Load data from HDFS
StarRocks allows you to load data in bulk from HDFS by using Broker Load.
Broker Load runs in asynchronous mode. An asynchronous Broker Load process handles making the connection to GCS, pulling the data, and storing the data in StarRocks.
Broker Load supports the Parquet, ORC, and CSV file formats.
Advantages of Broker Load
- Broker Load runs in the background and clients do not need to stay connected for the job to continue.
- Broker Load is preferred for long-running jobs, with the default timeout spanning 4 hours.
- In addition to Parquet and ORC file formats, Broker Load supports CSV files.
Data flow
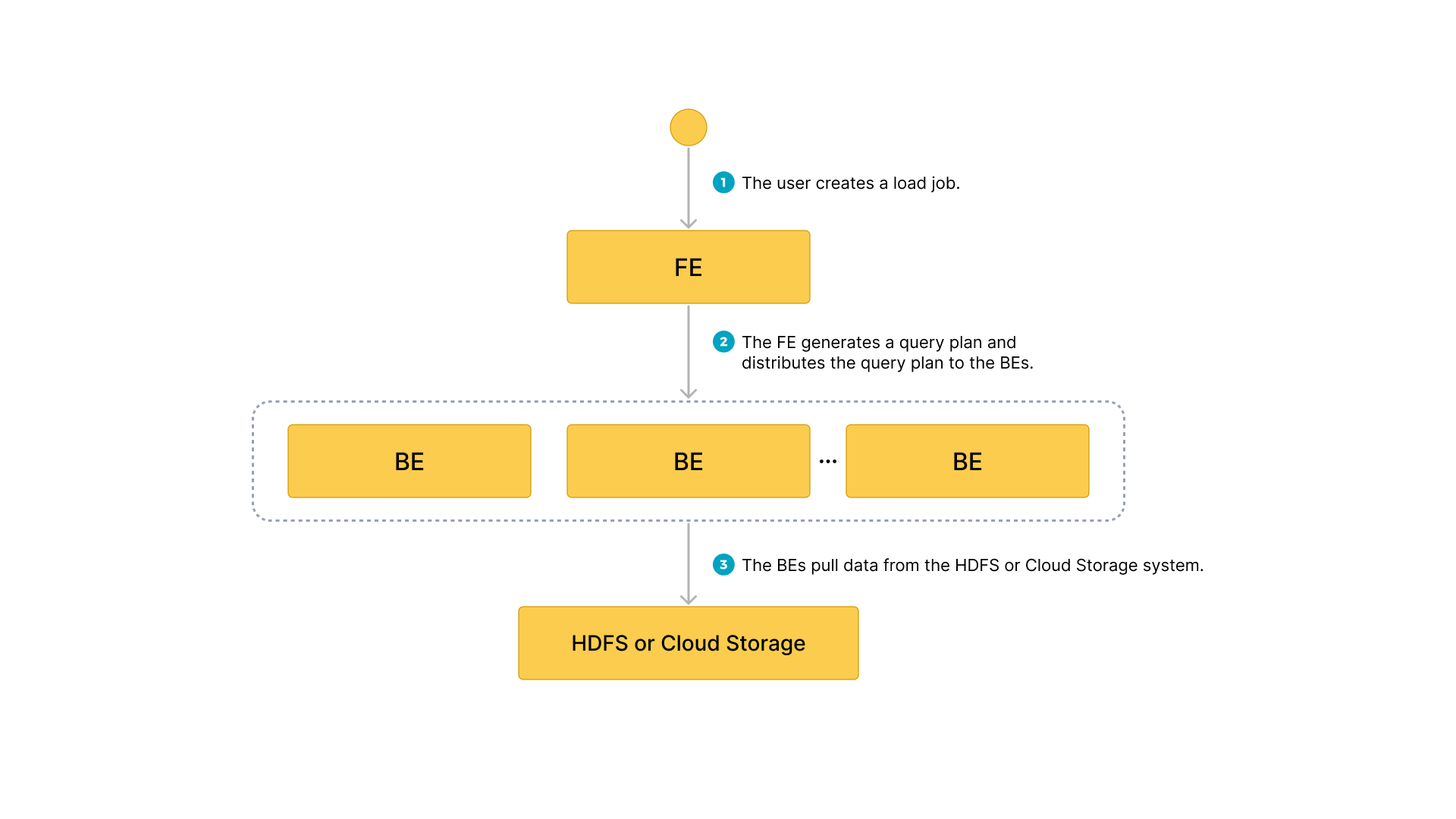
- The user creates a load job.
- The frontend (FE) creates a query plan and distributes the plan to the backend nodes (BEs) or compute nodes (CNs).
- The BEs or CNs pull the data from the source and load the data into StarRocks.
Before you begin
Make source data ready
Make sure the source data you want to load into StarRocks is properly stored in your HDFS cluster. This topic assumes that you want to load /user/amber/user_behavior_ten_million_rows.parquet from HDFS into StarRocks.
Check privileges
You can load data into StarRocks tables only as a user who has the INSERT privilege on those StarRocks tables. If you do not have the INSERT privilege, follow the instructions provided in GRANT to grant the INSERT privilege to the user that you use to connect to your StarRocks cluster.
Gather authentication details
You can use the simple authentication method to establish connections with your HDFS cluster. To use simple authentication, you need to gather the username and password of the account that you can use to access the NameNode of the HDFS cluster.
Typical example
Create a table, start a load process that pulls the data file /user/amber/user_behavior_ten_million_rows.parquet from HDFS, and verify the progress and success of the data loading.
Create a database and a table
Create a database and switch to it:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Create a table by hand (we recommend that the table has the same schema as the Parquet file that you want to load from HDFS):
CREATE TABLE user_behavior
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp datetime
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
Start a Broker Load
Run the following command to start a Broker Load job that loads data from the data file /user/amber/user_behavior_ten_million_rows.parquet to the user_behavior table:
LOAD LABEL user_behavior
(
DATA INFILE("hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
PROPERTIES
(
"timeout" = "72000"
);
This job has four main sections:
LABEL: A string used when querying the state of the load job.LOADdeclaration: The source URI, source data format, and destination table name.BROKER: The connection details for the source.PROPERTIES: The timeout value and any other properties to apply to the load job.
For detailed syntax and parameter descriptions, see BROKER LOAD.
Check load progress
You can query the progress of Broker Load jobs from the information_schema.loads view. This feature is supported from v3.1 onwards.
SELECT * FROM information_schema.loads;
For information about the fields provided in the loads view, see Information Schema.
If you have submitted multiple load jobs, you can filter on the LABEL associated with the job. Example:
SELECT * FROM information_schema.loads WHERE LABEL = 'user_behavior';
In the output below there are two entries for the load job user_behavior:
- The first record shows a state of
CANCELLED. Scroll toERROR_MSG, and you can see that the job has failed due tolistPath failed. - The second record shows a state of
FINISHED, which means that the job has succeeded.
JOB_ID|LABEL |DATABASE_NAME|STATE |PROGRESS |TYPE |PRIORITY|SCAN_ROWS|FILTERED_ROWS|UNSELECTED_ROWS|SINK_ROWS|ETL_INFO|TASK_INFO |CREATE_TIME |ETL_START_TIME |ETL_FINISH_TIME |LOAD_START_TIME |LOAD_FINISH_TIME |JOB_DETAILS |ERROR_MSG |TRACKING_URL|TRACKING_SQL|REJECTED_RECORD_PATH|
------+-------------------------------------------+-------------+---------+-------------------+------+--------+---------+-------------+---------------+---------+--------+----------------------------------------------------+-------------------+-------------------+-------------------+-------------------+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+------------+------------+--------------------+
10121|user_behavior |mydatabase |CANCELLED|ETL:N/A; LOAD:N/A |BROKER|NORMAL | 0| 0| 0| 0| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:59:30| | | |2023-08-10 14:59:34|{"All backends":{},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":0,"InternalTableLoadRows":0,"ScanBytes":0,"ScanRows":0,"TaskNumber":0,"Unfinished backends":{}} |type:ETL_RUN_FAIL; msg:listPath failed| | | |
10106|user_behavior |mydatabase |FINISHED |ETL:100%; LOAD:100%|BROKER|NORMAL | 86953525| 0| 0| 86953525| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:50:15|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:55:10|{"All backends":{"a5fe5e1d-d7d0-4826-ba99-c7348f9a5f2f":[10004]},"FileNumber":1,"FileSize":1225637388,"InternalTableLoadBytes":2710603082,"InternalTableLoadRows":86953525,"ScanBytes":1225637388,"ScanRows":86953525,"TaskNumber":1,"Unfinished backends":{"a5| | | | |
After you confirm that the load job has finished, you can check a subset of the destination table to see if the data has been successfully loaded. Example:
SELECT * from user_behavior LIMIT 3;
The following query result is returned, indicating that the data has been successfully loaded:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+