クエリチューニングのレシピ
実用的なプレイブック:症状 → 根本原因 → 実証済みの修正。 プロファイルを開いて、注意すべき指標を見つけたものの、「これからどうすればいい?」という疑問が残る場合に活用してください。
1 · 高速診断ワークフロー
-
実行概要をざっと見る
QueryPeakMemoryUsagePerNode > 80 %またはQuerySpillBytes > 1 GBの場合、メモリとディスクへのスピルのレシピに直接進みます。 -
最も遅い Pipeline / Operator を見つける
⟶ Query Profile UI で、OperatorTotalTime % でソートをクリックします。
最も負荷の高い operator は、次にどのレシピブロックを読むべきかを教えてくれます (Scan, Join, Aggregate, …)。 -
ボトルネックのサブタイプを確認する
各レシピは、その_シグネチャ_メトリックパターンから始まります。修正を試す前に、それらに一致させてください。
2 · Operator ごとのレシピ
2.1 OLAP / Connector Scan [metrics]
Scan Operator 内の様々なメトリクスをより良く理解するために、以下の図はこれらのメトリクスとストレージ構造の関連性を示しています。
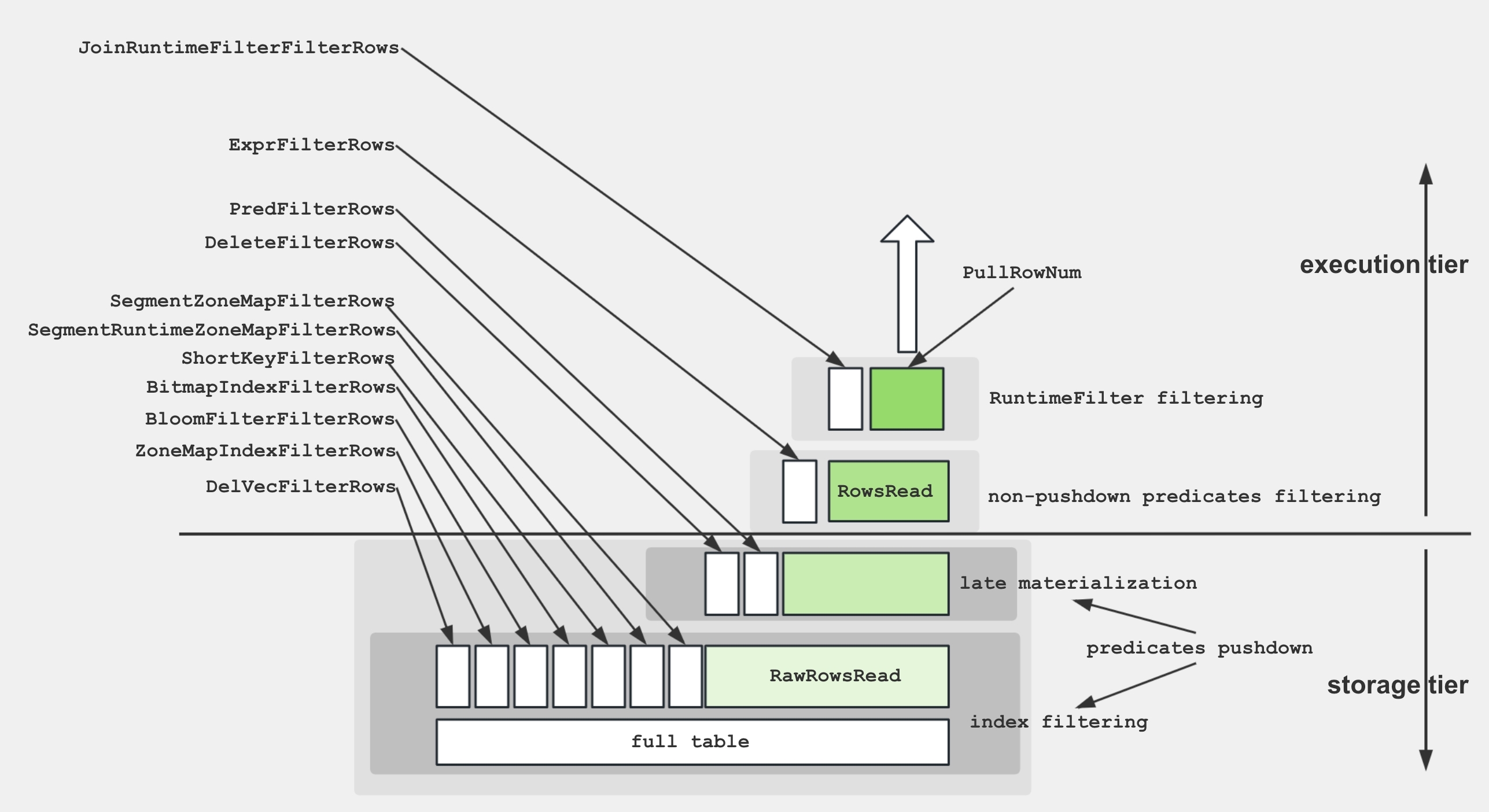
ディスクからデータを取得し、述語を適用するために、ストレージエンジンはいくつかの手法を利用します。
- データストレージ: エンコードおよび圧縮されたデータは、セグメント内のディスクに格納され、様々なインデックスが付属しています。
- インデックスフィルタリング: エンジンは、BitmapIndex、BloomfilterIndex、ZonemapIndex、ShortKeyIndex、および NGramIndex などのインデックスを利用して、不要なデータをスキップします。
- Pushdown Predicates:
a > 1のような単純な述語は、特定の列で評価するためにプッシュダウンされます。 - 後期実体化: 必要な列とフィルタリングされた行のみがディスクから取得されます。
- Non-Pushdown Predicates: プッシュダウンできない述語が評価されます。
- Projection Expression:
SELECT a + 1などの式が計算されます。
Scan Operator は、IO タスクを実行するための追加のスレッドプールを利用します。したがって、このノードの時間メトリクス間の関係は、以下に示すとおりです。

一般的なパフォーマンスのボトルネック
コールドストレージまたは低速なストレージ – BytesRead、ScanTime、または IOTaskExecTime が支配的で、ディスク I/O が 80〜100 % 前後で推移している場合、スキャンはコールドストレージまたはプロビジョニング不足のストレージにアクセスしています。ホットデータを NVMe/SSD に移動し、Data Cache を有効にします。BE の datacache_* 設定(または従来の block_cache_*)でサイズを設定し、セッション enable_scan_datacache でスキャン時の使用を有効にします。
Filter のプッシュダウンの欠落 – PushdownPredicates が 0 付近にとどまり、ExprFilterRows が高い場合、述語はストレージ層に到達していません。それらを単純な比較として書き換えるか(%LIKE% や広範な OR チェーンを避ける)、zonemap/Bloom インデックスまたはマテリアライズドビューを追加して、プッシュダウンできるようにします。
スレッドプールの枯渇 – 高い IOTaskWaitTime と低い PeakIOTasks は、I/O の並行性が飽和していることを示しています。Data Cache を有効にしてサイズを設定し(BE datacache_* とセッション enable_scan_datacache)、ホットデータをより高速なストレージ(NVMe/SSD)に移動します。
tablet 間のデータスキュー – 最大値と最小値の OperatorTotalTime の間に大きな隔たりがある場合、一部の tablet は他の tablet よりもはるかに多くの作業を行っています。より高い基数のキーで再バケットするか、バケット数を増やして負荷を分散します。
Rowset/セグメントの断片化 – RowsetsReadCount/SegmentsReadCount の急増と長い SegmentInitTime は、多数の小さな rowset が存在することを示しています。手動 Compaction をトリガーし、小さなロードをバッチ処理して、セグメントを事前にマージします。
累積されたソフトデリート – 大きな DeleteFilterRows は、大量のソフトデリートの使用を示唆しています。BE Compaction を実行して、ソフトデリートをパージします。
2.2 集計 [metrics]
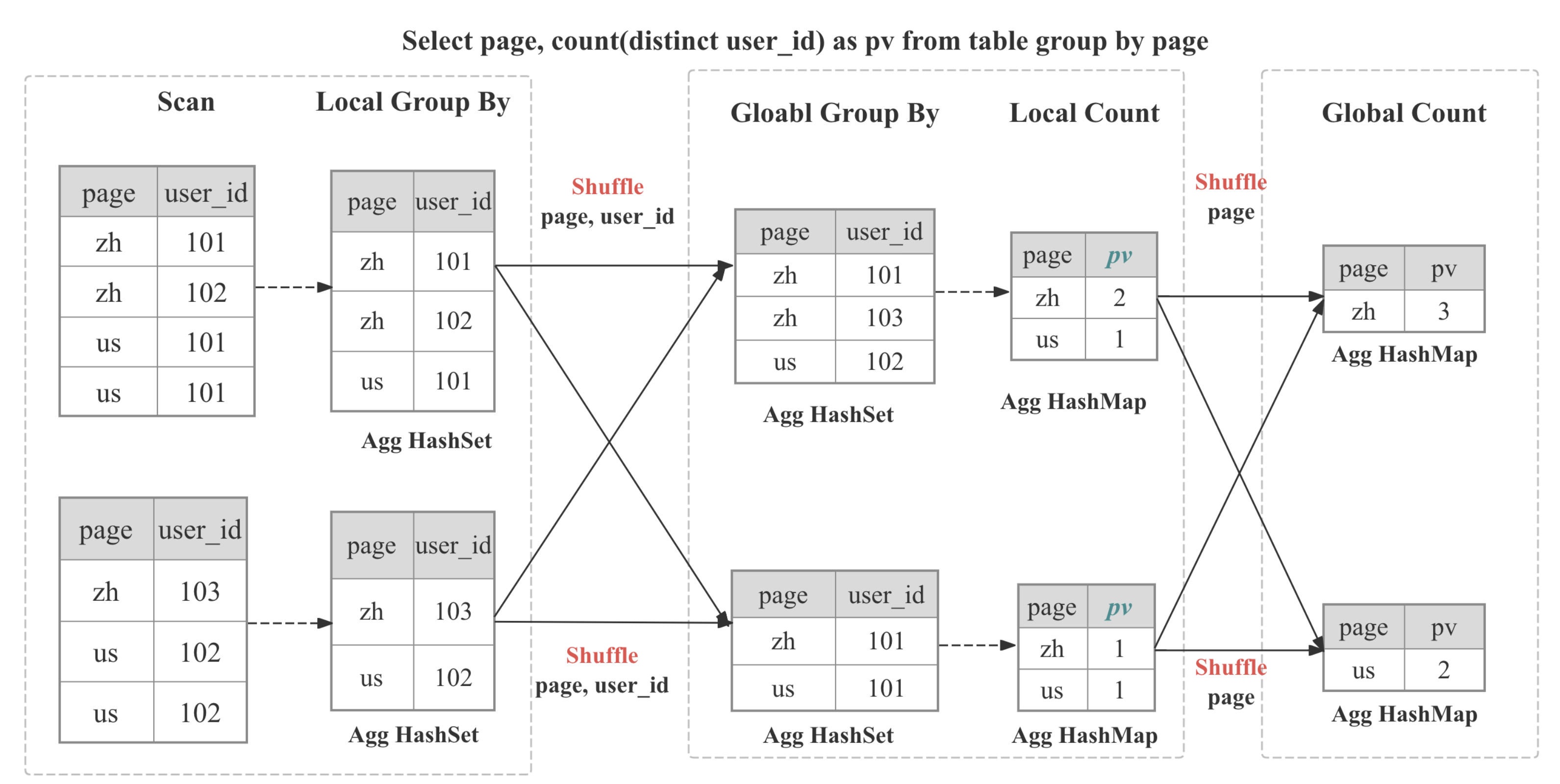 Aggregate Operator は、集計関数、
Aggregate Operator は、集計関数、GROUP BY、および DISTINCT の実行を担当します。
集計アルゴリズムの複数の形式
| 形式 | プランナーが選択するタイミング | 内部データ構造 | ハイライト/注意点 |
|---|---|---|---|
| ハッシュ集計 | キーがメモリに収まる場合。カーディナリティが極端でない場合 | SIMDプロービングを備えたコンパクトなハッシュテーブル | デフォルトのパス。適度なキー数に最適です。 |
| ソートされた集計 | 入力が GROUP BY キーで既に順序付けられている場合 | 単純な行比較 + 実行状態 | ハッシュテーブルのコストがゼロ。プロービングの偏りが大きい場合に、多くの場合2〜3倍高速です。 |
| スピル可能な集計 (3.2+) | ハッシュテーブルがメモリ制限を超える場合 | ディスクスピルパーティションを使用したハイブリッドハッシュ/マージ | OOMを防ぎ、パイプラインの並行性を維持します。 |
マルチステージ分散集計
StarRocks では、集計は分散方式で実装されており、クエリパターンとオプティマイザの決定に応じてマルチステージになる場合があります。
┌─────────┐ ┌──────────┐ ┌────────────┐ ┌────────────┐
│ Stage 0 │ local │ Stage 1 │ shard/ │ Stage 2 │ gather/│ Stage 3 │ final
│ Partial │───► │ Update │ hash │ Merge │ shard │ Finalize │ output
└─────────┘ └──────────┘ └────────────┘ └────────────┘
| ステ��ージ | 使用されるケース | 処理内容 |
|---|---|---|
| 1段階 | DISTRIBUTED BY が GROUP BY のサブセットであり、パーティションがコロケートされている場合 | 部分的な集計結果が即座に最終結果となる。 |
| 2段階 (local + global) | 典型的な分散 GROUP BY | 各BE内部のステージ0で重複を適応的に削減。ステージ1で GROUP BY に基づいてデータをシャッフルし、グローバルな集計を実行 |
| 3段階 (local + shuffle + final) | 大量の DISTINCT と高基数の GROUP BY | ステージ0は上記と同様。ステージ1で GROUP BY によってシャッフルし、GROUP BY と DISTINCT で集計。ステージ2で GROUP BY として部分的な状態をマージ |
| 4段階 (local + partial + intermediate + final) | 大量の DISTINCT と低基数の GROUP BY | GROUP BY と DISTINCT でシャッフルする追加のステージを導入し、シングルポイントのボトルネックを回避 |
一般的なパフォーマンスのボトルネック
高基数 GROUP BY – HashTableSize または HashTableMemoryUsage がメモリ制限に向かって膨れ上がっている場合、グルーピングキーが広すぎるか、または区別がつきすぎます。ソートされたストリーミング集計 (enable_streaming_preaggregation = true) を有効にするか、ロールアップマテリアライズドビューを作成するか、または幅の広い文字列キーを INT にキャストします。
シャッフルスキュー – フラグメント間の HashTableSize または InputRowCount に大きな差がある場合は、アンバランスなシャッフルが発生しています。キーにソルトカラムを追加するか、または行が均等に分散されるように DISTINCT [skew] ヒントを使用します。
ステートフルな集計関数 – AggregateFunctions がランタイムを支配し、関数に HLL_、BITMAP_、または COUNT(DISTINCT) が含まれている場合、巨大なステートオブジェクトが移動されています。データ取り込み中に HLL/ビットマップスケッチを事前計算するか、または近似バリアントに切り替えます。
部分集計の劣化 – 控えめな AggComputeTime で巨大な InputRowCount に加え、アップストリームの EXCHANGE で大規模な BytesSent が発生している場合は、事前集計がバイパスされています。SET streaming_preaggregation_mode = "force_preaggregation" を使用して強制的にオンに戻します。
コストのかかるキー式 – ExprComputeTime が AggComputeTime に匹敵する場合、GROUP BY キーは行ごとに計算されます。サブクエリでこれらの式をマテリアライズするか、または生成列に昇格させます。
2.3 Join [metrics]
Join Operator は、明示的なジョインまたは暗黙的なジョインを実装する役割を担います。
実行中、join operator は、パイプラインエンジン内で並行して実行される Build (ハッシュテーブルの構築) フェーズと Probe フェーズに分割されます。ベクターチャンク (最大 4096 行) は SIMD でバッチハッシュされます。消費されたキーはランタイムフィルター (Bloom フィルターまたは IN フィルター) を生成し、プローブ入力を早期に削減するためにアップストリームスキャンにプッシュバックされます。
Join の戦略
StarRocks は、ベクトル化されたパイプラインフレンドリーなハッシュジョインコアに依存しており、コストベースオプティマイザが計画時に評価する 4 つの物理的な戦略に組み込むことができます。
| 戦略 | オプティマイザが選択する条件 | 高速化の理由 |
|---|---|---|
| Colocate Join | 両方のテーブルが同じ Colocation Group に属している (同一のバケットキー、バケット数、レプリカレイアウト)。 | ネットワークシャッフルなし: 各 BE はローカルバケットのみをジョインします。 |
| Bucket-Shuffle Join | ジョインテーブルのいずれかがジョインキーと同じバケットキーを持っている | 1 つのジョインテーブルのみをシャッフルする必要が��あるため、ネットワークコストを削減できます。 |
| Broadcast Join | Build 側が非常に小さい (行/バイトの閾値または明示的なヒント)。 | 小さいテーブルはすべてのプローブノードに複製されます。大きなテーブルのシャッフルを回避します。 |
| Shuffle (Hash) Join | 一般的なケース。キーが整列していません。 | ジョインキーの各行をハッシュパーティション化して、プローブが BE 全体でバランスされるようにします。 |
一般的なパフォーマンスのボトルネック
ビルド側の肥大化 – BuildHashTableTime と HashTableMemoryUsage の急増は、ビルド側がメモリを使い果たしていることを示します。プローブテーブルとビルドテーブルを入れ替えたり、ビルドテーブルを事前にフィルタリングしたり、ハッシュのスピルを有効にしたりします。
キャッシュ効率の悪いプローブ – SearchHashTableTime が支配的な場合、プローブ側はキャッシュ効率が悪いです。ジョインキーでプローブ行をソートし、ランタイムフィルターを有効にします。
シャッフルスキュー – 単一のフラグメントの ProbeRows が他のすべてのフラグメントを圧倒的に上回っている場合、データは偏っています。カーディナリティの高いキーに切り替えるか、key || mod(id, 16) のようなソルトを追加します。
意図しないブロードキャスト – ジョインタイプが BROADCAST で、BytesSent が非常に大きい場合、小さいと思っていたテーブルがそうではありません。broadcast_row_limit を下げるか、SHUFFLE ヒントでシャッフルを強制します。
ランタイムフィルターの欠落 – わずかな JoinRuntimeFilterEvaluate とフルテーブルスキャンが組み合わさると、ランタイムフィルターが伝播されなかったことを示唆します。ジョインを純粋な等価性として書き換え、カラムタイプが一致していることを確認します。
非等価フォールバック – operator タイプが CROSS または NESTLOOP の場合、不等式または関数がハッシュジョインを妨げます。真の等価述語を追加するか、より大きなテーブルを事前にフィルタリングします。
2.4 Exchange (Network) [metrics]
過大なシャッフルまたはブロードキャスト – NetworkTime が 30 % を超え、BytesSent が大きい場合、クエリは大量のデータを送信しています。ジョイン戦略を再評価し、シャッフル/ブロードキャストの量を減らしてください (例: ブロードキャストの代わりにシャッフルを強制するか、アップ�ストリームを事前フィルタリングします)。
受信側のバックログ – シンクの WaitTime が高く、送信側のキューがいっぱいの状態が続く場合は、受信側が処理しきれていないことを示します。受信側のスレッドプール (brpc_num_threads) を増やし、NIC の帯域幅と QoS 設定を確認してください。
Exchange の圧縮を有効にする – ネットワーク帯域幅がボトルネックになっている場合は、Exchange のペイロードを圧縮します。SET transmission_compression_type = 'zstd'; を設定し、オプションで SET transmission_encode_level = 7; を増やして、適応的な列エンコーディングを有効にします。ネットワーク上で削減されるバイト数と引き換えに、CPU 使用率が高くなることが予想されます。
2.5 Sort / Merge / Window
さまざまなメトリクスを理解しやすくするために、Merge は次の状態メカニズムとして表現できます。
┌────────── PENDING ◄──────────┐
│ │
│ │
├──────────────◄───────────────┤
│ │
▼ │
INIT ──► PREPARE ──► SPLIT_CHUNK ──► FETCH_CHUNK ──► FINISHED
▲
|
| one traverse from leaf to root
|
▼
PROCESS
ソートのスピル - MaxBufferedBytes がおよそ 2 GB を超えるか、SpillBytes がゼロでない場合、ソートフェーズはディスクにスピルしています。LIMIT を追加するか、上流で事前集計を行うか、マシンに十分なメモリがある場合は sort_spill_threshold を上げてください。
マージのスターベーション - 高い PendingStageTime は、マージが上流のチャンクを待っていることを示しています。最初にプロデューサー operator を最適化するか、パイプラインバッファを拡大してください。
幅の広いウィンドウパーティション - ウィンドウ operator 内の巨大な PeakBufferedRows は、非常に広いパーティション、またはフレーム制限のない ORDER BY を示しています。より細かくパーティション化するか、RANGE BETWEEN の境界を追加するか、中間集計を実体化してください。
3 · メモリとスピルの早見表
| しきい値 | 監視対象 | 実際的なアクション |
|---|---|---|
| BE メモリの 80 % | QueryPeakMemoryUsagePerNode | セッション変数 exec_mem_limit を下げるか、BE の RAM を増設する |
スピル検出 ( SpillBytes > 0) | QuerySpillBytes 、 operator ごとの SpillBlocks | メモリ制限を増やす。ハイブリッドハッシュ/マージスピルのために SR 3.2 以降にアップグレードする |
4 · ポストモーテムのテンプレート
1. Symptom
– Slow stage: Aggregate (OperatorTotalTime 68 %)
– Red-flag: HashTableMemoryUsage 9 GB (> exec_mem_limit)
2. Root cause
– GROUP BY high-cardinality UUID
3. Fix applied
– Added sorted streaming agg + roll-up MV
4. Outcome
– Query runtime ↓ from 95 s ➜ 8 s; memory peak 0.7 GB```
