us-west-2
aws_s3_region = <region>
# For example, https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
If you use Instance Profile to access S3, add the following configuration items:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example, us-west-2
aws_s3_region = <region>
# For example, https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_instance_profile = true -
If you use Assumed Role to access S3, add the following configuration items:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example, us-west-2
aws_s3_region = <region>
# For example, https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_instance_profile = true
aws_s3_iam_role_arn = <role_arn> -
If you use Assumed Role to access S3 from an external AWS account, add the following configuration items:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example, us-west-2
aws_s3_region = <region>
# For example, https://s3.us-west-2.amazonaws.com
aws_s3_endpoint = <endpoint_url>
aws_s3_use_instance_profile = true
aws_s3_iam_role_arn = <role_arn>
aws_s3_external_id = <external_id>
-
-
If you use GCP Cloud Storage:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example: us-east-1
aws_s3_region = <region>
# For example: https://storage.googleapis.com
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key> -
If you use MinIO:
run_mode = shared_data
cloud_native_meta_port = <meta_port>
cloud_native_storage_type = S3
# For example, testbucket/subpath
aws_s3_path = <s3_path>
# For example: us-east-1
aws_s3_region = <region>
# For example: http://172.26.xx.xxx:39000
aws_s3_endpoint = <endpoint_url>
aws_s3_access_key = <access_key>
aws_s3_secret_key = <secret_key>
Configure BE nodes for shared-data StarRocks
Before starting BEs, add the following configuration items in the BE configuration file be.conf:
starlet_port = <starlet_port>
storage_root_path = <storage_root_path>
| Configuration item | Description |
|---|---|
| starlet_port | The BE heartbeat service port. Default value: 9070. |
| storage_root_path | The storage volume directory that the local cached data depends on and the medium type of the storage. Multiple volumes are separated by semicolon (;). If the storage medium is SSD, add ,medium:ssd at the end of the directory. If the storage medium is HDD, add ,medium:hdd at the end of the directory. Example: /data1,medium:hdd;/data2,medium:ssd. Default value: ${STARROCKS_HOME}/storage. |
NOTE
The data is cached under the directory
<storage_root_path>/starlet_cache.
Use your shared-data StarRocks cluster
The usage of shared-data StarRocks clusters is also similar to that of a classic StarRocks cluster. The only difference is that you must create a special table to use object storage for your data.
Create a table
After connecting to your shared-data StarRocks cluster, create a database and then table in the database. Currently, shared-data StarRocks clusters support the following table types:
- Duplicate Key table
- Aggregate table
- Unique Key table
NOTE
Currently, Primary Key table is not supported on StarRocks shared-data clusters.
The following example creates a database cloud_db and a table detail_demo based on Duplicate Key table type, enables the local disk cache, sets the cache expiration time to 30 days, and disables asynchronous data ingestion into object storage:
CREATE DATABASE cloud_db;
USE cloud_db;
CREATE TABLE IF NOT EXISTS detail_demo (
recruit_date DATE NOT NULL COMMENT "YYYY-MM-DD",
region_num TINYINT COMMENT "range [-128, 127]",
num_plate SMALLINT COMMENT "range [-32768, 32767] ",
tel INT COMMENT "range [-2147483648, 2147483647]",
id BIGINT COMMENT "range [-2^63 + 1 ~ 2^63 - 1]",
password LARGEINT COMMENT "range [-2^127 + 1 ~ 2^127 - 1]",
name CHAR(20) NOT NULL COMMENT "range char(m),m in (1-255) ",
profile VARCHAR(500) NOT NULL COMMENT "upper limit value 65533 bytes",
ispass BOOLEAN COMMENT "true/false"
)
DUPLICATE KEY(recruit_date, region_num)
DISTRIBUTED BY HASH(recruit_date, region_num)
PROPERTIES (
"enable_storage_cache" = "true",
"storage_cache_ttl" = "2592000",
"enable_async_write_back" = "false"
);
NOTICE
Since v2.5.7, StarRocks can automatically set the number of buckets (BUCKETS) when you create a table or add a partition. You no longer need to manually set the number of buckets. For detailed information, see determine the number of buckets.
In addition to the regular table PROPERTIES, you need to specify the following PROPERTIES when creating a table for shared-data StarRocks cluster:
| Property | Description |
|---|---|
| enable_storage_cache | Whether to enable the local disk cache. Default: true.
To enable the local disk cache, you must specify the directory of the disk in the BE configuration item storage_root_path. |
| storage_cache_ttl | The duration for which StarRocks caches the loaded data in the local disk if the local disk cache is enabled. The expired data is deleted from the local disk. If the value is set to -1, the cached data does not expire. Default: 2592000 (30 days).CAUTION If you disabled the local disk cache, you do not need to set this configuration item. Setting this item to a value other than 0 when the local disk cache is disabled will cause unexpected behaviors of StarRocks. |
| enable_async_write_back | Whether to allow data to be written into object storage asynchronously. Default: false.
|
View table information
You can view the information of tables in a specific database using SHOW PROC "/dbs/<db_id>". See SHOW PROC for more information.
Example:
mysql> SHOW PROC "/dbs/xxxxx";
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
| TableId | TableName | IndexNum | PartitionColumnName | PartitionNum | State | Type | LastConsistencyCheckTime | ReplicaCount | PartitionType | StoragePath |
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
| 12003 | detail_demo | 1 | NULL | 1 | NORMAL | CLOUD_NATIVE | NULL | 8 | UNPARTITIONED | s3://xxxxxxxxxxxxxx/1/12003/ |
+---------+-------------+----------+---------------------+--------------+--------+--------------+--------------------------+--------------+---------------+------------------------------+
The Type of a table in shared-data StarRocks cluster is CLOUD_NATIVE. In the field StoragePath, StarRocks returns the object storage directory where the table is stored.
Load data into a shared-data StarRocks cluster
Shared-data StarRocks clusters support all loading methods provided by StarRocks. See Overview of data loading for more information.
Query in a shared-data StarRocks cluster
Tables in a shared-data StarRocks cluster support all types of queries provided by StarRocks. See StarRocks SELECT for more information.