从 MySQL 实时同步
StarRocks 支持多种方式将 MySQL 的数据实时同步至 StarRocks,支撑实时分析和处理海量数据的需求。
本文介绍如何将 MySQL 的数据通过 Apache Flink® 实时(秒级)同步至 StarRocks。
注意
导入操作需要目标表的 INSERT 权限。如果您的用户账号没有 INSERT 权限,请参考 GRANT 给用户赋权。
基本原理
从 MySQL 同步至 Flink 需要使用 Flink CDC,本文使用 Flink CDC 的版本小于 3.0,因此需要借助 SMT 同步表结构。 然而如果使用 Flink CDC 3.0,则无需借助 SMT,即可将表结构同步至 StarRocks,甚至可以同步整个 MySQL 数据库、分库分表的结构,同时也支持同步 schema change。具体的使用方式,参见从 MySQL 到 StarRocks 的流式 ELT 管道。
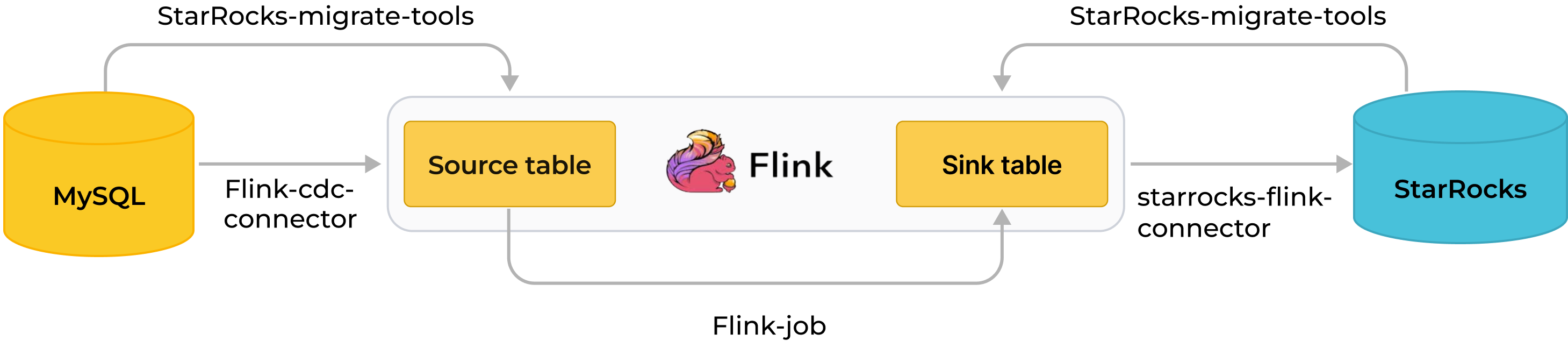
将 MySQL 的数据通过 Flink 同步至 StarRocks 分成同步库表结构、同步数据两个阶段进行。首先 StarRocks Migration Tool (数据迁移工具,以下简称 SMT) 将 MySQL 的库表结构转化成 StarRocks 的建库和建表语句。然后 Flink 集群运行 Flink job,同步 MySQL 全量及增量数据至 StarRocks。具体同步流程如下:
该同步流程能够保证端到端的 exactly-once 的语义一致性。
-
同步库表结构
SMT 根据其配置文件中源 MySQL 和目标 StarRocks 的信息,读取 MySQL 中待同步的库表结构,并生成 SQL 文件,用于在 StarRocks 内创建对应的目标库表。
-
同步数据
Flink SQL 客户端执行导入数据的 SQL 语句(
INSERT INTO SELECT语句),向 Flink 集群提交一个或者多个长时间运行的 Flink job。Flink集群运行 Flink job ,Flink cdc connector 先读取数据库的历史全量数据,然后无缝切换到增量读取,并且发给 flink-connector-starrocks,最后 flink-connector-starrocks 攒微批数据同步至 StarRocks。信息仅支持同步 DML,不支持同步 DDL。
业务场景
以商品累计销量实时榜单为例,存储在 MySQL 中的原始订单表,通过 Flink 处理计算出产品销量的实时排行,并实时同步至 StarRocks 的主键表中。最终用户可以通过可视化工具连接StarRocks查看到实时刷新的榜单。
准备工作
下载并安装同步工具
同步时需要使用 SMT、 Flink、Flink CDC connector、flink-connector-starrocks,下载和安装步骤如下:
-
下载、安装并启动 Flink 集群。
说明:下载和安装方式也可以参考 Flink 官方文档。
-
您需要提前在操作系统中安装 Java 8 或者 Java 11,以正常运行 Flink。您可以通过以下命令来检查已经安装的 Java 版本。
# 查看java版本
java -version
# 如下显示已经安装 java 8
openjdk version "1.8.0_322"
OpenJDK Runtime Environment (Temurin)(build 1.8.0_322-b06)
OpenJDK 64-Bit Server VM (Temurin)(build 25.322-b06, mixed mode) -
下载并解压 Flink。本示例使用 Flink 1.14.5。
说明:推荐使用 1.14 及以上版本,最低支持 1.11 版本。
# 下载 Flink
wget https://archive.apache.org/dist/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.11.tgz
# 解压 Flink
tar -xzf flink-1.14.5-bin-scala_2.11.tgz
# 进入 Flink 目录
cd flink-1.14.5 -
启动 Flink 集群。
# 启动 Flink 集群
./bin/start-cluster.sh
# 返回如下信息,表示成功启动 flink 集群
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
-
-
下载 Flink CDC connector。本示例的数据源为 MySQL,因此下载 flink-sql-connector-mysql-cdc-x.x.x.jar。并且版本需支持对应的 Flink 版本。由于本文使用 Flink 1.14.5,因此可以使用 flink-sql-connector-mysql-cdc-2.2.0.jar。
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.0/flink-sql-connector-mysql-cdc-2.2.0.jar -
下载 flink-connector-starrocks,并且其版本需要对应 Flink 的版本。
flink-connector-starrocks 的 JAR 包 (x.x.x_flink-y.yy_z.zz.jar) 会包含三个版本号:
-
第一个版本号 x.x.x 为 flink-connector-starrocks 的版本号。
-
第二个版本号 y.yy 为其支持的 Flink 版本号。
-
第三个版本号 z.zz 为 Flink 支持的 Scala 版本号。如果 Flink 为 1.14.x 以及之前版本,则需要下载带有 Scala 版本号的 flink-connector-starrocks。
由于本文使用 Flink 版本号 1.14.5,Scala 版本号 2.11,因此可以下载 flink-connector-starrocks JAR 包 1.2.3_flink-1.14_2.11.jar。
-
-
将 Flink CDC connector、Flink-connector-starrocks 的 JAR 包 flink-sql-connector-mysql-cdc-2.2.0.jar、1.2.3_flink-1.14_2.11.jar 移动至 Flink 的 lib 目录。
注意
如果 Flink 已经处于运行状态中,则需要先停止 Flink,然后重启 Flink ,以加载并生效 JAR 包。
./bin/stop-cluster.sh
./bin/start-cluster.sh -
下载并解压 SMT,并将其放在 flink-1.14.5 目录下。您可以根据操作系统和 CPU 架构选择对应的 SMT 安装包。
# 适用于 Linux x86
wget https://releases.starrocks.io/resources/smt.tar.gz
# 适用于 macOS ARM64
wget https://releases.starrocks.io/resources/smt_darwin_arm64.tar.gz
开启 MySQL Binlog 日志
您需要确保已经开启 MySQL Binlog 日志,实时同步时需要读取 MySQL Binlog 日志数据,解析并同步至 StarRocks。
-
编辑 MySQL 配置文件 my.cnf(默认路径为 /etc/my.cnf),以开启 MySQL Binlog。
# 开启 Binlog 日志
log_bin = ON
# 设置 Binlog 的存储位置
log_bin =/var/lib/mysql/mysql-bin
# 设置 server_id
# 在 MySQL 5.7.3 及以后版本,如果没有 server_id,那么设置 binlog 后无法开启 MySQL 服务
server_id = 1
# 设置 Binlog 模式为 ROW
binlog_format = ROW
# binlog 日志的基本文件名,后面会追加标识来表示每一个 Binlog 文件
log_bin_basename =/var/lib/mysql/mysql-bin
# binlog 文件的索引文件,管理所有 Binlog 文件的目录
log_bin_index =/var/lib/mysql/mysql-bin.index -
执行如下命令,重启 MySQL,生效修改后的配置文件:
# 使用 service 启动
service mysqld restart
# 使用 mysqld 脚本启动
/etc/init.d/mysqld restart -
连接 MySQL,执行如下语句确认是否已经开启 Binlog:
-- 连接 MySQL
mysql -h xxx.xx.xxx.xx -P 3306 -u root -pxxxxxx
-- 检查是否已经开启 MySQL Binlog,`ON`就表示已开启
mysql> SHOW VARIABLES LIKE 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
同步库表结构
-
配置 SMT 配置文件。 进入 SMT 的 conf 目录,编辑配置文件 config_prod.conf。例如源 MySQL 连接信息、待同步库表的匹配规则,flink-connector-starrocks 配置信息等。
[db]
type = mysql
host = xxx.xx.xxx.xx
port = 3306
user = user1
password = xxxxxx
[other]
# number of backends in StarRocks
be_num = 3
# `decimal_v3` is supported since StarRocks-1.18.1
use_decimal_v3 = true
# file to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# pattern to match databases for setting properties
database = ^demo.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.starrocks.load-url= <fe_host>:<fe_http_port>
flink.starrocks.username=user2
flink.starrocks.password=xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000-
[db]:源数据库的连接信息。type:源数据库类型,本示例中源数据库为mysql。host:MySQL 所在服务器的 IP 地址。port:MySQL 端口号,默认为3306。user:用户名。password:用户登录密码。
-
[table-rule]:库表匹配规则,以及对应的flink-connector-starrocks 配置。-
database、table:MySQL 中同步对象的库表名,支持正则表达式。 -
flink.starrocks.*:flink-connector-starrocks 的配置信息,更多配置和说明,请参见 Flink-connector-starrocks。
-
-
[other]:其他信息be_num: StarRocks 集群的 BE 节点数(后续生成的 StarRocks 建表 SQL 文件会参考该参数,设置合理的分桶数量)。use_decimal_v3:是否开启 decimalV3。开启后,MySQL 小数类型的数据同步至 StarRocks 时会转换为 decimalV3。output_dir:待生成的 SQL 文件的路径。SQL 文件会用于在 StarRocks 集群创建库表, 向 Flink 集群提交 Flink job。默认为./result,不建议修改。
-
-
执行如下命令,SMT 会读取 MySQL 中同步对象的库表结构,并且结合配置文件信息,在 result 目录生成 SQL 文件,用于 StarRocks 集群创建库表(starrocks-create.all.sql), 用于向 Flink 集群提交同步数据的 flink job(flink-create.all.sql)。 并且源表不同,则 starrocks-create.all.sql 中建表语句默认创建的表类型不同。
- 如果源表没有 Primary Key、 Unique Key,则默认创建明细表。
- 如果源表有 Primary Key、 Unique Key,则区分以下几种情况:
- 源表是 Hive 表、ClickHouse MergeTree 表,则默认创建明细表。
- 源表是 ClickHouse SummingMergeTree表,则默认创建聚合表。
- 源表为其他类型,则默认创建主键表。
# 运行 SMT
./starrocks-migrate-tool
# 进入并查看 result 目录中的文件
cd result
ls result
flink-create.1.sql smt.tar.gz starrocks-create.all.sql
flink-create.all.sql starrocks-create.1.sql -
执行如下命令,连接 StarRocks,并执行 SQL 文件 starrocks-create.all.sql,用于创建目标库和表。推荐使用 SQL 文件中默认的建表语句,本示例中建表语句默认创建主键表。
注意
- 您也可以根据业务需要,修改 SQL 文件中的建表语句,创建目标表为其他类型的表。
- 如果您选择创建目标表为非主键表,StarRocks 不支持将源表中 DELETE 操作同步至非主键表,请谨慎使用。
mysql -h <fe_host> -P <fe_query_port> -u user2 -pxxxxxx < starrocks-create.all.sql如果数据需要经过 Flink 处理后写入目标表,目标表与源表的结构不一样,则您需要修改 SQL 文件 starrocks-create.all.sql 中的建表语句。本示例中目标表仅需要保留商品 ID (product_id)、商品名称(product_name),并且对商品销量进行实时排名,因此可以使用如下建表语句。
CREATE DATABASE IF NOT EXISTS `demo`;
CREATE TABLE IF NOT EXISTS `demo`.`orders` (
`product_id` INT(11) NOT NULL COMMENT "",
`product_name` STRING NOT NULL COMMENT "",
`sales_cnt` BIGINT NOT NULL COMMENT ""
) ENGINE=olap
PRIMARY KEY(`product_id`)
DISTRIBUTED BY HASH(`product_id`)
PROPERTIES (
"replication_num" = "3"
);注意
自 2.5.7 版本起,StarRocks 支持在建表和新增分区时自动设置分桶数量 (BUCKETS),您无需手动设置分桶数量。更多信息,请参见 设置分桶数量。
同步数据
运行 Flink 集群,提交 Flink job,启动流式作业,源源不断将 MySQL 数据库中的全量和增量数据同步到 StarRocks 中。
-
进入 Flink 目录,执行如下命令,在 Flink SQL 客户端运行 SQL 文件 flink-create.all.sql。
该 SQL 文件定义了动态表 source table、sink table,查询语句 INSERT INTO SELECT,并且指定 connector、源数据库和目标数据库。Flink SQL 客户端执行该 SQL 文件后,向 Flink 集群提交一个 Flink job,开启同步任务。
./bin/sql-client.sh -f flink-create.all.sql注意
-
需要确保 Flink 集群已经启动。可通过命令
flink/bin/start-cluster.sh启动。 -
如果您使用 Flink 1.13 之前的版本,则可能无法直接运行 SQL 文件 flink-create.all.sql。您需要在 SQL 客户端命令行界面,逐条执行 SQL 文件 flink-create.all.sql 中的 SQL 语句,并且需要做对
\字符进行转义。
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'处理同步数据
在同步过程中,如果您需要对数据进行一定的处理,例如 GROUP BY、JOIN 等,则可以修改 SQL 文件 flink-create.all.sql。本示例可以通过执行 count(*) 和 GROUP BY 计算出产品销量的实时排名。
$ ./bin/sql-client.sh -f flink-create.all.sql
No default environment specified.
Searching for '/home/disk1/flink-1.13.6/conf/sql-client-defaults.yaml'...not found.
[INFO] Executing SQL from file.
Flink SQL> CREATE DATABASE IF NOT EXISTS `default_catalog`.`demo`;
[INFO] Execute statement succeed.
-- 根据 MySQL 的订单表创建动态表 source table
Flink SQL>
CREATE TABLE IF NOT EXISTS `default_catalog`.`demo`.`orders_src` (
`order_id` BIGINT NOT NULL,
`product_id` INT NULL,
`order_date` TIMESTAMP NOT NULL,
`customer_name` STRING NOT NULL,
`product_name` STRING NOT NULL,
`price` DECIMAL(10, 5) NULL,
PRIMARY KEY(`order_id`)
NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = 'xxx.xx.xxx.xxx',
'port' = '3306',
'username' = 'root',
'password' = '',
'database-name' = 'demo',
'table-name' = 'orders'
);
[INFO] Execute statement succeed.
-- 创建动态表 sink table
Flink SQL>
CREATE TABLE IF NOT EXISTS `default_catalog`.`demo`.`orders_sink` (
`product_id` INT NOT NULL,
`product_name` STRING NOT NULL,
`sales_cnt` BIGINT NOT NULL,
PRIMARY KEY(`product_id`)
NOT ENFORCED
) with (
'sink.max-retries' = '10',
'jdbc-url' = 'jdbc:mysql://<fe_host>:<fe_query_port>',
'password' = '',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.format' = 'json',
'load-url' = '<fe_host>:<fe_http_port>',
'username' = 'root',
'sink.buffer-flush.interval-ms' = '15000',
'connector' = 'starrocks',
'database-name' = 'demo',
'table-name' = 'orders'
);
[INFO] Execute statement succeed.
-- 执行查询,实现产品实时排行榜功能,查询不断更新 sink table,以反映 source table 上的更改
Flink SQL>
INSERT INTO `default_catalog`.`demo`.`orders_sink` select product_id,product_name, count(*) as cnt from `default_catalog`.`demo`.`orders_src` group by product_id,product_name;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35da如果您只需要同步部分数据,例如支付时间在 2021 年 01 月 01 日之后的数据,则可以在 INSERT INTO SELECT 语句中使用 WHERE order_date >'2021-01-01' 设置过滤条件。不满足该条件的数据,即支付时间在 2021 年 01 月 01 日或者之前的数据不会同步至 StarRocks。
INSERT INTO `default_catalog`.`demo`.`orders_sink` SELECT product_id,product_name, COUNT(*) AS cnt FROM `default_catalog`.`demo`.`orders_src` WHERE order_date >'2021-01-01 00:00:01' GROUP BY product_id,product_name;如果返回如下结果,则表示 Flink job 已经提交,开始同步全量和增量数据。
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35da -
-
可以通过 Flink WebUI 或者在 Flink 命令行执行命令
bin/flink list -running,查看 Flink 集群中正在运行的 Flink job,以及 Flink job ID。-
Flink WebUI 界面
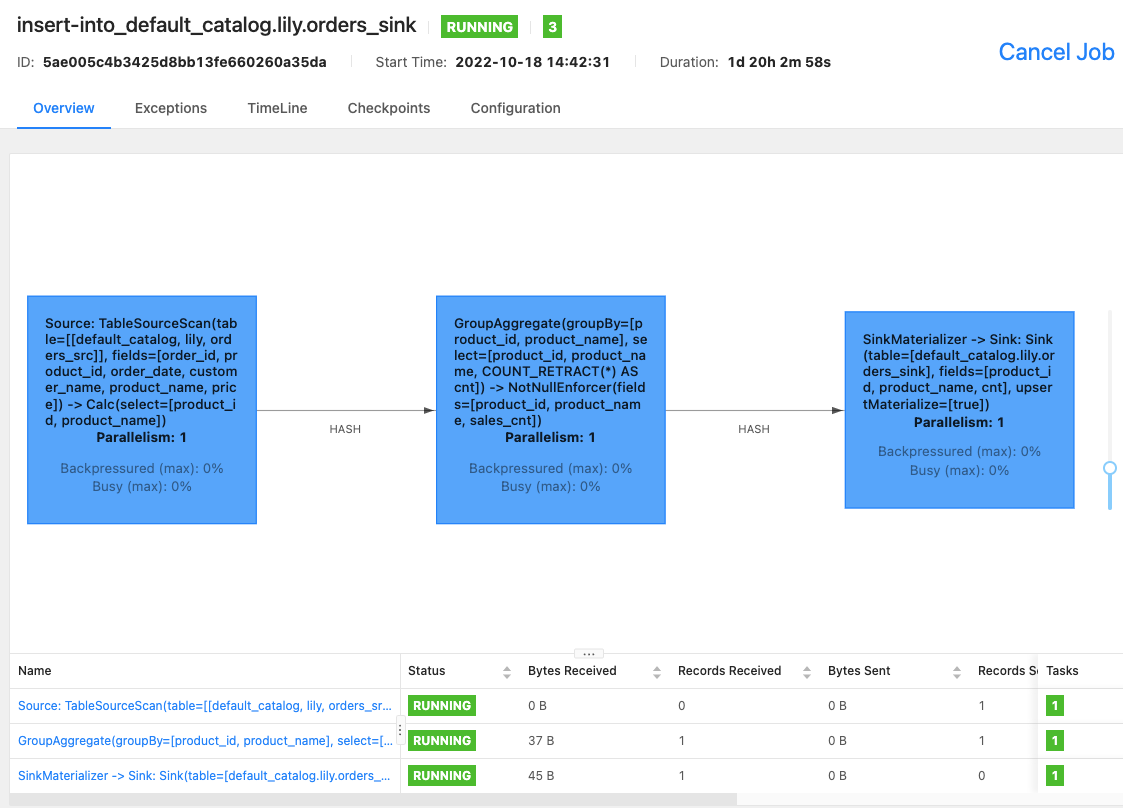
-
在 Flink 命令行执行命令
bin/flink list -running$ bin/flink list -running
Waiting for response...
------------------ Running/Restarting Jobs -------------------
13.10.2022 15:03:54 : 040a846f8b58e82eb99c8663424294d5 : insert-into_default_catalog.lily.example_tbl1_sink (RUNNING)
--------------------------------------------------------------说明
如果任务出现异常,可以通过 Flink WebUI 或者 flink-1.14.5/log 目录的日志文件进行排查。
-
常见问题
如何为不同的表设置不同的 flink-connector-starrocks 配置
例如数据源某些表更新频繁,需要提高 flink connector sr 的导入速度等,则需要在 SMT 配置文件 config_prod.conf 中为这些表设置单独的 flink-connector-starrocks 配置。
[table-rule.1]
# pattern to match databases for setting properties
database = ^order.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.starrocks.load-url= <fe_host>:<fe_http_port>
flink.starrocks.username=user2
flink.starrocks.password=xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
[table-rule.2]
# pattern to match databases for setting properties
database = ^order2.*$
# pattern to match tables for setting properties
table = ^.*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.starrocks.load-url= <fe_host>:<fe_http_port>
flink.starrocks.username=user2
flink.starrocks.password=xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=10000
同步 MySQL 分库分表后的多张表至 StarRocks 的一张表
如果数据源 MySQL 进行分库分表,数据拆分成多张表甚至分布在多个库中,并且所有表的结构都是相同的,则您可以设置[table-rule],将这些表同步至 StarRocks 的一张表中。比如 MySQL 有两个数据库 edu_db_1,edu_db_2,每个数据库下面分别有两张表 course_1,course_2,并且所有表的结构都是相同的,则通过设置如下[table-rule]可以将其同步至 StarRocks的一张表中。
说明
数据源多张表同步至 StarRocks的一张表,表名默认为 course__auto_shard。如果需要修改,则可以在 result 目录的 SQL 文件 starrocks-create.all.sql、 flink-create.all.sql 中修改。
[table-rule.1]
# pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
# pattern to match tables for setting properties
table = ^course_[0-9]*$
############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url = jdbc: mysql://xxx.xxx.x.x:xxxx
flink.starrocks.load-url = xxx.xxx.x.x:xxxx
flink.starrocks.username = user2
flink.starrocks.password = xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator =\x01
flink.starrocks.sink.properties.row_delimiter =\x02
flink.starrocks.sink.buffer-flush.interval-ms = 5000
数据以 JSON 格式导入
以上示例数据以 CSV 格式导入,如果数据无法选出合适的分隔符,则您需要替换 [table-rule] 中flink.starrocks.*的如下参数。
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator =\x01
flink.starrocks.sink.properties.row_delimiter =\x02
传入如下参数,数据以 JSON 格式导入。
flink.starrocks.sink.properties.format=json
flink.starrocks.sink.properties.strip_outer_array=true
注意
该方式会对导入速度有一定的影响。
多个的 INSERT INTO 语句合并为一个 Flink job
在 flink-create.all.sql 文件使用 STATEMENT SET 语句,将多个的 INSERT INTO 语句合并为一个 Flink job,避免占用过多的 Flink job 资源。
说明
Flink 自 1.13 起 支持 STATEMENT SET 语法。
-
打开 result/flink-create.all.sql 文件。
-
修改文件中的 SQL 语句,将所有的 INSERT INTO 语句调整位置到文件末尾。然后在第一条 INSERT语句的前面加上
EXECUTE STATEMENT SET BEGIN在最后一 INSERT 语句后面加上一行END;。注意
CREATE DATABASE、CREATE TABLE 的位置保持不变。
CREATE DATABASE IF NOT EXISTS db;
CREATE TABLE IF NOT EXISTS db.a1;
CREATE TABLE IF NOT EXISTS db.b1;
CREATE TABLE IF NOT EXISTS db.a2;
CREATE TABLE IF NOT EXISTS db.b2;
EXECUTE STATEMENT SET
BEGIN
-- 1个或者多个 INSERT INTO statements
INSERT INTO db.a1 SELECT * FROM db.b1;
INSERT INTO db.a2 SELECT * FROM db.b2;
END;
更多常见问题,请参见 MySQL 实时同步至 StarRocks 常见问题。
