查询调优方法
一份实用的操作手册:现象 → 根本原因 → 验证过的修复方案。 当您打开一个 profile,发现了一个危险指标,但仍然不知道“接下来该怎么办?”时,请使用它。
1 · 快速诊断工作流
-
浏览执行概览
如果QueryPeakMemoryUsagePerNode > 80 %或QuerySpillBytes > 1 GB,请直接跳转到内存和中间结果落盘的方案。 -
找到最慢的 Pipeline / Operator
⟶ 在 Query Profile UI 中,点击 Sort by OperatorTotalTime %。
最热门的 operator 会告诉你接下来要阅读哪个方案模块(Scan、Join、Aggregate 等)。 -
确认瓶颈子类型
每个方案都以其 signature 指标模式开始。在尝试修复之前,请先匹配这些模式。
2 · 按 Operator 分类
2.1 OLAP / Connector Scan [metrics]
为了帮助您更好地理解 Scan Operator 中的各项指标,下图展示了这些指标与存储结构之间的关联。
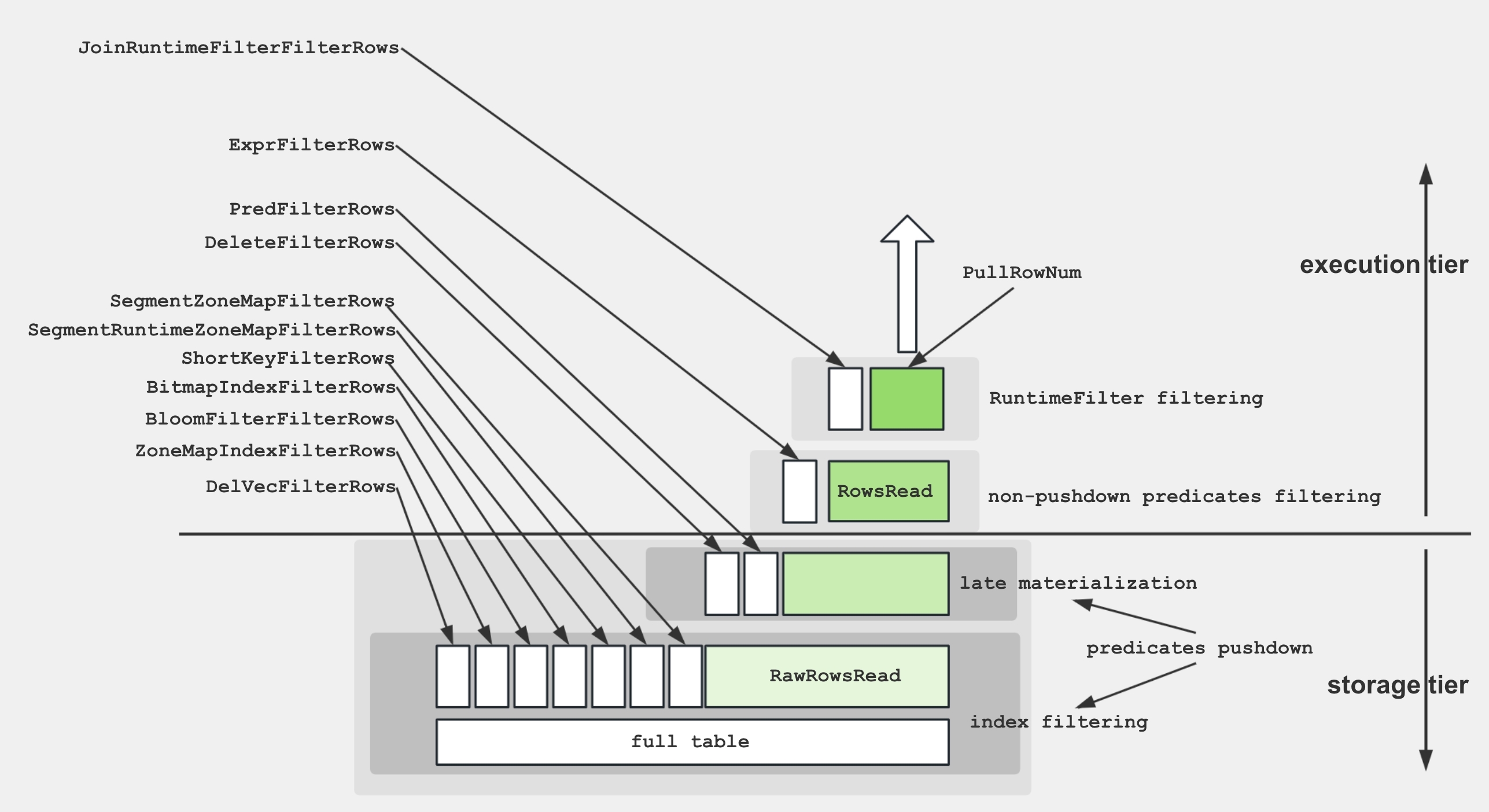
为了从磁盘检索数据并应用谓词,存储引擎采用了以下几种技术:
- 数据存储:编码和压缩后的数据以 segment 形式存储在磁盘上,并带有各种索引。
- 索引过滤:引擎利用 BitmapIndex、BloomfilterIndex、ZonemapIndex、ShortKeyIndex 和 NGramIndex 等索引来跳过不必要的数据。
- 下推谓词:简单的谓词(如
a > 1)会被下推以在特定列上进行计算。 - 延迟物化:仅从磁盘检索所需的列和过滤后的行。
- 非下推谓词:计算无法下推的谓词。
- 投影表达式:计算表达式,例如
SELECT a + 1。
Scan Operator 使用额外的线程池来执行 IO 任务。因此,此节点的 time 指标之间的关系如下图所示:

常见性能瓶颈
冷存储或慢速存储 – 当 BytesRead、ScanTime 或 IOTaskExecTime 占主导地位,并且磁盘 I/O 徘徊在 80-100 % 左右时,扫描会遇到冷存储或配置不足的存储。将热数据移动到 NVMe/SSD 并启用 Data Cache。通过 BE datacache_* 设置(或旧版 block_cache_*)调整其大小,并通过会话 enable_scan_datacache 启用扫描时使用。
Filter 下推缺失 – 如果 PushdownPredicates 保持在 0 附近,而 ExprFilterRows 很高,则谓词未到达存储层。将它们重写为简单的比较(避免 %LIKE% 和宽 OR 链),或者添加 zonemap/Bloom 索引或物化视图,以便可以将它们下推。
线程池饥饿 – 高 IOTaskWaitTime 以及低 PeakIOTasks 表示 I/O 并发已饱和。启用 Data Cache 并调整其大小(BE datacache_* 和会话 enable_scan_datacache),将热数据移动到更快的存储(NVMe/SSD)。
tablet 间的数据倾斜 – 最大和最小 OperatorTotalTime 之间的差距很大意味着某些 tablet 的工作量比其他 tablet 多得多。在更高基数的键上重新分桶,或增加分桶计数以分散负载。
Rowset/Segment 文件碎片 – 爆炸式增长的 RowsetsReadCount/SegmentsReadCount 加上较长的 SegmentInitTime 表示存在许多微小的 rowset。触发手动 Compaction 并批量加载小数据,以便 segment 提前合并。
累积的软删除 – 大量的 DeleteFilterRows 意味着大量使用软删除。运行 BE Compaction 以清除软删除。
2.2 聚合 [指标]
 Aggregate Operator 负责执行聚合函数、
Aggregate Operator 负责执行聚合函数、GROUP BY 和 DISTINCT。
聚合算法的多种形式
| 形式 | Planner 选择它的时机 | 内部数据结构 | 亮点/注意事项 |
|---|---|---|---|
| Hash aggregation | key 可以放入内存;基数不是很大 | 带有 SIMD 探测的紧凑哈希表 | 默认路径,非常适合适度的 key 计数 |
| Sorted aggregation | 输入已经按照 GROUP BY 的 key 排序 | 简单的行比较 + 运行状态 | 零哈希表成本,在探测重度倾斜时通常快 2-3 倍 |
| Spillable aggregation (3.2+) | 哈希表超出内存限制 | 具有磁盘溢出分区的混合哈希/合并 | 防止 OOM,保留 pipeline 并行度 |
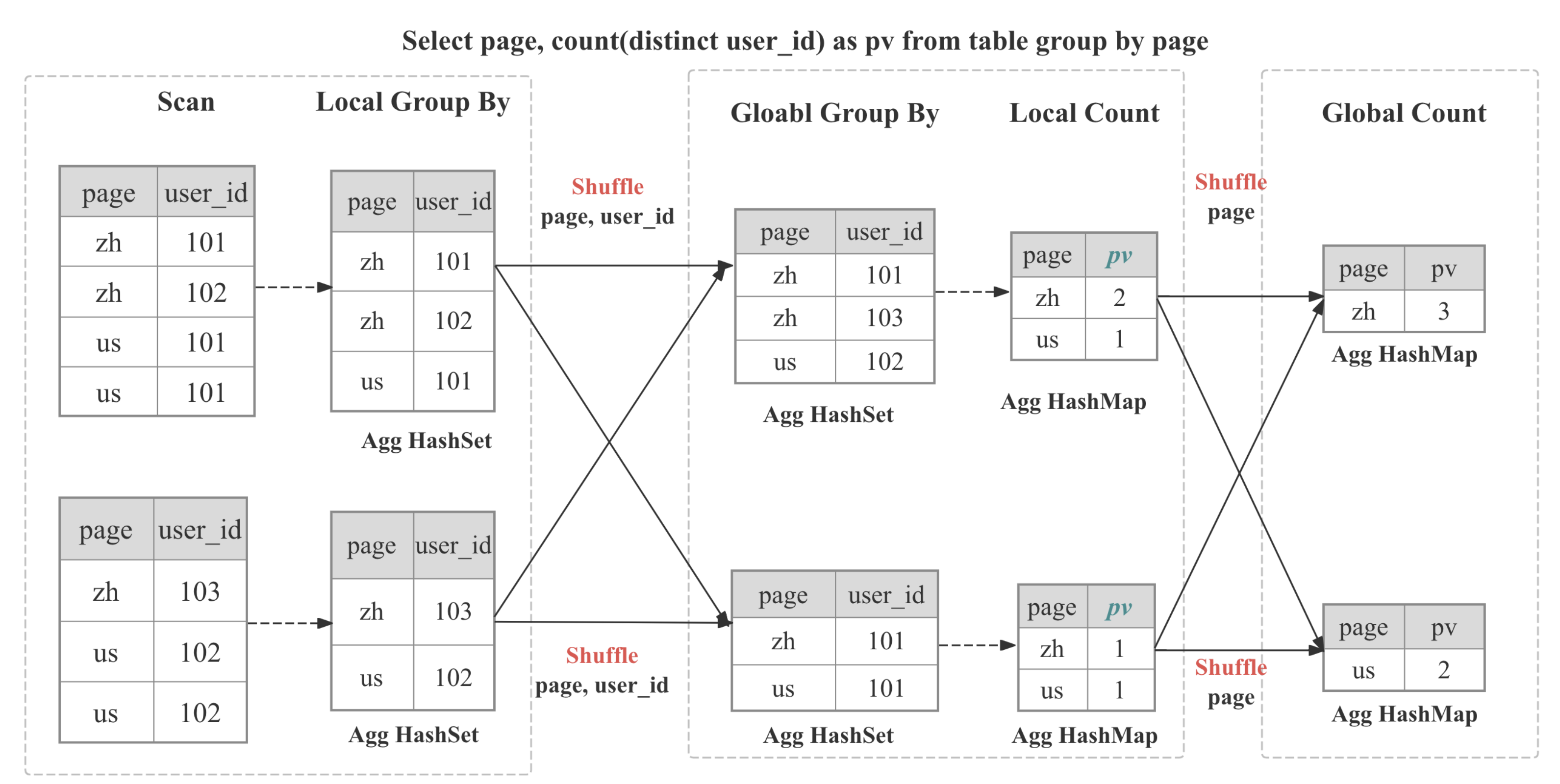
多阶段分布式聚合
在 StarRocks 中,聚合以分布式方式实现,它可以是多阶段的,具体取决于查询模式和优化器的决策。
┌─────────┐ ┌──────────┐ ┌────────────┐ ┌────────────┐
│ Stage 0 │ local │ Stage 1 │ shard/ │ Stage 2 │ gather/│ Stage 3 │ final
│ Partial │───► │ Update │ hash │ Merge │ shard │ Finalize │ output
└─────────┘ └──────────┘ └────────────┘ └────────────┘
| 阶段 | 使用场景 | 过程 |
|---|---|---|
| 单阶段 | DISTRIBUTED BY 是 GROUP BY 的子集,分区是 Colocate 的 | 部分聚合会立即成为最终结果。 |
| 两阶段 (local + global) | 典型的分布式 GROUP BY | 阶段 0 在每个 BE 中自适应地折叠重复项;阶段 1 基于 GROUP BY 对数据进行洗牌,然后执行全局聚合 |
| 三阶段 (local + shuffle + final) | 大量的 DISTINCT 和高基数的 GROUP BY | 阶段 0 如上;阶段 1 按 GROUP BY 进行洗牌,然后按 GROUP BY 和 DISTINCT 进行聚合;阶段 2 将部分状态合并为 GROUP BY |
| 四阶段 (local + partial + intermediate + final) | 大量的 DISTINCT 和低基数的 GROUP BY | 引入一个额外的阶段,通过 GROUP BY 和 DISTINCT 进行洗牌,以避免单点瓶颈 |
常见性能瓶颈
高基数 GROUP BY – 当 HashTableSize 或 HashTableMemoryUsage 膨胀到接近内存限制时,分组键过宽或过于离散。启用排序流式聚合 (enable_streaming_preaggregation = true),创建 roll-up 物化视图,或者将宽字符串键转换为 INT。
Shuffle 倾斜 – 各个分片之间 HashTableSize 或 InputRowCount 存在巨大差异,表明 shuffle 不平衡。向键添加 salt 列,或使用 DISTINCT [skew] 提示,使行均匀分布。
状态繁重的聚合函数 – 如果 AggregateFunctions 在运行时占主导地位,并且函数包括 HLL_、BITMAP_ 或 COUNT(DISTINCT),则表示有大量的状态对象在移动。在数据摄取期间预先计算 HLL/Bitmap 草图,或切换到近似变体。
部分聚合性能下降 – 巨大的 InputRowCount 伴随着适度的 AggComputeTime,加上上游 EXCHANGE 中大量的 BytesSent,意味着预聚合被绕过。使用 SET streaming_preaggregation_mode = "force_preaggregation" 强制重新启用它。
代价高昂的键表达式 – 当 ExprComputeTime 与 AggComputeTime 相媲美时,GROUP BY 键是逐行计算的。在子查询中物化这些表达式,或者将它们提升为生成列。
2.3 Join [metrics]
Join Operator 负责实现显式 join 或隐式 join。
在执行期间,join operator 分为 Build(哈希表构建)和 Probe 阶段,这两个阶段在 pipeline engine 中并行运行。向量块(最多 4096 行)通过 SIMD 进行批量哈希处理;使用的键会生成运行时过滤器(Bloom 或 IN 过滤器),这些过滤器会被推送回上游扫描,以尽早减少 probe 输入。
Join 策略
StarRocks 依赖于向量化、pipeline 友好的哈希 Join 核心,该核心可以连接到四种物理策略中,CBO优化器会在计划时权衡这些策略:
| Strategy | 优化器选择它的时机 | 它的优势 |
|---|---|---|
| Colocate Join | 两个表都属于同一个 Colocation Group(相同的分桶键、分桶数和副本布局)。 | 无需网络 shuffle:每个 BE 仅连接其本地分桶。 |
| Bucket-Shuffle Join | 其中一个 Join 表与 Join 键具有相同的分桶键 | 只需要 shuffle 一个 Join 表,从而降低网络成本 |
| Broadcast Join | Build 端非常小(行/字节阈值或显式提示)。 | 小表被复制到每个 probe 节点;避免 shuffle 大表。 |
| Shuffle (Hash) Join | 一般情况,键不对齐。 | 对 Join 键上的每一行进行哈希分区,以便 probe 在 BE 之间实现平衡。 |
常见的性能瓶颈
Build 端过大 - BuildHashTableTime 和 HashTableMemoryUsage 出现峰值,表明 build 端超出了内存限制。可以交换 probe 表和 build 表,预过滤 build 表,或者启用 hash 中间结果落盘。
Cache 不友好的 Probe 端 - 当 SearchHashTableTime 占主导地位时,probe 端的缓存效率不高。按照 Join Key 对 probe 行进行排序,并启用运行时过滤。
Shuffle 倾斜 - 如果单个 fragment 的 ProbeRows 远超其他 fragment,则表示数据倾斜。可以切换到更高基数的 Key,或者添加一个盐,例如 key || mod(id, 16)。
意外的 Broadcast - Join 类型为 BROADCAST 且 BytesSent 很大,表示您认为很小的表实际上并不小。可以降低 broadcast_row_limit,或者使用 SHUFFLE 提示强制执行 shuffle。
缺少运行时过滤 - 较小的 JoinRuntimeFilterEvaluate 以及全表扫描表明运行时过滤没有传播。可以将 Join 重写为纯等式,并确保列类型一致。
非等值回退 - 当 operator 类型为 CROSS 或 NESTLOOP 时,不等式或函数会阻止 Hash Join。可以添加一个真正的等式谓词,或者预过滤较大的表。
2.4 Exchange (网络) [指标]
过大的 Shuffle 或 Broadcast – 如果 NetworkTime 超过 30%,且 BytesSent 很大,则说明查询传输的数据过多。重新评估 JOIN 策略并减少 Shuffle/Broadcast 的数据量(例如,强制执行 Shuffle 而不是 Broadcast,或者预先过滤上游数据)。
接收端积压 – 如果接收端的 WaitTime 很高,并且发送端队列始终处于满负荷状态,则表明接收端无法跟上。增加接收端线程池 (brpc_num_threads),并确认网卡带宽和 QoS 设置。
启用 Exchange 压缩 – 当网络带宽成为瓶颈时,可以压缩 Exchange 的负载。设置 SET transmission_compression_type = 'zstd';,并可以选择增加 SET transmission_encode_level = 7; 以启用自适应列编码。预计 CPU 使用率会更高,以换取网络传输字节数的减少。
2.5 排序/合并/窗口
为了便于理解各种指标,Merge 可以表示为以下状态机制:
┌────────── PENDING ◄──────────┐
│ │
│ │
├──────────────◄───────────────┤
│ │
▼ │
INIT ──► PREPARE ──► SPLIT_CHUNK ──► FETCH_CHUNK ──► FINISHED
▲
|
| one traverse from leaf to root
|
▼
PROCESS
排序落盘 (Sort spilling) – 当 MaxBufferedBytes 超过大约 2 GB 或 SpillBytes 不为零时,排序阶段将落盘到磁盘。如果机器有足够的内存,可以添加 LIMIT,预聚合上游数据,或提高 sort_spill_threshold。
合并饥饿 (Merge starvation) – 高 PendingStageTime 告诉您合并正在等待上游数据块。首先优化生产者 operator 或增大 pipeline 缓冲区。
宽窗口分区 (Wide window partitions) – 窗口 operator 中巨大的 PeakBufferedRows 指向非常宽的分区��或缺少帧限制的 ORDER BY。可以更精细地分区,添加 RANGE BETWEEN 边界,或物化中间聚合。
3 · 内存和溢出速查表
| 阈值 | 需要关注的指标 | 实际操作 |
|---|---|---|
| 80 % 的 BE 内存 | QueryPeakMemoryUsagePerNode | 降低会话变量 exec_mem_limit 或增加 BE 内存 |
检测到溢出 (SpillBytes > 0) | QuerySpillBytes,每个 Operator 的 SpillBlocks | 增加内存限制;升级到 StarRocks 3.2+ 版本,使用混合哈希/合并溢出 |
4 · 事后总结报告模板
1. Symptom
– Slow stage: Aggregate (OperatorTotalTime 68 %)
– Red-flag: HashTableMemoryUsage 9 GB (> exec_mem_limit)
2. Root cause
– GROUP BY high-cardinality UUID
3. Fix applied
– Added sorted streaming agg + roll-up MV
4. Outcome
– Query runtime ↓ from 95 s ➜ 8 s; memory peak 0.7 GB```
