架构
StarRocks 架构简洁明了,整个系统仅由两种组件组成:前端和后端。前端节点称为 FE。后端节点有两种类型,BE 和 CN (计算节点)。当使用本地存储数据时,您需要部署 BE;当数据存储在对象存储或 HDFS 时,需要部署 CN。StarRocks 不依赖任何外部组件,简化了部署和维护。节点可以水平扩展而不影响服务正常运行。此外,StarRocks 具有元数据和服务数据副本机制,提高了数据可靠性,有效防止单点故障 (SPOF)。
StarRocks 兼容 MySQL 协议,支持标准 SQL。用户可以轻松地通过 MySQL 客户端连接到 StarRocks 实时查询分析数据。
架构选择
StarRocks 支持存算一体架构 (每个 BE 节点将其数据存储在本地存储) 和存算分离架构 (所有数据存储在对象存储或 HDFS 中,每个 CN 仅在本地存储缓存)。您可以根据需要决定数据存储的位置。
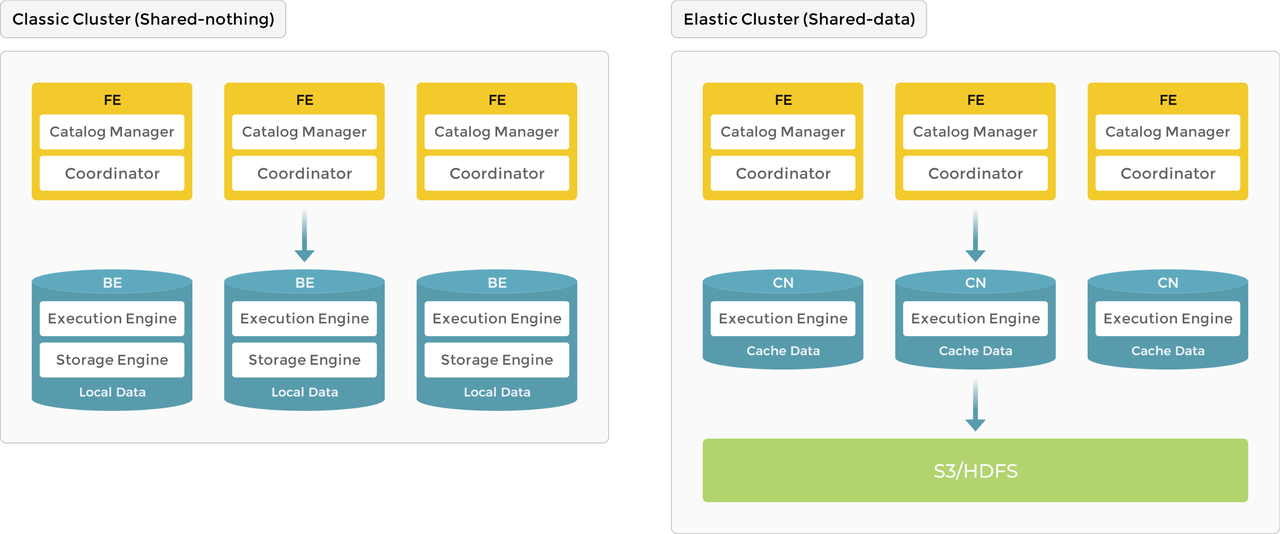
存算一体
本地存储为实时查询提供了更低的查询延迟。
作为典型的大规模并行处理 (MPP) 数据库,StarRocks 支持存算一体架构。在存算一体架构中,BE 负责数据存储和计算。将数据存储在 BE 中使得数据可以在当前节点中计算,避免了数据传输和复制,从而提供极快的查询和分析性能。该架构支持多副本数据存储,增强了集群处理高并发查询的能力并确保数据可靠性,非常适合追求最佳查询性能的场景。
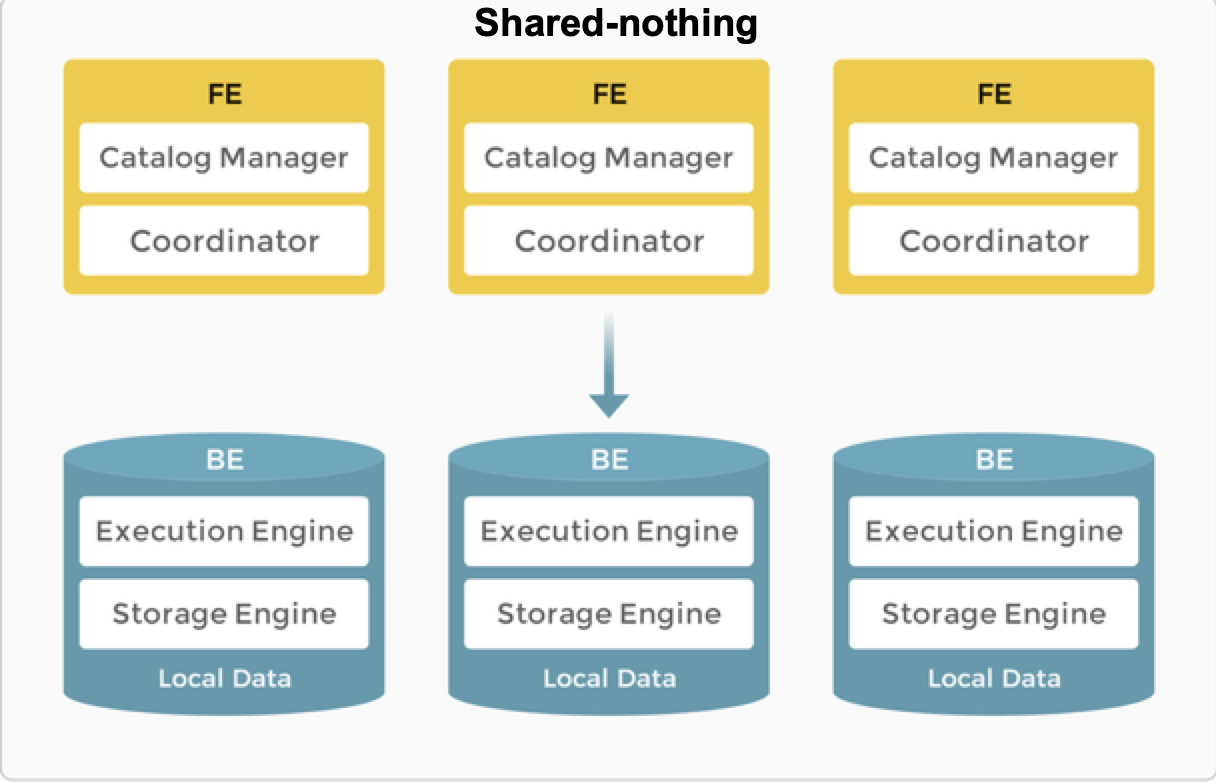
节点
在存算一体架构中,StarRocks 由两种类型的节点组成:FE 和 BE。
- FE 负责元数据管理和构建执行计划。
- BE 执行查询计划并存储数据。BE 利用本地存储加速查询,并使用多副本机制确保数据高可用性。
FE
FE负责元数据管理、客户端连接管理、查询规划和查询调度。每个FE使用BDB JE (Berkeley DB Java Edition)在其内存中存储和维护元数据的完整副本,从而确保所有FE之间的服务一致。FE可以作为领导者、追随者和观察者。如果leader节点崩溃,follower根据Raft协议选举leader。
| FE 角色 | 元数据管理 | 节点选主 |
|---|---|---|
| Leader 节点 | Leader FE 负责读写元数据。Follower 节点和 Observer 节点只能读取元数据,并将元数据写请求路由到 Leader FE。Leader FE 更新元数据,然后使用 Raft 协议将元数据更改同步到 Follower 节点和 Observer 节点。只有在元数据更改同步到超过一半的Follower 节点后,数据写入才被认为成功。 | Leader FE 技术上也是一个 Follower 节点,是从Follower 节点中选举出来的。要执行主节点选举,集群中必须有超过一半的Follower 节点处于活动状态。当 Leader FE 发生故障时,Follower 节点将开始另一轮主节点选举。 |
| Follower 节点 | Follower 节点只能读取元数据。它们从 Leader FE 同步和重放日志以更新元数据。 | Follower 节点参与主节点选举,这需要集群中超过一半的 Follower 节点处于活动状态。 |
| Observer 节点 | Observer 节点从 Leader FE 同步和重放日志以更新元数据。 | Observer 节点 主要用于增加集群的查询并发性。 Observer 节点不参与主节点选举,因此不会增加集群的主节点选举压力。 |
BE
BE 负责数据存储和 SQL 执行。
-
数据存储:BE 具有等效的数据存储能力。FE 根据预定义规则将数据分发到各个 BE。BE 转换导入的数据,将数据写入所需格式,并为数据生成索引。
-
SQL 执行:FE 根据查询的语义将每个 SQL 查询解析为逻辑执行计划,然后将逻辑计划转换为可以在 BE 上执行的物理执行计划。BE 在本地存储数据以及执行查询,避免了数据传输和复制,极大地提高了查询性能。
存算分离
对象存储和 HDFS 提供低成本、高可靠性和可扩展性等优势。除了可以扩展存储外,还可以随时添加和删除 CN 节点。因为存储和计算分离,增删节点也无需重新平衡数据。
在存算分离架构中,BE 被“计算节点 (CN)”取代,后者仅负责数据计算任务和缓存热数据。数据存储在低成本且可靠的远端存储系统中,如 Amazon S3、Google Cloud Storage、Azure Blob Storage、MinIO 等。当缓存命中时,查询性能可与存算一体架构相媲美。CN 节点可以根据需要在几秒钟内添加或删除。这种架构降低了存储成本,确保更好的资源隔离,并具有高度的弹性和可扩展性。
存算分离架构与存算一体架构一样简单。它仅由两种类型的节点组成:FE 和 CN。唯一的区别是用户必须配置后端对象存储。
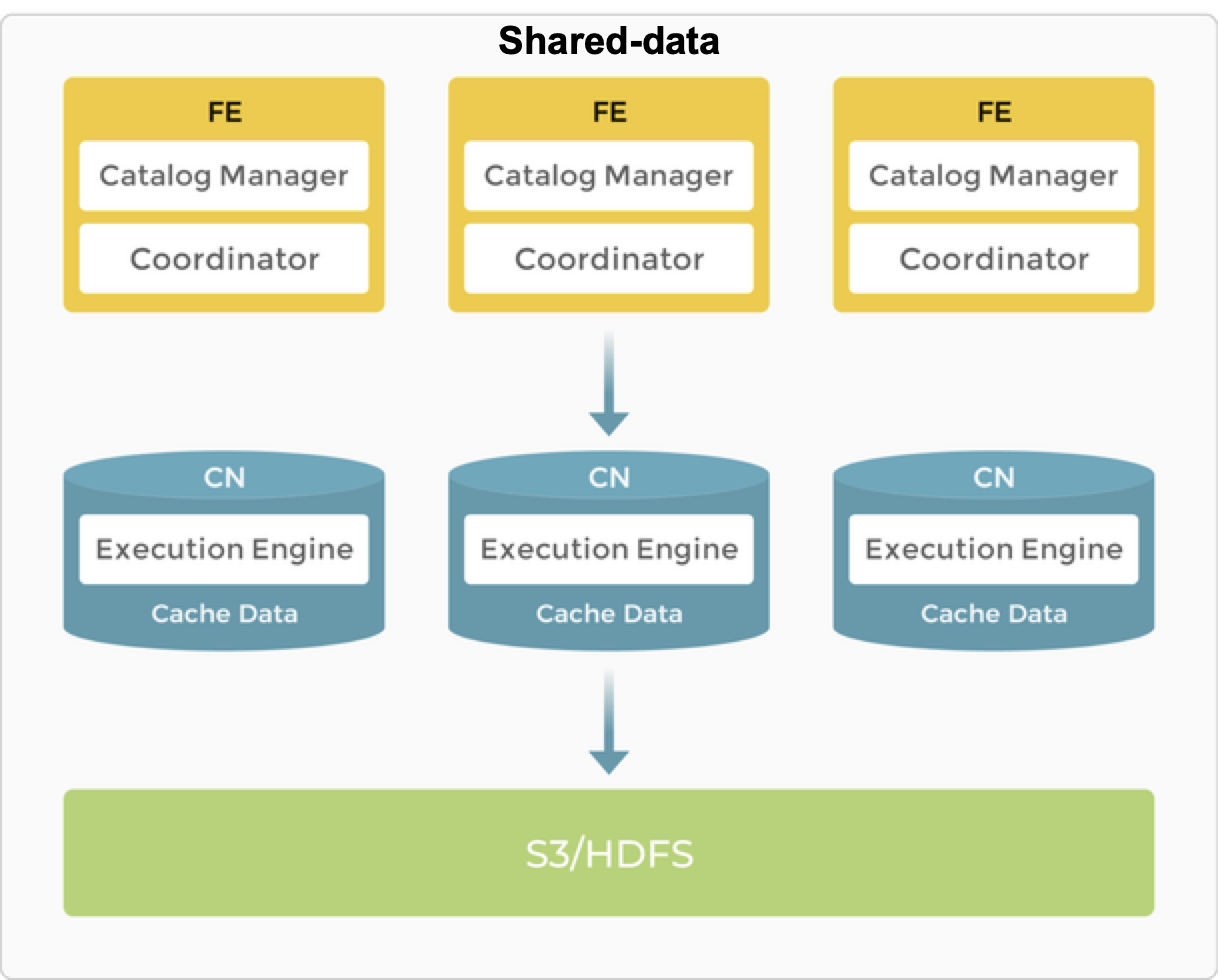
节点
在存算分离架构中,FE 提供的功能与存算一体架构中的相同。
BE 被 CN (计算节点) 取代,存储功能被转移到对象存储或 HDFS。CN 是无状态的计算节点,可以执行除存储数据外所有 BE 的功能。
存储
StarRocks 存算分离集群支持两种存储解决方案:对象存储 (例如,AWS S3、Google GCS、Azure Blob Storage 或 MinIO) 和 HDFS。
在存算分离集群中,数据文件格式与存算一体集群 (存储和计算耦合) 保持一致。数据存储为 Segment 文件,云原生表(专门用于存算分离集群的表)也可以利用存算一体架构中支持的各种索引技术。
缓存
StarRocks 存算分离集群将数据存储与计算分离,使两方都能够独立扩展,从而降低成本并提高系统弹性扩展能力。然而,这种架构会影响查询性能。
为减少架构对于性能的影响,StarRocks 建立了包含内存、本地磁盘和远端存储的多层数据访问系统,以便更好地满足各种业务需求。
对于针对热数据的查询,StarRocks 会先扫描缓存,然后扫描本地磁盘。而针对冷数据的查询,需要先将数据从对象存储中加载到本地缓存中,加速后续查询。通过将热数据缓存在计算单元内,StarRocks 实现了真正的高计算性能和高性价比存储。此外,还通过数据预取策略优化了对冷数据的访问,有效消除了查询的性能限制。
可以在建表时启用缓存。启用缓存后,数据将同时写入本地磁盘和后端对象存储。在查询过程中,CN 节点首先从本地磁盘读取�数据。如果未找到数据,将从后端对象存储中检索,并将数据缓存到本地磁盘中。
