HDFS またはクラウドストレージからデータをロードする
StarRocks は、HDFS またはクラウドストレージから大量のデータを StarRocks にロードするために、MySQL ベースの Broker Load というロード方法を提供しています。
Broker Load は非同期ロードモードで動作します。ロードジョブを送信すると、StarRocks は非同期でジョブを実行します。ジョブの結果を確認するには、SHOW LOAD ステートメントまたは curl コマンドを使用する必要があります。
Broker Load は単一テーブルロードと複数テーブルロードをサポートしています。1 つの Broker Load ジョブを実行することで、1 つまたは複数のデータファイルを 1 つまたは複数の宛先テーブルにロードできます。Broker Load は、複数のデータファイルをロードする各ロードジョブのトランザクションの原子性を保証します。原子性とは、1 つのロードジョブで複数のデータファイルをロードする際に、すべてが成功するか、すべてが失敗するかのいずれかであることを意味します。いくつかのデータファイルのロードが成功し、他のファイルのロードが失敗することはありません。
Broker Load はデータロード時のデータ変換をサポートし、データロード中に UPSERT および DELETE 操作によるデータ変更をサポートします。詳細については、Transform data at loading および Change data through loading を参照してください。
StarRocks テーブルにデータを ロード するには、その StarRocks テーブルに対して INSERT 権限を持つユーザーである必要があります。INSERT 権限を持っていない場合は、 GRANT に記載されている手順に従って、StarRocks クラスターに接続するために使用するユーザーに INSERT 権限を付与してください。構文は GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>} です。
背景情報
v2.4 以前では、StarRocks は Broker Load ジョブを実行する際に、StarRocks クラスターと外部ストレージシステムとの接続を確立するためにブローカーに依存していました。そのため、ロードステートメントで使用するブローカーを指定するために WITH BROKER "<broker_name>" を入力する必要があります。これを「ブローカー ベースのロード」と呼びます。ブローカーは、ファイルシステムインターフェースと統合された独立したステートレスサービスです。ブローカーを使用すると、StarRocks は外部ストレージシステムに保存されているデータファイルにアクセスして読み取ることができ、独自のコンピューティングリソースを使用してこれらのデータファイルのデータを事前処理してロードできます。
v2.5 以降、StarRocks は Broker Load ジョブを実行する際に、StarRocks クラスターと外部ストレージシステムとの接続を確立するためにブローカーに依存しなくなりました。そのため、ロードステートメントでブローカーを指定する必要はありませんが、WITH BROKER キーワードは保持する必要があります。これを「ブローカーフリーロード」と呼びます。
データが HDFS に保存されている場合、ブローカーフリーロードが機能しない状況に遭遇することがあります。これは、データが複数の HDFS クラスターにまたがって保存されている場合や、複数の Kerberos ユーザーが設定されている場合に発生することがあります。このような状況では、代わりにブローカー ベースのロードを使用することができます。これを成功させるには、少なくとも 1 つの独立したブローカーグループが展開されていることを確認してください。これらの状況で認証構成と HA 構成を指定する方法については、HDFS を参照してください。
サポートされているデータファイル形式
Broker Load は次のデータファイル形式をサポートしています:
-
CSV
-
Parquet
-
ORC
注意
CSV データの場合、次の点に注意してください:
- テキスト区切り文字として、長さが 50 バイトを超えない UTF-8 文字列(カンマ(,)、タブ、パイプ(|)など)を使用できます。
- Null 値は
\Nを使用して示されます。たとえば、データファイルが 3 列で構成されており、そのデータファイルのレコードが最初と 3 番目の列にデータを持ち、2 番目の列にデータがない場合、この状況では 2 番目の列に\Nを使用して Null 値を示す必要があります。つまり、レコードはa,\N,bとしてコンパイルする必要があります。a,,bは、レコードの 2 番目の列が空の文字列を持っていることを示します。
サポートされているストレージシステム
Broker Load は次のストレージシステムをサポートしています:
-
HDFS
-
AWS S3
-
Google GCS
-
MinIO などの他の S3 互換ストレージシステム
-
Microsoft Azure Storage
動作の仕組み
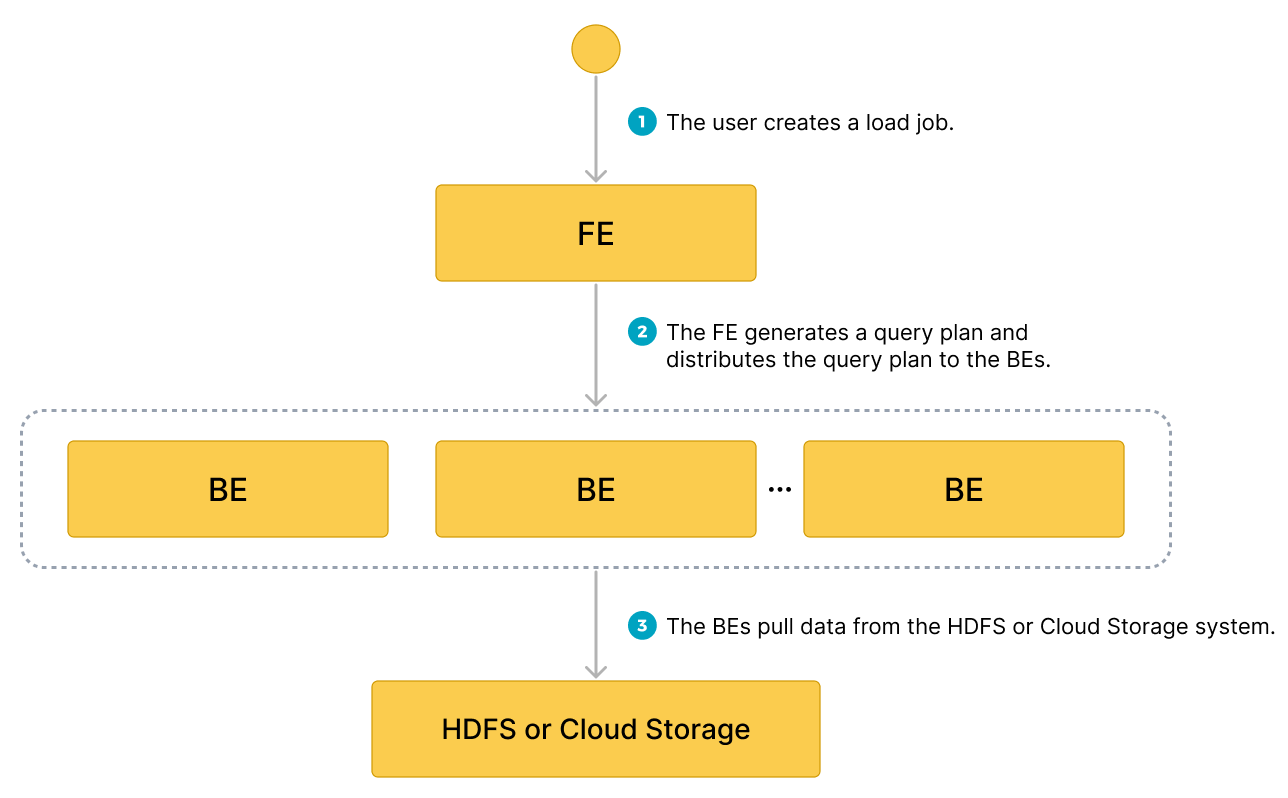
ロードジョブを FE に送信すると、FE はクエリプランを生成し、利用可能な BE の数とロードしたいデータファイルのサイズに基づいてクエリプランを分割し、クエリプランの各部分を利用可能な BE に割り当てます。ロード中、関与する各 BE は HDFS またはクラウドストレージシステムからデータファイルのデータを取得し、データを事前処理してから StarRocks クラスターにデータをロードします。すべての BE がクエリプランの部分を完了した後、FE はロードジョブが成功したかどうかを判断します。
次の図は、Broker Load ジョブのワークフローを示しています。
基本操作
複数テーブルロードジョブを作成する
このトピックでは、CSV を例にとり、複数のデータファイルを複数のテーブルにロードする方法を説明します。他のファイル形式でデータをロードする方法や Broker Load の構文とパラメーターの説明については、BROKER LOAD を参照してください。
StarRocks では、いくつかのリテラルが SQL 言語によって予約キーワードとして使用されていることに注意してください。これらのキーワードを SQL ステートメントで直接使用しないでください。SQL ステートメントでそのようなキーワードを使用する場合は、バッククォート (`) で囲んでください。Keywords を参照してください。
データ例
-
ローカルファイルシステムに CSV ファイルを作成します。
a.
file1.csvという名前の CSV ファイルを作成します。このファイルは、ユーザー ID、ユーザー名、ユーザースコアを順に表す 3 列で構成されています。1,Lily,23
2,Rose,23
3,Alice,24
4,Julia,25b.
file2.csvという名前の CSV ファイルを作成します。このファイルは、都市 ID と都市名を順に表す 2 列で構成されています。200,'Beijing' -
StarRocks データベース
test_dbに StarRocks テーブルを作成します。注意
v2.5.7 以降、StarRocks はテーブルを作成する際やパーティションを追加する際に、バケット数 (BUCKETS) を自動的に設定できます。バケット数を手動で設定する必要はありません。詳細については、set the number of buckets を参照してください。
a.
table1という名前の主キーテーブルを作成します。このテーブルは、id、name、scoreの 3 列で構成され、idが主キーです。CREATE TABLE `table1`
(
`id` int(11) NOT NULL COMMENT "user ID",
`name` varchar(65533) NULL DEFAULT "" COMMENT "user name",
`score` int(11) NOT NULL DEFAULT "0" COMMENT "user score"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`);b.
table2という名前の主キーテーブルを作成します。このテーブルは、idとcityの 2 列で構成され、idが主キーです。CREATE TABLE `table2`
(
`id` int(11) NOT NULL COMMENT "city ID",
`city` varchar(65533) NULL DEFAULT "" COMMENT "city name"
)
ENGINE=OLAP
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`); -
file1.csvとfile2.csvを HDFS クラスターの/user/starrocks/パス、AWS S3 バケットbucket_s3のinputフォルダー、Google GCS バケットbucket_gcsのinputフォルダー、MinIO バケットbucket_minioのinputフォルダー、および Azure Storage の指定されたパスにアップロードします。
HDFS からデータをロードする
次のステートメントを実行して、HDFS クラスターの /user/starrocks パスから file1.csv と file2.csv をそれぞれ table1 と table2 にロードします:
LOAD LABEL test_db.label1
(
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/starrocks/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, city)
)
WITH BROKER
(
StorageCredentialParams
)
PROPERTIES
(
"timeout" = "3600"
);
上記の例では、StorageCredentialParams は選択した認証方法に応じて異なる認証パラメーターのグループを表します。詳細については、BROKER LOAD を参照してください。
AWS S3 からデータをロードする
次のステートメントを実行して、AWS S3 バケット bucket_s3 の input フォルダーから file1.csv と file2.csv をそれぞれ table1 と table2 にロードします:
LOAD LABEL test_db.label2
(
DATA INFILE("s3a://bucket_s3/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("s3a://bucket_s3/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, city)
)
WITH BROKER
(
StorageCredentialParams
);
注意
Broker Load は S3A プロトコルに従って AWS S3 にアクセスすることのみをサポートしています。そのため、AWS S3 からデータをロードする際には、ファイルパスとして渡す S3 URI の
s3://をs3a://に置き換える必要があります。
上記の例では、StorageCredentialParams は選択した認証方法に応じて異なる認証パラメーターのグループを表します。詳細については、BROKER LOAD を参照してください。
v3.1 以降、StarRocks は Parquet 形式または ORC 形式のファイルのデータを AWS S3 から直接ロードすることをサポートしており、INSERT コマンドと TABLE キーワードを使用することで、外部テーブルを最初に作成する手間を省くことができます。詳細については、Load data using INSERT > Insert data directly from files in an external source using TABLE keyword を参照してください。
Google GCS からデータをロードする
次のステートメントを実行して、Google GCS バケット bucket_gcs の input フォルダーから file1.csv と file2.csv をそれぞれ table1 と table2 にロードします:
LOAD LABEL test_db.label3
(
DATA INFILE("gs://bucket_gcs/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("gs://bucket_gcs/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, city)
)
WITH BROKER
(
StorageCredentialParams
);
注意
Broker Load は Google GCS に gs プロトコルに従ってアクセスすることのみをサポートしています。そのため、Google GCS からデータをロードする際には、ファイルパスとして渡す GCS URI に
gs://を含める必要があります。
上記の例では、StorageCredentialParams は選択した認証方法に応じて異なる認証パラメーターのグループを表します。詳細については、BROKER LOAD を参照してください。
他の S3 互換ストレージシステムからデータをロードする
MinIO を例にとります。次のステートメントを実行して、MinIO バケット bucket_minio の input フォルダーから file1.csv と file2.csv をそれぞれ table1 と table2 にロードします:
LOAD LABEL test_db.label7
(
DATA INFILE("s3://bucket_minio/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("s3://bucket_minio/input/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, city)
)
WITH BROKER
(
StorageCredentialParams
);
上記の例では、StorageCredentialParams は選択した認証方法に応じて異なる認証パラメーターのグループを表します。詳細については、BROKER LOAD を参照してください。
Microsoft Azure Storage からデータをロードする
次のステートメントを実行して、Azure Storage の指定されたパスから file1.csv と file2.csv をロードします:
LOAD LABEL test_db.label8
(
DATA INFILE("wasb[s]://<container>@<storage_account>.blob.core.windows.net/<path>/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
(id, name, score)
,
DATA INFILE("wasb[s]://<container>@<storage_account>.blob.core.windows.net/<path>/file2.csv")
INTO TABLE table2
COLUMNS TERMINATED BY ","
(id, city)
)
WITH BROKER
(
StorageCredentialParams
);
注意
Azure Storage からデータをロードする際には、使用するアクセスプロトコルと特定のストレージサービスに基づいて、どのプレフィックスを使用するかを決定する必要があります。上記の例では、Blob Storage を例にとっています。
- Blob Storage からデータをロードする場合、ストレージアカウントにアクセスするために使用されるプロトコルに基づいて、ファイルパスに
wasb://またはwasbs://をプレフィックスとして含める必要があります:
- Blob Storage が HTTP 経由でのみアクセスを許可する場合、プレフィックスとして
wasb://を使用します。例:wasb://<container>@<storage_account>.blob.core.windows.net/<path>/<file_name>/*。- Blob Storage が HTTPS 経由でのみアクセスを許可する場合、プレフィックスとして
wasbs://を使用します。例:wasbs://<container>@<storage_account>.blob.core.windows.net/<path>/<file_name>/*- Data Lake Storage Gen1 からデータをロードする場合、ファイルパスに
adl://をプレフィックスとして含める必要があります。例:adl://<data_lake_storage_gen1_name>.azuredatalakestore.net/<path>/<file_name>。- Data Lake Storage Gen2 からデータをロードする場合、ストレージアカウントにアクセスするために使用されるプロトコルに基づいて、ファイルパスに
abfs://またはabfss://をプレフィックスとして含める必要があります:
- Data Lake Storage Gen2 が HTTP 経由でのみアクセスを許可する場合、プレフィックスとして
abfs://を使用します。例:abfs://<container>@<storage_account>.dfs.core.windows.net/<file_name>。- Data Lake Storage Gen2 が HTTPS 経由でのみアクセスを許可する場合、プレフィックスとして
abfss://を使用します。例:abfss://<container>@<storage_account>.dfs.core.windows.net/<file_name>。
上記の例では、StorageCredentialParams は選択した認証方法に応じて異なる認証パラメーターのグループを表します。詳細については、BROKER LOAD を参照してください。
データをクエリする
HDFS クラスター、AWS S3 バケット、または Google GCS バケットからのデータのロードが完了した後、SELECT ステートメントを使用して StarRocks テーブルのデータをクエリし、ロードが成功したかどうかを確認できます。
-
次のステートメントを実行して、
table1のデータをクエリします:MySQL [test_db]> SELECT * FROM table1;
+------+-------+-------+
| id | name | score |
+------+-------+-------+
| 1 | Lily | 23 |
| 2 | Rose | 23 |
| 3 | Alice | 24 |
| 4 | Julia | 25 |
+------+-------+-------+
4 rows in set (0.00 sec) -
次のステートメントを実行して、
table2のデータをクエリします:MySQL [test_db]> SELECT * FROM table2;
+------+--------+
| id | city |
+------+--------+
| 200 | Beijing|
+------+--------+
4 rows in set (0.01 sec)
単一テーブルロードジョブを作成する
単一のデータファイルまたは指定されたパスからすべてのデータファイルを単一の宛先テーブルにロードすることもできます。AWS S3 バケット bucket_s3 に input という名前のフォルダーが含まれているとします。この input フォルダーには、file1.csv という名前のデータファイルを含む複数のデータファイルが含まれています。これらのデータファイルは table1 と同じ数の列で構成されており、これらのデータファイルの各列は table1 の列と順番に一対一でマッピングできます。
file1.csv を table1 にロードするには、次のステートメントを実行します:
LOAD LABEL test_db.label_7
(
DATA INFILE("s3a://bucket_s3/input/file1.csv")
INTO TABLE table1
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
)
WITH BROKER
(
StorageCredentialParams
);
input フォルダーからすべてのデータファイルを table1 にロードするには、次のステートメントを実行します:
LOAD LABEL test_db.label_8
(
DATA INFILE("s3a://bucket_s3/input/*")
INTO TABLE table1
COLUMNS TERMINATED BY ","
FORMAT AS "CSV"
)
WITH BROKER
(
StorageCredentialParams
);
上記の例では、StorageCredentialParams は選択した認証方法に応じて異なる認証パラメーターのグループを表します。詳細については、BROKER LOAD を参照してください。
ロードジョブを表示する
Broker Load を使用すると、SHOW LOAD ステートメントまたは curl コマンドを使用してロードジョブを表示できます。
SHOW LOAD を使用する
詳細については、SHOW LOAD を参照してください。
curl を使用する
構文は次のとおりです:
curl --location-trusted -u <username>:<password> \
'http://<fe_host>:<fe_http_port>/api/<database_name>/_load_info?label=<label_name>'
注意
パスワードが設定されていないアカウントを使用する場合、
<username>:のみを入力する必要があります。
たとえば、次のコマンドを実行して、test_db データベース内のラベルが label1 のロードジョブに関する情報を表示できます:
curl --location-trusted -u <username>:<password> \
'http://<fe_host>:<fe_http_port>/api/test_db/_load_info?label=label1'
curl コマンドは、指定されたラベルを持つ最も最近実行されたロードジョブに関する情報を JSON オブジェクト jobInfo として返します:
{"jobInfo":{"dbName":"default_cluster:test_db","tblNames":["table1_simple"],"label":"label1","state":"FINISHED","failMsg":"","trackingUrl":""},"status":"OK","msg":"Success"}%
次の表は、jobInfo のパラメーターを説明しています。
| パラメーター | 説明 |
|---|---|
| dbName | データがロードされるデータベースの名前 |
| tblNames | データがロードされるテーブルの名前。 |
| label | ロードジョブのラベル。 |
| state | ロードジョブのステータス。 有効な値:
|
| failMsg | ロードジョブが失敗した理由。ロードジョブの state 値が PENDING、LOADING、または FINISHED の場合、failMsg パラメーターには NULL が返されます。ロードジョブの state 値が CANCELLED の場合、failMsg パラメーターに返される値は type と msg の 2 つの部分で構成されます:
|
| trackingUrl | ロードジョブで検出された不合格データにアクセスするために使用される URL。curl または wget コマンドを使用して URL にアクセスし、不合格データを取得できます。不合格データが検出されない場合、trackingUrl パラメーターには NULL が返されます。 |
| status | ロードジョブの HTTP リクエストのステータス。 有効な値:OK および Fail。 |
| msg | ロードジョブの HTTP リクエストのエラー情報。 |
ロードジョブをキャンセルする
ロードジョブが CANCELLED または FINISHED ステージにない場合、CANCEL LOAD ステートメントを使用してジョブをキャンセルできます。
たとえば、次のステートメントを実行して、データベース test_db 内のラベルが label1 のロードジョブをキャンセルできます:
CANCEL LOAD
FROM test_db
WHERE LABEL = "label";
ジョブの分割と並行実行
Broker Load ジョブは、1 つ以上のタスクに分割され、並行して実行されます。ロードジョブ内のタスクは単一のトランザクション内で実行されます。すべて成功するか、すべて失敗する必要があります。StarRocks は、LOAD ステートメントで data_desc を宣言する方法に基づいて、各ロードジョブを分割します:
-
複数の
data_descパラメーターを宣言し、それぞれが異なるテーブルを指定している場合、各テーブルのデータをロードするタスクが生成されます。 -
複数の
data_descパラメーターを宣言し、それぞれが同じテーブルの異なるパーティションを指定している場合、各パーティションのデータをロードするタスクが生成されます。
さらに、各タスクは 1 つ以上のインスタンスにさらに分割され、StarRocks クラスターの BE に均等に分散され、並行して実行されます。StarRocks は次の FE 設定 に基づいて各タスクを分割します:
-
min_bytes_per_broker_scanner: 各インスタンスによって処理されるデータの最小量。デフォルトは 64 MB です。 -
load_parallel_instance_num: 個々の BE で各ロードジョブに許可される並行インスタンスの数。デフォルトは 1 です。個々のタスク内のインスタンスの数を計算するには、次の式を使用できます:
個々のタスク内のインスタンスの数 = min(個々のタスクによってロードされるデータ量/
min_bytes_per_broker_scanner,load_parallel_instance_numx BE の数)
ほとんどの場合、各ロードジョブには 1 つの data_desc のみが宣言され、各ロードジョブは 1 つのタスクにのみ分割され、そのタスクは BE の数と同じ数のインスタンスに分割されます。
関連する設定項目
FE 設定項目 max_broker_load_job_concurrency は、StarRocks クラスター内で同時に実行できる Broker Load ジョブの最大数を指定します。
StarRocks v2.4 以前では、特定の期間内に送信された Broker Load ジョブの総数が最大数を超える場合、過剰なジョブはキューに入り、送信時間に基づいてスケジュールされます。
StarRocks v2.5 以降、特定の期間内に送信された Broker Load ジョブの総数が最大数を超える場合、過剰なジョブは優先順位に基づいてキューに入り、スケジュールされます。ジョブ作成時に priority パラメーターを使用してジョブの優先順位を指定できます。BROKER LOAD を参照してください。また、ALTER LOAD を使用して、QUEUEING または LOADING 状態にある既存のジョブの優先順位を変更することもできます。