クエリヒント
クエリヒントは、クエリオプティマイザに対してクエリの実行方法を明示的に指示するための指示またはコメントです。現在、StarRocks は3種類のヒントをサポートしています: システム変数ヒント (SET_VAR)、ユーザー定義変数ヒント (SET_USER_VARIABLE)、および Join ヒントです。ヒントは単一のクエリ内でのみ効果を発揮します。
システム変数ヒント
SET_VAR ヒントを使用して、SELECT および SUBMIT TASK 文で1つ以上のシステム変数を設定し、その後に文を実行できます。また、CREATE MATERIALIZED VIEW AS SELECT や CREATE VIEW AS SELECT などの他の文に含まれる SELECT 句でも SET_VAR ヒントを使用できます。ただし、CTE の SELECT 句で SET_VAR ヒントを使用した場合、文が正常に実行されても SET_VAR ヒントは効果を発揮しません。
システム変数の一般的な使用法と比較して、SET_VAR ヒントはステートメントレベルで効果を発揮し、セッション全体には影響を与えません。
構文
[...] SELECT /*+ SET_VAR(key=value [, key = value]) */ ...
SUBMIT [/*+ SET_VAR(key=value [, key = value]) */] TASK ...
例
集計クエリの集計モードを指定するには、SET_VAR ヒントを使用して、集計クエリ内のシステム変数 streaming_preaggregation_mode と new_planner_agg_stage を設定します。
SELECT /*+ SET_VAR (streaming_preaggregation_mode = 'force_streaming',new_planner_agg_stage = '2') */ SUM(sales_amount) AS total_sales_amount FROM sales_orders;
SUBMIT TASK 文の実行タイムアウトを指定するには、SET_VAR ヒントを使用して、SUBMIT TASK 文内のシステム変数 insert_timeout を設定します。
SUBMIT /*+ SET_VAR(insert_timeout=3) */ TASK AS CREATE TABLE temp AS SELECT count(*) AS cnt FROM tbl1;
マテリアライズドビューを作成する際のサブクエリ実行タイムアウトを指定するには、SET_VAR ヒントを使用して、SELECT 句内のシステム変数 query_timeout を設定します。
CREATE MATERIALIZED VIEW mv
PARTITION BY dt
DISTRIBUTED BY HASH(`key`)
BUCKETS 10
REFRESH ASYNC
AS SELECT /*+ SET_VAR(query_timeout=500) */ * from dual;
ネストされたクエリでヒントを指定する:
-- メインクエリでヒントを指定するには
WITH t AS (SELECT region, sales_amount FROM sales_orders)
SELECT /*+ SET_VAR (streaming_preaggregation_mode = 'force_streaming', new_planner_agg_stage = '2') */
SUM(sales_amount) AS total_sales_amount
FROM t;
-- サブクエリでヒントを指定するには
WITH t AS (
SELECT /*+ SET_VAR (streaming_preaggregation_mode = 'force_streaming') */
region, sales_amount
FROM sales_orders
)
SELECT SUM(sales_amount) AS total_sales_amount
FROM t;
ユーザー定義変数ヒント
SET_USER_VARIABLE ヒントを使用して、SELECT 文または INSERT 文で1つ以上のユーザー定義変数を設定できます。他の文に SELECT 句が含まれている場合、その SELECT 句でも SET_USER_VARIABLE ヒントを使用できます。他の文は SELECT 文および INSERT 文であることができますが、CREATE MATERIALIZED VIEW AS SELECT 文および CREATE VIEW AS SELECT 文では使用できません。CTE の SELECT 句で SET_USER_VARIABLE ヒントを使用した場合、文が正常に実行されても SET_USER_VARIABLE ヒントは効果を発揮しません。v3.2.4 以降、StarRocks はユーザー定義変数ヒントをサポートしています。
ユーザー定義変数の一般的な使用法と比較して、SET_USER_VARIABLE ヒントはステートメントレベルで効果を発揮し、セッション全体には影響を与えません。
構文
[...] SELECT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
INSERT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
例
次の SELECT 文はスカラーサブクエリ select max(age) from users と select min(name) from users を参照しているため、SET_USER_VARIABLE ヒントを使用してこれら2つのスカラーサブクエ��リをユーザー定義変数として設定し、その後クエリを実行できます。
SELECT /*+ SET_USER_VARIABLE (@a = (select max(age) from users), @b = (select min(name) from users)) */ * FROM sales_orders where sales_orders.age = @a and sales_orders.name = @b;
Join ヒント
複数テーブルの Join クエリでは、オプティマイザは通常、最適な Join 実行方法を選択します。特別な場合には、Join ヒントを使用してオプティマイザに Join 実行方法を明示的に指示したり、Join Reorder を無効にすることができます。現在、Join ヒントは Shuffle Join、Broadcast Join、Bucket Shuffle Join、または Colocate Join を Join 実行方法として提案することをサポートしています。Join ヒントが使用されると、オプティマイザは Join Reorder を行いません。そのため、より小さいテーブルを右テーブルとして選択する必要があります。さらに、Colocate Join または Bucket Shuffle Join を Join 実行方法として提案する場合、結合されるテーブルのデータ分布がこれらの Join 実行方法の要件を満たしていることを確認してください。そうでない場合、提案された Join 実行方法は効果を発揮しません。
構文
... JOIN { [BROADCAST] | [SHUFFLE] | [BUCKET] | [COLOCATE] | [UNREORDER]} ...
Join ヒントは大文字小文字を区別しません。
例
-
Shuffle Join
テーブル A と B の同じバケッティングキー値を持つデータ行を Join 操作が行われる前に同じマシンにシャッフルする必要がある場合、Join 実行方法を Shuffle Join としてヒントを与えることができます。
select k1 from t1 join [SHUFFLE] t2 on t1.k1 = t2.k2 group by t2.k2; -
Broadcast Join
テーブル A が大きなテーブルで、テーブル B が小さなテーブルの場合、Join 実行方法を Broadcast Join としてヒントを与えることができます。テーブル B のデータは、テーブル A のデータが存在するマシンに完全にブロードキャストされ、その後 Join 操作が行われます。Shuffle Join と比較して、Broadcast Join はテーブル A のデータをシャッフルするコストを節約します。
select k1 from t1 join [BROADCAST] t2 on t1.k1 = t2.k2 group by t2.k2; -
Bucket Shuffle Join
Join クエリの Join 等値結合式にテーブル A のバケッティングキーが含まれている場合、特にテーブル A と B の両方が大きなテーブルである場合、Join 実行方法を Bucket Shuffle Join としてヒントを与えることができます。テーブル B のデータは、テーブル A のデータ分布に従って、テーブル A のデータが存在するマシンにシャッフルされ、その後 Join 操作が行われます。Broadcast Join と比較して、Bucket Shuffle Join はデータ転送を大幅に削減します。なぜなら、テーブル B のデータはグローバルに一度だけシャッフルされるからです。Bucket Shuffle Join に参加するテーブルは、非パーティション化されているか、またはコロケートされている必要があります。
select k1 from t1 join [BUCKET] t2 on t1.k1 = t2.k2 group by t2.k2; -
Colocate Join
テーブル A と B がテーブル作成時に指定された同じ Colocation Group に属している場合、テーブル A と B の同じバケッティングキー値を持つデータ行は同じ BE ノードに分散されます。Join クエリの Join 等値結合式にテーブル A と B のバケッティングキーが含まれている場合、Join 実行方法を Colocate Join としてヒントを与えることができます。同じキー値を持つデータはローカルで直接結合され、ノード間のデータ伝送にかかる時間を削減し、クエリパフォーマンスを向上させます。
select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;
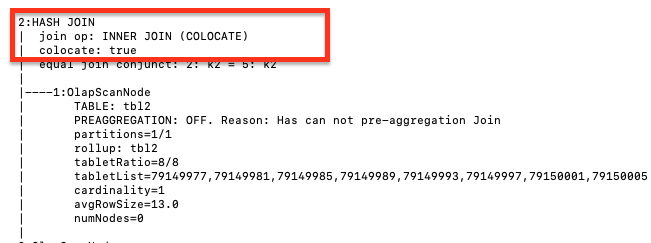
Join 実行方法の表示
EXPLAIN コマンドを使用して、実際の Join 実行方法を確認します。返された結果が Join ヒントと一致する場合、Join ヒントが効果的であることを意味します。
EXPLAIN select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;