テーブル概要
テーブルはデータストレージの単位です。StarRocks におけるテーブル構造を理解し、効率的なテーブル構造を設計することは、データの整理を最適化し、クエリ効率を向上させるのに役立ちます。また、従来のデータベースと比較して、StarRocks は JSON や ARRAY などの複雑な半構造化データをカラム形式で保存し、クエリパフォーマンスを向上させることができます。
このトピックでは、StarRocks のテーブル構造を基本的かつ一般的な視点から紹介します。
基本的なテーブル構造の入門
他のリレーショナルデータベースと同様に、テーブルは論理的に行と列で構成されています。
- 行: 各行は1つのレコードを保持します。各行には関連するデータ値のセットが含まれています。
- 列: 列は各レコードの属性を定義します。各列は特定の属性のデータを保持します。例えば、従業員テーブルには、名前、従業員ID、部署、給与などの列が含まれることがあり、各列は対応するデータを保存します。各列のデータは同じデータ型です。テーブル内のすべての行は同じ数の列を持っています。
StarRocks でテーブルを作成するのは簡単です。CREATE TABLE ステートメントで列とそのデータ型を定義するだけでテーブルを作成できます。例:
CREATE DATABASE example_db;
USE example_db;
CREATE TABLE user_access (
uid int,
name varchar(64),
age int,
phone varchar(16),
last_access datetime,
credits double
)
DUPLICATE KEY(uid, name);
上記の CREATE TABLE の例は、重複キーテーブルを作成します。このタイプのテーブルには列に制約が追加されないため、重複したデータ行がテーブルに存在することができます。重複キーテーブルの最初の2つの列はソート列として指定され、ソートキーを形成します。データはソートキーに基づいてソートされた後に保存され、クエリ時のインデックス作成を加速できます。
If a StarRocks cluster in a staging environment contains only one BE, the number of replicas can be set to 1 in the PROPERTIES clause, such as PROPERTIES( "replication_num" = "1" ). The default number of replicas is 3, which is also the number recommended for production StarRocks clusters. If you want to use the default number, you do not need to configure the replication_num parameter.
DESCRIBE を実行してテーブルスキーマを表示します。
MySQL [test]> DESCRIBE user_access;
+-------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-------+---------+-------+
| uid | int | YES | true | NULL | |
| name | varchar(64) | YES | true | NULL | |
| age | int | YES | false | NULL | |
| phone | varchar(16) | YES | false | NULL | |
| last_access | datetime | YES | false | NULL | |
| credits | double | YES | false | NULL | |
+-------------+-------------+------+-------+---------+-------+
6 rows in set (0.00 sec)
SHOW CREATE TABLE を実行して CREATE TABLE ステートメントを表示します。
MySQL [example_db]> SHOW CREATE TABLE user_access\G
*************************** 1. row ***************************
Table: user_access
Create Table: CREATE TABLE `user_access` (
`uid` int(11) NULL COMMENT "",
`name` varchar(64) NULL COMMENT "",
`age` int(11) NULL COMMENT "",
`phone` varchar(16) NULL COMMENT "",
`last_access` datetime NULL COMMENT "",
`credits` double NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY RANDOM
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"enable_persistent_index" = "false",
"replicated_storage" = "true",
"compression" = "LZ4"
);
1 row in set (0.00 sec)
包括的なテーブル構造の理解
StarRocks のテーブル構造を深く理解することで、ビジネスニーズに合わせた効率的なデータ管理構造を設計することができます。
テーブルタイプ
StarRocks は、重複キーテーブル、主キーテーブル、集計テーブル、ユニークキーテーブルの4種類のテーブルを提供し、生データ、頻繁に更新されるリアルタイムデータ、集計データなど、さまざまなビジネスシナリオに対応したデータを保存します。
- 重複キーテーブルはシンプルで使いやすいです。このタイプのテーブルには列に制約が追加されないため、重複したデータ行がテーブルに存在することができます。重複キーテーブルは、制約や事前集計が不要なログなどの生データの保存に適しています。
- 主キーテーブルは強力です。主キー列には一意性と非NULL制約が追加されます。主キーテーブルはリアルタイムの頻繁な更新と部分的な列の更新をサポートし、高いクエリパフォーマンスを確保するため、リアルタイムクエリシナリオに適しています。
- 集計テーブルは事前集計されたデータを保存するのに適しており、スキャンおよび計算されるデータ量を削減し、集計クエリの効率を向上させます。
- ユニークテーブルも頻繁に更新されるリアルタイムデータの保存に適しています。ただし、このタイプのテーブルは、より強力な主キーテーブルに置き換えられつつあります。
データ分散
StarRocks は、パーティション化+バケッティングの2層データ分散戦略を使用して、データを BEs に均等に分散します。よく設計されたデータ分散戦略は、スキャンされるデータ量を効果的に削減し、StarRocks の並列処理能力を最大化し、クエリパフォーマンスを向上させます。
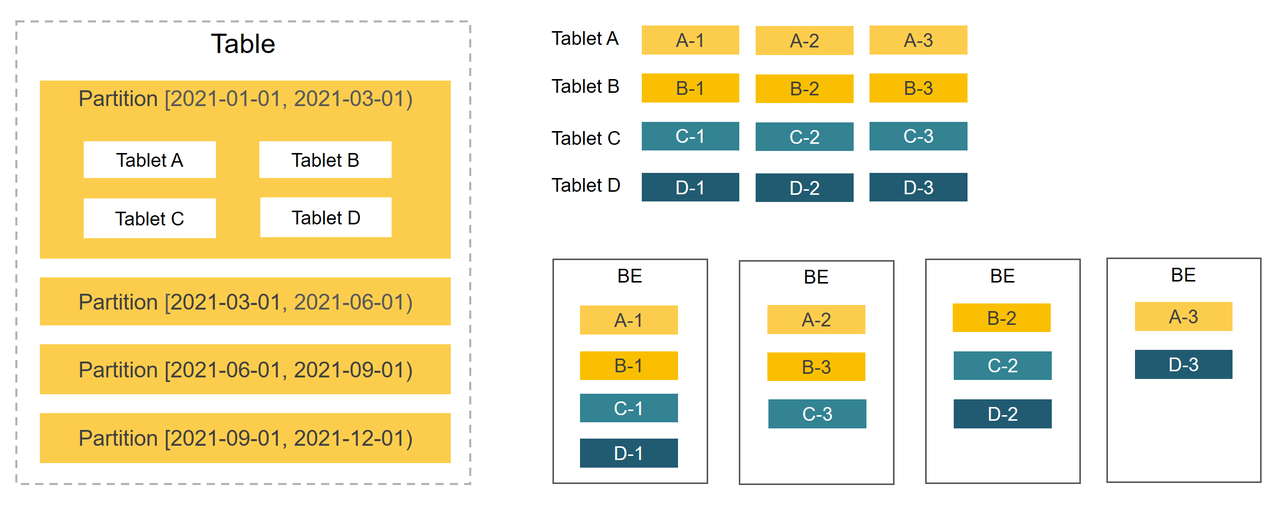
パーティション化
最初のレベルはパーティション化です。テーブル内のデータは、通常、日付や時間を保持するパーティション列に基づいて小さなデータ管理単位に分割できます。クエリ中に、パーティションプルーニングはスキャンする必要のあるデータ量を削減し、クエリパフォーマンスを効果的に最適化します。
StarRocks は、使いやすいパーティション化の手法である式に基づくパーティション化を提供し、範囲やリストパーティション化など、より柔軟な手法も提供しています。
バケッティング
2番目のレベルはバケッティングです。パーティション内のデータはさらにバケッティングを通じて小さなデータ管理単位に分割されます。各バケットのレプリカは BEs に均等に分散され、高いデータ可用性を確保します。
StarRocks は2つのバケッティング手法を提供しています。
- ハッシュバケッティング: バケッティングキーのハッシュ値に基づいてデータをバケットに分配します。クエリで条件列として頻繁に使用される列をバケッティング列として選択することで、クエリ効率を向上させます。
- ランダムバケット法: データをランダムにバケットに分配します。このバケッティング手法はよりシンプルで使いやすいです。
データ型
NUMERIC、DATE、STRING などの基本的なデータ型に加えて、StarRocks は ARRAY、JSON、MAP、STRUCT などの複雑な半構造化データ型をサポートしています。
インデックス
インデックスは特別なデータ構造であり、テーブル内のデータへのポインタとして使用されます。クエリの条件列がインデックス列である場合、StarRocks は条件を満たすデータを迅速に特定できます。
StarRocks は組み込みのインデックスを提供しています: プレフィックスインデックス、オーディナルインデックス、ゾーンマップインデックス。StarRocks はまた、ユーザーがインデックスを作成することを許可しており、ビットマップインデックスやブルームフィルターインデックスを作成してクエリ効率をさらに向上させることができます。
制約
制約はデータの整合性、一貫性、正確性を確保するのに役立ちます。主キーテーブルの主キー列は一意で NULL でない値を持たなければなりません。集計テーブルの集計キー列とユニークキーテーブルのユニークキー列は一意の値を持たなければなりません。
その他の機能
上記の機能に加えて、ビジネス要件に基づいてより堅牢なテーブル構造を設計するために、さらに多くの機能を採用することができます。例えば、ビットマップや HLL 列を使用して重複排除カウントを加速したり、生成列や自動インクリメント列を指定して一部のクエリを高速化したり、柔軟で自動的なストレージクールダウン手法を設定してメンテナンスコストを削減したり、Colocate Join を設定してマルチテーブル JOIN クエリを高速化したりすることができます。詳細については、CREATE TABLE を参照してください。