BROKER LOAD
功能
Broker Load 是一种基于 MySQL 协议的异步导入方式。您提交导入作业以后,StarRocks 会异步地执行导入作业。您需要通过 SHOW LOAD 语句或者 curl 命令来查看导入作业的结果。有关 Broker Load 的背景信息、前提条件、基本原理、支持的数据文件格式和外部存储系统、以及如何执行单表导入 (Single-Table Load) 和多表导入 (Multi-Table Load) 操作等,请参见从 HDFS 或外部云存储系统导入数据。
语法
LOAD LABEL [<database_name>.]<label_name>
(
data_desc[, data_desc ...]
)
WITH BROKER
(
StorageCredentialParams
)
[PROPERTIES
(
opt_properties
)
]
注意在 StarRocks 中,部分文字是 SQL 语言的保留关键字,不能直接用于 SQL 语句。如果想在 SQL 语句中使用这些保留关键字,必须用反引号 (`) 包裹起来。参见关键字。
参数说明
database_name 和 label_name
label_name 指定导入作业的标签。
database_name 为可选,指定目标 StarRocks 表所在的数据库。
每个导入作业都对应一个在该数据库内唯一的标签。通过标签,可以查看对应导入作业的执行情况,并防止导入相同的数据。导入作业的状态为 FINISHED 时,其标签不可再复用给其他导入作业。导入作业的状态为 CANCELLED 时,其标签可以复用给其他导入作业,但通常都是用来重试同一个导入作业(即使用同一个标签导入相同的数据)以实现数据“精确一次 (Exactly-Once)”语义。
有关标签的命名规范,请参见系统限制。
data_desc
用于描述一批次待导入的数据。每个 data_desc 声明了本批次待导入数据所属的数据源地址、ETL 函数、StarRocks 表和分区等信息。
Broker Load 支持一次导入多个数据文件。在一个导入作业中,您可以使用多个 data_desc 来声明导入多个数据文件,也可以使用一个 data_desc 来声明导入一个路径下的所有数据文件。Broker Load 还支持保证单次导入事务的原子性,即单次导入的多个数据文件都成功或者都失败,而不会出现部分导入成功、部分导入失败的情况。
data_desc 语法如下:
DATA INFILE ("<file_path>"[, "<file_path>" ...])
[NEGATIVE]
INTO TABLE <table_name>
[PARTITION (<partition1_name>[, <partition2_name> ...])]
[TEMPORARY PARTITION (<temporary_partition1_name>[, <temporary_partition2_name> ...])]
[COLUMNS TERMINATED BY "<column_separator>"]
[ROWS TERMINATED BY "<row_separator>"]
[FORMAT AS "CSV | Parquet | ORC"]
[(column_list)]
[COLUMNS FROM PATH AS (<partition_field_name>[, <partition_field_name> ...])]
[SET <k1=f1(v1)>[, <k2=f2(v2)> ...]]
[WHERE predicate]
data_desc 中的必选参数如下:
-
file_path用于指定源数据文件所在的路径。
您可以指定导入一个具体的数据文件。例如,通过指定
"hdfs://<hdfs_host>:<hdfs_port>/user/data/tablename/20210411"可以匹配 HDFS 服务器上/user/data/tablename目录下名为20210411的数据文件。您也可以用通配符指定导入某个路径下所有的数据文件。Broker Load 支持如下通配符:
?、*、[]、{}和^。具体请参见通配符使用规则参考。例如, 通过指定"hdfs://<hdfs_host>:<hdfs_port>/user/data/tablename/*/*"路径可以匹配 HDFS 服务器上/user/data/tablename目录下所有分区内的数据文件,通过"hdfs://<hdfs_host>:<hdfs_port>/user/data/tablename/dt=202104*/*"路径可以匹配 HDFS 服务器上/user/data/tablename目录下所有202104分区内的数据文件。说明
中间的目录也可以使用通配符匹配。
以 HDFS 数据源为例,文件路径中的
hdfs_host和hdfs_port参数说明如下:-
hdfs_host:HDFS 集群中 NameNode 所在主机的 IP 地址。 -
hdfs_port:HDFS 集群中 NameNode 所在主机的 FS 端口。默认端口号为9000。
注意
Broker Load 支持通过 S3 或 S3A 协议访问 AWS S3,因此从 AWS S3 导入数据时,您在文件路径中传入的目标文件的 S3 URI 可以使用
s3://或s3a://作为前缀。 -
-
INTO TABLE用于指定目标 StarRocks 表的名称。
data_desc 中的可选参数如下:
-
NEGATIVE用于撤销某一批已经成功导入的数据。如果想要撤销某一批已经成功导入的数据,可以通过指定
NEGATIVE关键字来导入同一批数据。说明
该参数仅适用于目标 StarRocks 表使用聚合模型、并且所��有 Value 列的聚合函数均为
sum的情况。 -
PARTITION指定要把数据导入哪些分区。如果不指定该参数,则默认导入到 StarRocks 表所在的所有分区中。
-
TEMPORARY_PARTITION指定要把数据导入哪些临时分区。
-
COLUMNS TERMINATED BY用于指定源数据文件中的列分隔符。如果不指定该参数,则默认列分隔符为
\t,即 Tab。必须确保这里指定的列分隔符与源数据文件中的列分隔符一致;否则,导入作业会因数据质量错误而失败,作业状态 (State) 会显示为CANCELLED。需要注意的是,Broker Load 通过 MySQL 协议提交导入请求,除了 StarRocks 会做转义处理以外,MySQL 协议也会做转义处理。因此,如果列分隔符是 Tab 等不可见字符,则需要在列分隔字符前面多加一个反斜线 (\)。例如,如果列分隔符是
\t,这里必须输入\\t;如果列分隔符是\n,这里必须输入\\n。Apache Hive™ 文件的列分隔符为\x01,因此,如果源数据文件是 Hive 文件,这里必须传入\\x01。说明
- StarRocks 支持设置长度最大不超过 50 个字节的 UTF-8 编码字符串作为列分隔符,包括常见的逗号 (,)、Tab 和 Pipe (|)。
- 空值 (null) 用
\N表示。比如,数据文件一共有三列,其中某行数据的第一列、第三列数据分别为a和b,第二列没有数据,则第二列需要用\N来表示空值,写作a,\N,b,而不是a,,b。a,,b表示第二列是一个空字符串。
-
ROWS TERMINATED BY用于指定源数据文件中的行分隔符。如果不指定该参数,则默认行分隔符为
\n,即换行符。必须确保这里指定的行分隔符与源数据文件中的行分隔符一致;否则,导入作业会因数据质量错误而失败,作业状态 (State) 会显示为CANCELLED。该参数从 2.5.4 版本开始支持。其他注意事项和使用条件与上文通过
COLUMNS TERMINATED BY指定列分隔符相同。 -
FORMAT AS用于指定源数据文件的格式。取值包括
CSV、Parquet和ORC。如果不指定该参数,则默认通过file_path参数中指定的文件扩展名(.csv、.parquet、和 .orc)来判断文件格式。 -
column_list用于指定源数据文件和 StarRocks 表之间的列对应关系。语法如下:
(<column_name>[, <column_name> ...])。column_list中声明的列与 StarRocks 表中的列按名称一一对应。说明
如果源数据文件的列和 StarRocks 表中的列按顺序一一对应,则不需要指定
column_list参数。如果要跳过源数据文件中的某一列,只需要在
column_list参数中将该列命名为 StarRocks 表中不存在的列名即可。具体请参见导入过程中实现数据转换。 -
COLUMNS FROM PATH AS用于从指定的文件路径中提取一个或多个分区字段的信息。该参数仅当指定的文件路径中存在分区字段时有效。
例如,源数据文件所在的路径为
/path/col_name=col_value/file1,其中col_name可以对应到 StarRocks 表中的列。这时候,您可以设置参数为col_name。导入时,StarRocks 会将col_value落入col_name对应的列中。说明
该参数只有在从 HDFS 导入数据时可用。
-
SET用于将源数据文件的某一列按照指定的函数进行转化,然后将转化后的结果落入 StarRocks 表中。语法如下:
column_name = expression。以下为两个示例:- StarRocks 表中有三列,按顺序依次为
col1、col2和col3;源数据文件中有四列,前两列按顺序依次对应 StarRocks 表中的col1、col2列,后两列之和对应 StarRocks 表中的col3列。这种情况下,需要通过column_list参数声明(col1,col2,tmp_col3,tmp_col4),并使用 SET 子句指定SET (col3=tmp_col3+tmp_col4)来实现数据转换。 - StarRocks 表中有三列,按顺序依次为
year、month和day;源数据文件中只有一个包含时间数据的列,格式为yyyy-mm-dd hh:mm:ss。这种情况下,需要通过column_list参数声明(tmp_time)、并使用 SET 子句指定SET (year = year(tmp_time), month=month(tmp_time), day=day(tmp_time))来实现数据转换。
- StarRocks 表中有三列,按顺序依次为
-
WHERE用于指定过滤条件,对做完转换的数据进行过滤。只有符合 WHERE 子句中指定的过滤条件的数据才会导入到 StarRocks 表中。
WITH BROKER
在 v2.4 及以前版本,您需要在导入语句中通过 WITH BROKER "<broker_name>" 来指定使用哪个 Broker。自 v2.5 起,您不再需要指定 broker_name,但继续保留 WITH BROKER 关键字。参见从 HDFS 或外部云存储系统导入数据 > 背景信息。
StorageCredentialParams
StarRocks 访问存储系统的认证配置。
HDFS
社区版 HDFS 支持简单认证和 Kerberos 认证两种认证方式(Broker Load 默认使用简单认证),并且支持 NameNode 节点的 HA 配置。如果存储系统为社区版 HDFS,您可以按如下指定认证方式和 HA 配置:
-
认证方式
-
如果使用简单认证,请按如下配置
StorageCredentialParams:"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"StorageCredentialParams包含如下参数。参数名称 参数说明 hadoop.security.authentication 指定认证方式。取值范围: simple和kerberos。默认值:simple。simple表示简单认证,即无认证。kerberos表示 Kerberos 认证。username 用于访问 HDFS 集群中 NameNode 节点的用户名。 password 用于访问 HDFS 集群中 NameNode 节点的密码。 -
如果使用 Kerberos 认证,请按如下配置
StorageCredentialParams:"hadoop.security.authentication" = "kerberos",
"kerberos_principal" = "nn/zelda1@ZELDA.COM",
"kerberos_keytab" = "/keytab/hive.keytab",
"kerberos_keytab_content" = "YWFhYWFh"StorageCredentialParams包含如下参数。参数名称 参数说明 hadoop.security.authentication 指定认证方式。取值范围: simple和kerberos。默认值:simple。simple表示简单认证,即无认证。kerberos表示 Kerberos 认证。kerberos_principal 用于指定 Kerberos 的用户或服务 (Principal)。每个 Principal 在 HDFS 集群内唯一,由如下三部分组成: username或servicename:HDFS 集群中用户或服务的名称。instance:HDFS 集群要认证的节点所在服务器的名称,用来保证用户或服务全局唯一。比如,HDFS 集群中有多个 DataNode 节点,各节点需要各自独立认证。realm:域,必须全大写。
nn/zelda1@ZELDA.COM。kerberos_keytab 用于指定 Kerberos 的 Key Table(简称为“keytab”)文件的路径。 kerberos_keytab_content 用于指定 Kerberos 中 keytab 文件的内容经过 Base64 编码之后的内容。该参数跟 kerberos_keytab参数二选一配置。需要注意的是,在多 Kerberos 用户的场景下,您需要确保至少部署了一组独立的 Broker,并且在导入语句中通过
WITH BROKER "<broker_name>"来指定使用哪组 Broker。另外还需要打开 Broker 进程的启动脚本文件 start_broker.sh,在文件 42 行附近修改如下信息让 Broker 进程读取 krb5.conf 文件信息:export JAVA_OPTS="-Dlog4j2.formatMsgNoLookups=true -Xmx1024m -Dfile.encoding=UTF-8 -Djava.security.krb5.conf=/etc/krb5.conf"说明
- /etc/krb5.conf 文件路径根据实际情况进行修改,Broker 需要有权限读取该文件。部署多个 Broker 时,每个 Broker 节点均需要修改如上信息,然后重启各 Broker 节点使配置生效。
- 您可以通过 SHOW BROKER 语句来查看 StarRocks 集群中已经部署的 Broker。
-
-
HA 配置
可以为 HDFS 集群中的 NameNode 节点配置 HA 机制,从而确保发生 NameNode 节点切换时,StarRocks 能够自动识别新切换到的 NameNode 节点,包括如下几种场景:
-
在单 HDFS 集群、并且配置了单 Kerberos 用户的场景下,可以采用有 Broker 的导入,也可以采用无 Broker 的导入。
-
如果采用有 Broker 的导入,您需要确保至少部署了一组独立的 Broker,并将
hdfs-site.xml文件放在 HDFS 集群对应的 Broker 节点的{deploy}/conf目录下。Broker 进程重启时,会将{deploy}/conf目录添加到CLASSPATH环境变量,使 Broker 能够读取 HDFS 集群中各节点的信息。 -
如果采用无 Broker 的导入,您需要将
hdfs-site.xml文件放在每个 FE 节点和每个 BE 节点的{deploy}/conf目录下。
-
-
在单 HDFS 集群、并且配置了多 Kerberos 用户的场景下,只支持有 Broker 的导入。您需要确保至少部署了一组独立的 Broker,并将
hdfs-site.xml文件放在 HDFS 集群对应的 Broker 节点的{deploy}/conf目录下。Broker 进程重启时,会将{deploy}/conf目录添加到CLASSPATH环境变量,使 Broker 能够读取 HDFS 集群中各节点的信息。 -
在多 HDFS 集群场景下(不管是单 Kerberos 用户、还是多 Kerberos 用户),只支持有 Broker 的导入。您需要确保至少部署了一组独立的 Broker,并且采取如下方法之一来配置 Broker 读取 HDFS 集群中各节点的信息:
-
将
hdfs-site.xml文件放在每个 HDFS 集群对应的 Broker 节点的{deploy}/conf目录下。Broker 进程重启时,会将{deploy}/conf目录添加到CLASSPATH环境变量,使 Broker 能够读取 HDFS 集群中各节点的信息。 -
在创建 Broker Load 作业时增加如下 HA 配置:
"dfs.nameservices" = "ha_cluster",
"dfs.ha.namenodes.ha_cluster" = "ha_n1,ha_n2",
"dfs.namenode.rpc-address.ha_cluster.ha_n1" = "<hdfs_host>:<hdfs_port>",
"dfs.namenode.rpc-address.ha_cluster.ha_n2" = "<hdfs_host>:<hdfs_port>",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"上述配置中的参数说明如下表所述:
参数名称 参数说明 dfs.nameservices 自定义 HDFS 集群的名称。 dfs.ha.namenodes.XXX 自定义 NameNode 的名称,多个名称以逗号 (,) 分隔,双引号内不允许出现空格。
其中xxx为dfs.nameservices中自定义的HDFS 服务的名称。dfs.namenode.rpc-address.XXX.NN 指定 NameNode 的 RPC 地址信息。
其中NN表示dfs.ha.namenodes.XXX中自定义 NameNode 的名称。dfs.client.failover.proxy.provider 指定客户端连接的 NameNode 的提供者,默认为 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider。
-
说明
您可以通过 SHOW BROKER 语句来查看 StarRocks 集群中已经部署的 Broker。
-
AWS S3
如果存储系统为 AWS S3,请按如下配置 StorageCredentialParams:
-
基于 Instance Profile 进行认证和鉴权
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
基于 Assumed Role 进行认证和鉴权
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
基于 IAM User 进行认证和鉴权
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
StorageCredentialParams 包含如下参数。
| 参数 | 是否必须 | 说明 |
|---|---|---|
| aws.s3.use_instance_profile | 是 | 指定是否开启 Instance Profile 和 Assumed Role 两种鉴权方式。取值范围:true 和 false。默认值:false。 |
| aws.s3.iam_role_arn | 否 | 有权限访问 AWS S3 Bucket 的 IAM Role 的 ARN。采用 Assumed Role 鉴权方式访问 AWS S3 时,必须指定此参数。这样,StarRocks 在使用 Hive Catalog 访问 Hive 数据时将会担任该 IAM Role。 |
| aws.s3.region | 是 | AWS S3 Bucket 所在的地域。示例:us-west-1。 |
| aws.s3.access_key | 否 | IAM User 的 Access Key。采用 IAM User 鉴权方式访问 AWS S3 时,必须指定此参数。这样,StarRocks 在使用 Hive Catalog 访问 Hive 数据时将会担任该 IAM Role。 |
| aws.s3.secret_key | 否 | IAM User 的 Secret Key。采用 IAM User 鉴权方式访问 AWS S3 时,必须指定此参数。这样,StarRocks 在使用 Hive Catalog 访问 Hive 数据时将会担任该 IAM Role。 |
有关如何选择用于访问 AWS S3 的鉴权方式、以及如何在 AWS IAM 控制台配置访��问控制策略,参见访问 AWS S3 的认证参数。
Google GCS
如果存储系统为 Google GCS,请按如下配置 StorageCredentialParams:
"fs.s3a.access.key" = "<gcs_access_key>",
"fs.s3a.secret.key" = "<gcs_secret_key>",
"fs.s3a.endpoint" = "<gcs_endpoint>"
StorageCredentialParams 包含如下参数。
| 参数名称 | 参数说明 |
|---|---|
| fs.s3a.access.key | 访问 Google GCS 存储空间的 Access Key。 |
| fs.s3a.secret.key | 访问 Google GCS 存储空间的 Secret Key。 |
| fs.s3a.endpoint | 访问 Google GCS 存储空间的连接地址。 |
说明
由于 Broker Load 只支持通过 S3A 协议访问 Google GCS,因此当从 Google GCS 导入数据时,
DATA INFILE中传入的目标文件的 GCS URI,前缀必须修改为s3a://。
创建访问 Google GCS 存储空间的密钥对的操作步骤如下:
-
登录 Google GCP。
-
在左侧导航栏,选择 Google Cloud Storage,然后选择 Settings。
-
选择 Interoperability 页签。
如果还没有启用 Interoperability 特性,请单击 Interoperable Access。
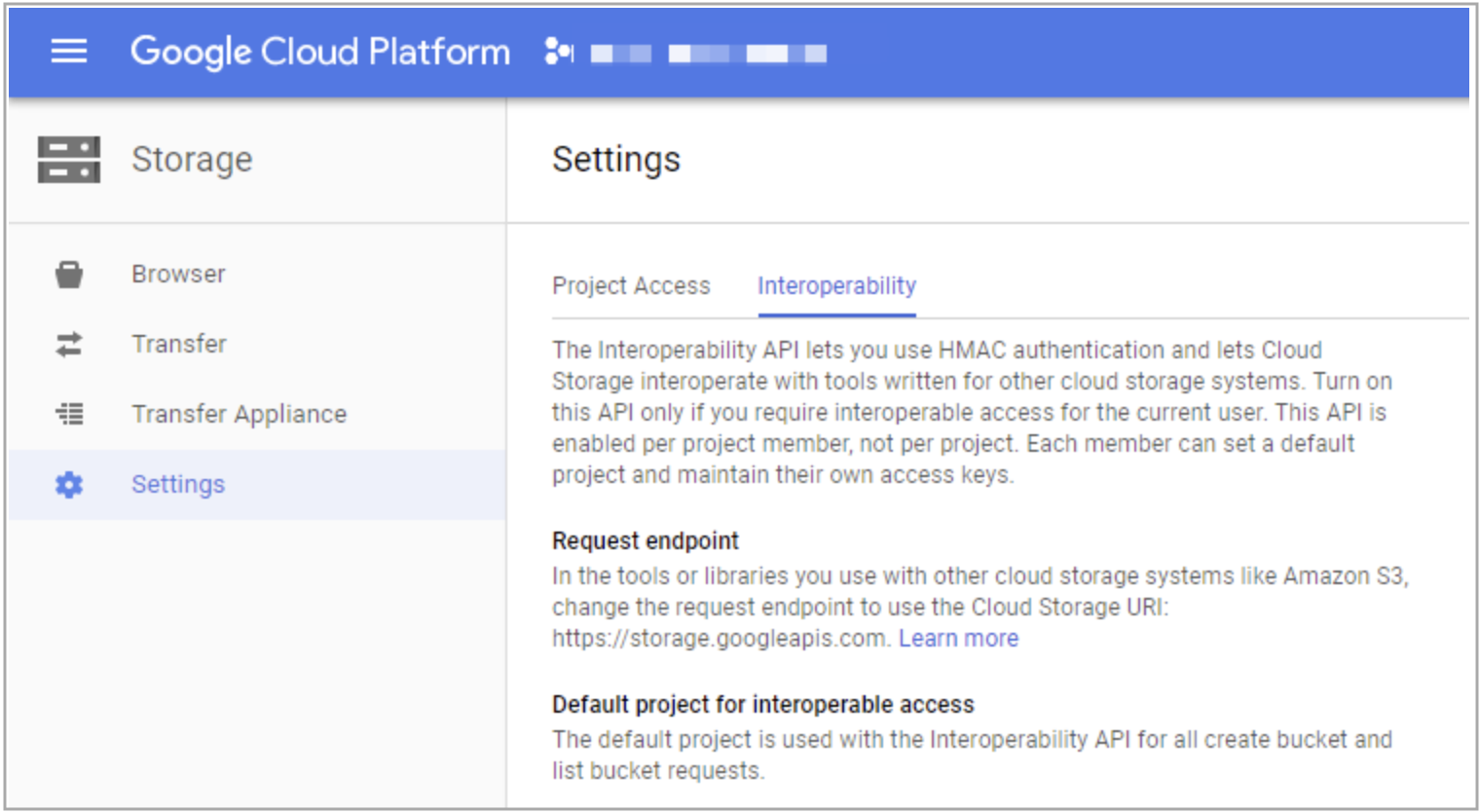
-
单击 Create new Key 按钮,按界面提示完成密钥对的创建。
阿里云 OSS
如果存储系统为阿里云 OSS,请按如下配置 StorageCredentialParams:
"fs.oss.accessKeyId" = "<oss_access_key>",
"fs.oss.accessKeySecret" = "<oss_secret_key>",
"fs.oss.endpoint" = "<oss_endpoint>"
StorageCredentialParams 包含如下参数。
| 参数名称 | 参数说明 |
|---|---|
| fs.oss.accessKeyId | 访问阿里云 OSS 存储空间的 AccessKey ID,用于标识用户。 |
| fs.oss.accessKeySecret | 访问阿里云 OSS 存储空间的 AccessKey Secret,是用于加密签名字符串和 OSS 用来验证签名字符串的密钥。 |
| fs.oss.endpoint | 访问阿里云 OSS 存储空间的连接地址。 |
请参见阿里云官方文档用户签名验证。
腾讯云 COS
如果存储系统为腾讯云 COS,请按如下配置 StorageCredentialParams:
"fs.cosn.userinfo.secretId" = "<cos_access_key>",
"fs.cosn.userinfo.secretKey" = "<cos_secret_key>",
"fs.cosn.bucket.endpoint_suffix" = "<cos_endpoint>"
StorageCredentialParams 包含如下参数。
| 参数名称 | 参数说明 |
|---|---|
| fs.cosn.userinfo.secretId | 访问腾讯云 COS 存储空间的 SecretId,用于标识 API 调用者的身份。 |
| fs.cosn.userinfo.secretKey | 访问腾讯云 COS 存储空间的 SecretKey,是用于加密签名字符串和服务端验证签名字符串的密钥。 |
| fs.cosn.bucket.endpoint_suffix | 访问腾讯云 COS 存储空间的连接地址。 |
请参见腾讯云官方文档使用永久密钥访问 COS。
华为云 OBS
如果存储系统为华为云 OBS,请按如下配置 StorageCredentialParams:
"fs.obs.access.key" = "<obs_access_key>",
"fs.obs.secret.key" = "<obs_secret_key>",
"fs.obs.endpoint" = "<obs_endpoint>"
StorageCredentialParams 包含如下参数。
| 参数名称 | 参数说明 |
|---|---|
| fs.obs.access.key | 访问华为云 OBS 存储空间的 Access Key ID,与私有访问密钥关联的唯一标识符。 |
| fs.obs.secret.key | 访问华为云 OBS 存储空间的 Secret Access Key,对请求进行加密签名,可标识发送方,并防止请求被修改。 |
| fs.obs.endpoint | 访问华为云 OBS 存储空间的连接地址。 |
请参见华为云官方文档通过永久访问密钥访问 OBS。
说明
使用 Broker Load 从华为云 OBS 导入数据时,需要先下载依赖库添加到 $BROKER_HOME/lib/ 路径下并重启 Broker。
其他兼容 S3 协议的对象存储
如果存储系统为其他兼容 S3 协议的对象存储(如 MinIO),请按如下配置 StorageCredentialParams:
"aws.s3.enable_ssl" = "{true | false}",
"aws.s3.enable_path_style_access" = "{true | false}",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
StorageCredentialParams 包含如下参数。
| 参数 | 是否必须 | 描述 |
|---|---|---|
| aws.s3.enable_ssl | 是 | 是否开启 SSL 连接。取值范围:true 和 false。默认值:true。 |
| aws.s3.enable_path_style_access | 是 | 是否开启路径类型 URL 访问 (Path-Style URL Access)。取值范围:true 和 false。默认值:false。 |
| aws.s3.endpoint | 是 | 用于访问 AWS S3 Bucket 的 Endpoint。 |
| aws.s3.access_key | 是 | IAM User 的 Access Key。 |
| aws.s3.secret_key | 是 | IAM User 的 Secret Key。 |
opt_properties
用于指定一些导入相关的可选参数,指定的参数设置作用于整个导入作业。语法如下:
PROPERTIES ("<key1>" = "<value1>"[, "<key2>" = "<value2>" ...])
参数说明如下:
-
timeout导入作业的超时时间。单位:秒。默认超时时间为 4 小时。建议超时时间小于 6 小时。如果导入作业在设定的时限内未完成,会自动取消,变成 CANCELLED 状态。
说明
通常情况下,您不需要手动设置导入作业的超时时间。只有当导入作业无法在默认的超时时间内完成时,才推荐您手动设置导入作业的超时时间。
推荐超时时间大于下面公式的计算值:
超时时间 > (源数据文件的总大小 x 源数据文件及相关物化视图的个数)/(平均导入速度 x 导入并发数)
说明
-
“平均导入速度”是指目前 StarRocks 集群的平均导入速度。由于每个 StarRocks 集群的机器环境不同、且集群允许的并发查询任务数也不同,因此,StarRocks 集群的平均导入速度需要根据历史导入速度进行推测。
-
“导入并发数”可以通过
max_broker_concurrency参数设置,具体请参见“从 HDFS 或外部云存储系统导入数据”文档中的“作业拆分与并行执行”章节。
例如,要导入一个 1 GB 的数据文件��,该数据文件包含 2 个物化视图,当前 StarRocks 集群的平均导入速度为 10 MB/s,导入并发数为 3。在这种情况下,根据公式计算出来时长为 102 秒:
(1 x 1024 x 3)/(10 x 3) = 102(秒)
因此,导入作业的超时时间应该大于 102 秒。
-
-
max_filter_ratio导入作业的最大容忍率,即导入作业能够容忍的因数据质量不合格而过滤掉的数据行所占的最大比例。取值范围:
0~1。默认值:0。- 如果设置最大容忍率为
0,则 StarRocks 在导入过程中不会忽略错误的数据行。当导入的数据行中有错误时,导入作业会失败,从而保证数据的正确性。 - 如果设置最大容忍率大于
0,则 StarRocks 在导入过程中会忽略错误的数据行。这样,即使导入的数据行中有错误,导入作业也能成功。说明
这里因数据质量不合格而过滤掉的数据行,不包括通过 WHERE 子句过滤掉的数据行。
如果因为设置最大容忍率为
0而导致作业失败,可以通过 SHOW LOAD 语句来查看导入作业的结果信息。然后,判断错误的数据行是否可以被过滤掉。如果可以被过滤掉,则可以根据结果信息中的dpp.abnorm.ALL和dpp.norm.ALL来计算导入作业的最大容忍率,然后调整后重新提交导入作业。计算公式如下:max_filter_ratio= [dpp.abnorm.ALL/(dpp.abnorm.ALL+dpp.norm.ALL)]dpp.abnorm.ALL和dpp.norm.ALL的总和就等于待导入的总行数。 - 如果设置最大容忍率为
-
load_mem_limit导入作业的内��存限制,最大不超过 BE 的内存限制。单位:字节。默认内存限制为 2 GB。
-
strict_mode是否开启严格模式。取值范围:
true和false。默认值:false。true表示开启,false表示关闭。
关于该模式的介绍,参见严格模式。 -
timezone指定导入作业所使用的时区。默认为
Asia/Shanghai时区。该参数会影响所有导入涉及的、跟时区设置有关的函数所返回的结果。受时区影响的函数有 strftime、alignment_timestamp 和 from_unixtime 等,具体请参见设置时区。导入参数timezone设置的时区对应“设置时区”中所述的会话级时区。 -
priority指定导入作业的优先级。取值范围:
LOWEST、LOW、NORMAL、HIGH和HIGHEST。默认值:NORMAL。Broker Load 通过 FE 配置项max_broker_load_job_concurrency指定 StarRocks 集群中可以并行执行的 Broker Load 作业的最大数量。如果某一时间段内提交的 Broker Load 作业总数超过最大数量,则超出的作业会按照优先级在队列中排队等待调度。已经创建成功的导入作业,如果处于 QUEUEING 状态或者 LOADING 状态,那么您可以使用 ALTER LOAD 语句修改该作业的优先级。
StarRocks 自 v2.5 版本起支持为导入作业设置
priority参数。
列映射
如果源数据文件中的列与目标表中的列按顺序一一对应,您不需要指定列映射和转换关系。
如果源数据文件中的列与目标表中的列不能按顺序一一对应,包括数量或顺序不一致,则必须通过 COLUMNS 参数来指定列映射和转换关系。一般包括如下两种场景:
-
列数量一致、但是顺序不一致,并且数据不需要通过函数计算、可以直接落入目标表中对应的列。 这种场景下,您需要在
COLUMNS参数中按照源数据文件中的列顺序、使用目标表中对应的列名来配置列映射和转换关系。例如,目标表中有三列,按顺序依次为
col1、col2和col3;源数据文件中也有三列,按顺序依次对应目标表中的col3、col2和col1。这种情况下,需要指定COLUMNS(col3, col2, col1)。 -
列数量、顺序都不一致,并且某些列的数据需要通过函数计算以后才能落入目标表中对应的列。 这种场景下,您不仅需要在
COLUMNS参数中按照源数据文件中的列顺序、使用目标表中对应的列名来配置列映射关系,还需要指定参与数据计算的函数。以下为两个示例:- 目标表中有三列,按顺序依次为
col1、col2和col3;源数据文件中有四列,前三列按顺序依次对应目标表中的col1、col2和col3,第四列在目标表中无对应的列。这种情况下,需要指定COLUMNS(col1, col2, col3, temp),其中,最后一列可随意指定一个名称(如temp)用于占位即可。 - 目标表中有三列,按顺序依次为
year、month和day。源数据文件中只有一个包含时间数据的列,格式为yyyy-mm-dd hh:mm:ss。这种情况下,可以指定COLUMNS (col, year = year(col), month=month(col), day=day(col))。其中,col是源数据文件中所包含的列的临时命名,year = year(col)、month=month(col)和day=day(col)用于指定从col列提取对应的数据并落入目标表中对应的列,如year = year(col)表示通过year函数提取源数据文件中col列的yyyy部分的数据并落入目标表中的year列。
- 目标表中有三列,按顺序依次为
有关操作示例,参见设置列映射关系。
示例
本文以 HDFS 数据源为例,介绍各种导入配置。
导入 CSV 格式的数据
本小节以 CSV 格式的数据为例,重点阐述在创建导入作业的时候,如何运用各种参数配置来满足不同业务场景下的各种导入要求。
设置超时时间
StarRocks 数据库 test_db 里的表 table1 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example1.csv 也包含三列,按顺序一一对应 table1 中的三列。
如果要把 example1.csv 中所有的数据都导入到 table1 中,并且要求超时时间最大不超过 3600 秒,可以执行如下语句:
LOAD LABEL test_db.label1
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example1.csv")
INTO TABLE table1
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
PROPERTIES
(
"timeout" = "3600"
);
设置最大容错率
StarRocks 数据库 test_db 里的表 table2 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example2.csv 也包含三列,按顺序一一对应 table2 中的三列。
如果要把 example2.csv 中所有的数据都导入到 table2 中,并且要求容错率最大不超过 0.1,可以执行如下语句:
LOAD LABEL test_db.label2
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example2.csv")
INTO TABLE table2
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
PROPERTIES
(
"max_filter_ratio" = "0.1"
);
导入指定路径下所有数据文件
StarRocks 数据库 test_db 里的表 table3 包含三列,按顺序依次为 col1、col2、col3。
HDFS 集群的 /user/starrocks/data/input/ 路径下所有数据文件也包含三列,按顺序一一对应 table3 中的三列,并且列分隔符为 Hive 文件的默认列分隔符 \x01。
如果要把 hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/ 路径下所有数据文件的数据都导入到 table3 中,可以执行如下语句:
LOAD LABEL test_db.label3
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/*")
INTO TABLE table3
COLUMNS TERMINATED BY "\\x01"
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
设置 NameNode HA 机制
StarRocks 数据库 test_db 里的表 table4 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example4.csv 也包含三列,按顺序一一对应 table4 中的三列。
如果要把 example4.csv 中所有的数据都导入到 table4 中,并且要求使用 NameNode HA 机制,可以执行如下语句:
LOAD LABEL test_db.label4
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example4.csv")
INTO TABLE table4
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
设置 Kerberos 认证方式
StarRocks 数据库 test_db 里的表 table5 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example5.csv 也包含三列,按顺序一一对应 table5 中的三列。
如果要把 example5.csv 中所有的数据都导入到 table5 中,并且要求使用 Kerberos 认证方式、提供 keytab 文件的路径,可以执行如下语句:
LOAD LABEL test_db.label5
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example5.csv")
INTO TABLE table5
COLUMNS TERMINATED BY "\t"
)
WITH BROKER
(
"hadoop.security.authentication" = "kerberos",
"kerberos_principal" = "starrocks@YOUR.COM",
"kerberos_keytab" = "/home/starRocks/starRocks.keytab"
);
撤销已导入的数据
StarRocks 数据库 test_db 里的表 table6 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example6.csv 也包含三列,按顺序一一对应 table6 中的三列。
并且,您已经通过 Broker Load 把 example6.csv 中所有的数据都导入到了 table6 中。
如果您想撤销已导入的数据,可以执行如下语句:
LOAD LABEL test_db.label6
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example6.csv")
NEGATIVE
INTO TABLE table6
COLUMNS TERMINATED BY "\t"
)
WITH BROKER
(
"hadoop.security.authentication" = "kerberos",
"kerberos_principal" = "starrocks@YOUR.COM",
"kerberos_keytab" = "/home/starRocks/starRocks.keytab"
);
设置目标分区
StarRocks 数据库 test_db 里的表 table7 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example7.csv 也包含三列,按顺序一一对应 table7 中的三列。
如果要把 example7.csv 中所有的数据都导入到 table7 所在的分区 p1 和 p2,可以执行如下语句:
LOAD LABEL test_db.label7
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example7.csv")
INTO TABLE table7
PARTITION (p1, p2)
COLUMNS TERMINATED BY ","
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
设置列映射关系
StarRocks 数据库 test_db 里的表 table8 包含三列,按顺序依次为 col1、col2、col3。
数�据文件 example8.csv 也包含三列,按顺序依次对应 table8 中 col2、col1、col3。
如果要把 example8.csv 中所有的数据都导入到 table8 中,可以执行如下语句:
LOAD LABEL test_db.label8
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example8.csv")
INTO TABLE table8
COLUMNS TERMINATED BY ","
(col2, col1, col3)
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
说明
上述示例中,因为
example8.csv和table8所包含的列不能按顺序依次对应,因此需要通过column_list参数来设置example8.csv和table8之间的列映射关系。
设置筛选条件
StarRocks 数据库 test_db 里的表 table9 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example9.csv 也包含三列,按顺序一一对应 table9 中的三列。
如果只想把 example9.csv 中第一列的值大于 20180601 的数据行导入到 table9 中,可以执行如下语句:
LOAD LABEL test_db.label9
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example9.csv")
INTO TABLE table9
(col1, col2, col3)
where col1 > 20180601
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
说明
上述示例中,虽然
example9.csv和table9所包含的列数目相同、并且按顺序一一对应,但是因为需要通过 WHERE 子句指定基于列的过滤条件,因此需要通过column_list参数对example9.csv中的列进行临时命名。
导入数据到含有 HLL 类型列的表
StarRocks 数据库 test_db 里的表 table10 包含四列,按顺序依次为 id、col1、col2、col3,其中 col1 和 col2 是 HLL 类型的列。
数据文件 example10.csv 包含三列,第一列对应 table10 中的 id 列;第二列和第三列分别对应 table10 中 HLL 类型的列 col1 和 col2,可以通过函数转换成 HLL 类型的数据并分别落入 col1、col2 列。
如果要把 example10.csv 中所有的数据都导入到 table10 中,可以执行如下语句:
LOAD LABEL test_db.label10
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example10.csv")
INTO TABLE table10
COLUMNS TERMINATED BY ","
(id, temp1, temp2)
SET
(
col1 = hll_hash(temp1),
col2 = hll_hash(temp2),
col3 = empty_hll()
)
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
说明
上述示例中,通过
column_list参数,把example10.csv中的三列按顺序依次临时命名为id、temp1、temp2,然后使用函数指定数据转换规则,包括:
使用
hll_hash函数把example10.csv中的temp1、temp2列转换成 HLL 类型的数据,并分别落入table10中的col1、col2列。使用
hll_empty函数给导入的数据行在table10中的第四列补充默认值。
有关 hll_hash 函数和 hll_empty 函数的用法,请参见 hll_hash和hll_empty。
提取文件路径中的分区字段
Broker Load 支持根据 StarRocks 表中定义的字段类型来解析待导入文件路径中的分区字段,类似 Apache Spark™ 中的分区发现 (Partition Discovery) 功能。
StarRocks 数据库 test_db 里的表 table11 包含五列,按顺序依次为 col1、col2、col3、city、utc_date。
HDFS 集群的 /user/starrocks/data/input/dir/city=beijing 路径下包含如下数据文件:
-
/user/starrocks/data/input/dir/city=beijing/utc_date=2019-06-26/0000.csv -
/user/starrocks/data/input/dir/city=beijing/utc_date=2019-06-26/0001.csv
这些数据文件都包含三列,按顺序分别对应 table11 中 col1、col2、col3 三列。
如果要把 /user/starrocks/data/input/dir/city=beijing/utc_date=*/* 路径下所有数据文件的数据都导入到 table11 中,并且要求提取路径中分区字段 city 和 utc_date 的信息落入 table11 中对应的 city、utc_date 列,可以执行如下语句:
LOAD LABEL test_db.label11
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/dir/city=beijing/*/*")
INTO TABLE table11
FORMAT AS "csv"
(col1, col2, col3)
COLUMNS FROM PATH AS (city, utc_date)
SET (uniq_id = md5sum(k1, city))
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
提取文件路径中包含 %3A 的时间分区字段
在 HDFS 的文件路径中,不允许有冒号 (:),所有冒号 (:) 都会自动替换成 %3A。
StarRocks 数据�库 test_db 里的表 table12 包含三列,按顺序依次为 data_time、col1、col2,表结构如下:
data_time DATETIME,
col1 INT,
col2 INT
HDFS 集群的 /user/starrocks/data 路径下有如下数据文件:
-
/user/starrocks/data/data_time=2020-02-17 00%3A00%3A00/example12.csv -
/user/starrocks/data/data_time=2020-02-18 00%3A00%3A00/example12.csv
如果要把 example12.csv 中所有的数据都导入到 table12 中,并且要求提取指定路径中分区字段 data_time 的信息落入到 table12 中的 data_time 列,可以执行如下语句:
LOAD LABEL test_db.label12
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/*/example12.csv")
INTO TABLE table12
COLUMNS TERMINATED BY ","
FORMAT AS "csv"
(col1,col2)
COLUMNS FROM PATH AS (data_time)
SET (data_time = str_to_date(data_time, '%Y-%m-%d %H%%3A%i%%3A%s'))
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
上述示例中,因为直接提取后的分区字段 data_time 是包含 %3A 的字符串(如 2020-02-17 00%3A00%3A00),因此需要再通过 str_to_date 函数把字符串转换为 DATETIME 类型的数据以后才能落入 table8 中的 data_time 列。
导入 Parquet 格式的数据
本小节主要描述导入 Parquet 格式的数据时,需要关注的一些参数配置。
StarRocks 数据库 test_db 里的表 table13 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example13.parquet 也包含三列,按顺序一一对应 table13 中的三列。
如果要把 example13.parquet 中所有的数据都导入到 table13 中,可以执行如下语句:
LOAD LABEL test_db.label13
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example13.parquet")
INTO TABLE table13
FORMAT AS "parquet"
(col1, col2, col3)
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
说明
导入 Parquet 格式的数据时,默认通过文件扩展名 (.parquet) 判断数据文件的格式。如果文件名称中没有包含扩展名,则必须通过
FORMAT AS参数指定数据文件格式为Parquet。
导入 ORC 格式的数据
本小节主要描述导入 ORC 格式的数据时,需要关注的一些参数配置。
StarRocks 数据库 test_db 里的表 table14 包含三列,按顺序依次为 col1、col2、col3。
数据文件 example14.orc 也包含三列,按顺序一一对应 table14 中的三列。
如果要把 example14.orc 中所有的数据都导入到 table14 中,可以执行如下语句:
LOAD LABEL test_db.label14
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/data/input/example14.orc")
INTO TABLE table14
FORMAT AS "orc"
(col1, col2, col3)
)
WITH BROKER
(
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
说明
导入 ORC 格式的数据时,默认通过文件扩展名 (.orc) 判断数据文件的格式。如果文件名称中没有包含扩展名,则必须通过
FORMAT AS参数指定数据文件格式为ORC。StarRocks v2.3 及之前版本,当数据文件中包含 ARRAY 类型的列时,必须确保数据文件和 StarRocks 表中对应的列同名,并且不能写在 SET 子句里。