データロードの概要
データロードは、さまざまなデータソースからの生データをビジネス要件に基づいてクレンジングおよび変換し、その結果を StarRocks にロードして、高速なデータ分析を可能にするプロセスです。
データを StarRocks にロードするには、ロードジョブを実行します。各ロードジョブには、ユーザーが指定するか StarRocks が自動生成する一意のラベルがあり、ジョブを識別します。各ラベルは 1 つのロードジョブにのみ使用できます。ロードジョブが完了すると、そのラベルは他のロードジョブには再利用できません。失敗したロードジョブのラベルのみが再利用可能です。このメカニズムにより、特定のラベルに関連付けられたデータが一度だけロードされることが保証され、At-Most-Once セマンティクスが実現されます。
StarRocks が提供するすべてのロード方法は原子性を保証できます。原子性とは、ロードジョブ内の適格なデータがすべて正常にロードされるか、まったくロードされないことを意味します。適格なデータの一部がロードされ、他のデータがロードされないということはありません。適格なデータには、データ型変換エラーなどの品質問題のためにフィルタリングされたデータは含まれません。
StarRocks は、ロードジョブを送信するために使用できる 2 つの通信プロトコルをサポートしています: MySQL と HTTP。各ロード方法でサポートされているプロトコルの詳細については、このトピックの Loading methods セクションを参照してください。
StarRocks テーブルにデータを ロード できるのは、これらの StarRocks テーブルに対して INSERT 権限を持つユーザーのみです。INSERT 権限を持っていない場合は、 GRANT に記載されている手順に従って、StarRocks クラスターに接続するために使用するユーザーに INSERT 権限を付与してください。
サポートされているデータ型
StarRocks はすべてのデータ型のデータロードをサポートしています。いくつかの特定のデータ型のロードに関する制限に注意するだけで済みます。詳細については、Data types を参照してください。
ロードモード
StarRocks は 2 つのロードモードをサポートしています: 同期ロードモードと非同期ロードモード。
NOTE
外部プログラムを使用してデータをロードする場合、ビジネス要件に最適なロードモードを選択してから、ロード方法を決定する必要があります。
同期ロード
同期ロードモードでは、ロードジョブを送信した後、StarRocks はジョブを同期的に実行してデータをロードし、ジョブが終了した後にジョブの結果を返します。ジョブの結果に基づいて、ジョブが成功したかどうかを確認できます。
StarRocks は、同期ロードをサポートする 2 つのロード方法を提供しています: Stream Load と INSERT。
同期ロードのプロセスは次のとおりです。
-
ロードジョブを作成します。
-
StarRocks によって返されたジョブ結果を確認します。
-
ジョブ結果に基づいてジョブが成功したかどうかを確認します。ジョブ結果がロード失敗を示している場合、ジョブを再試行できます。
非同期ロード
非同期ロードモードでは、ロードジョブを送信した後、StarRocks はすぐにジョブ作成結果を返します。
-
結果がジョブ作成の成功を示している場合、StarRocks はジョブを非同期で実行します。ただし、それはデータが正常にロードされたことを意味しません。ジョブのステータスを確認するためにステートメントやコマンドを使用する必要があります。その後、ジョブのステータスに基づいてデータが正常にロードされたかどうかを判断できます。
-
結果がジョブ作成の失敗を示している場合、失敗情報に基づいてジョブを再試行する必要があるかどうかを判断できます。
StarRocks は、非同期ロードをサポートする 3 つのロード方法を提供しています: Broker Load、Routine Load、および Spark Load。
非同期ロードのプロセスは次のとおりです。
-
ロードジョブを作成します。
-
StarRocks によって返されたジョブ作成結果を確認し、ジョブが正常に作成されたかどうかを判断します。 a. ジョブ作成が成功した場合、ステップ 3 に進みます。 b. ジョブ作成が失敗した場合、ステップ 1 に戻ります。
-
ジョブのステータスが FINISHED または CANCELLED になるまで、ステートメントやコマンドを使用してジョブのステータスを確認します。
Broker Load または Spark Load ジョブのワークフローは、次の図に示すように 5 つのステージで構成されています。
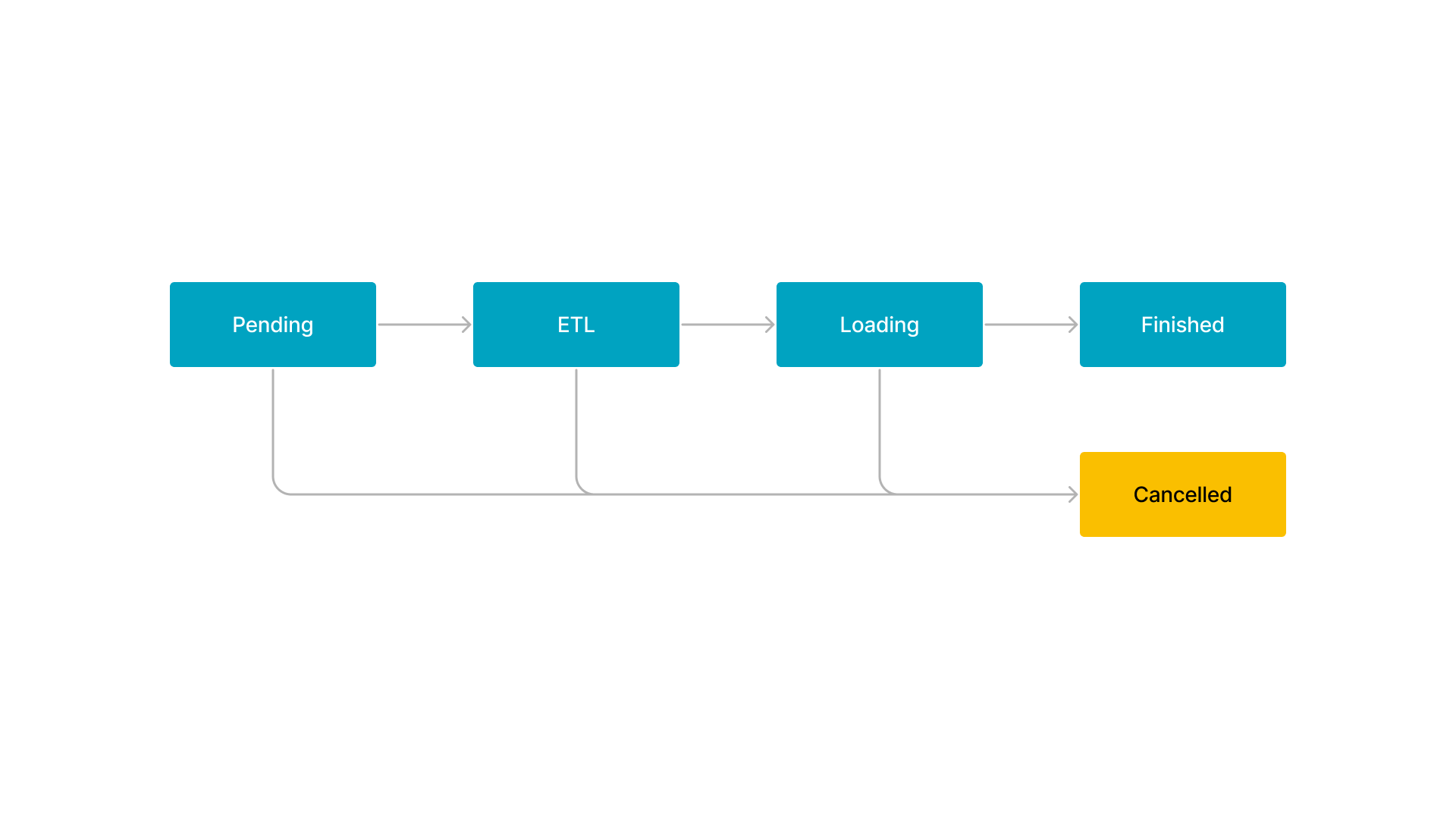
ワークフローは次のように説明されます。
-
PENDING
ジョブは FE によってスケジュールされるのを待っているキューにあります。
-
ETL
FE はデータを前処理し、クレンジング、パーティショニング、ソート、および集計を行います。
NOTE
ジョブが Broker Load ジョブの場合、このステージは直接終了します。
-
LOADING
FE はデータをクレンジングおよび変換し、データを BEs に送信します。すべてのデータがロードされた後、データは効果を発揮するのを待っているキューにあります。この時点で、ジョブのステータスは LOADING のままです。
-
FINISHED
すべてのデータが効果を発揮すると、ジョブのステータスは FINISHED になります。この時点で、データをクエリできます。FINISHED は最終的なジョブ状態です。
-
CANCELLED
ジョブのステータスが FINISHED になる前に、いつでもジョブをキャンセルできます。さらに、StarRocks はロードエラーが発生した場合に自動的にジョブをキャンセルできます。ジョブがキャンセルされると、ジョブのステータスは CANCELLED になります。CANCELLED も最終的なジョブ状態です。
Routine ジョブのワークフローは次のように説明されます。
-
ジョブは MySQL クライアントから FE に送信されます。
-
FE はジョブを複数のタスクに分割します。各タスクは複数のパーティションからデータをロードするように設計されています。
-
FE はタスクを指定された BEs に配布します。
-
BEs はタスクを実行し、タスクが完了した後に FE に報告します。
-
FE は後続のタスクを生成し、失敗したタスクがある場合は再試行し、BEs からの報告に基づいてタスクのスケジューリングを一時停止します。
ロード方法
StarRocks は、さまざまなビジネスシナリオでデータをロードするための 5 つのロード方法を提供しています: Stream Load、Broker Load、Routine Load、Spark Load、および INSERT。
| ロード方法 | データソース | ビジネスシナリオ | ロードジョブごとのデータ量 | データファイル形式 | ロードモード | プロトコル |
|---|---|---|---|---|---|---|
| Stream Load |
| ローカルファイルシステムからデータファイルをロードするか、プログラムを使用してデータストリームをロードします。 | 10 GB 以下 |
| 同期 | HTTP |
| Broker Load |
| HDFS またはクラウドストレージからデータをロードします。 | 数十 GB から数百 GB |
| 非同期 | MySQL |
| Routine Load | Apache Kafka® | Kafka からリアルタイムでデータをロードします。 | MB から GB のデータをミニバッチとしてロードします。 |
| 非同期 | MySQL |
| Spark Load |
|
| 数十 GB から TB |
| 非同期 | MySQL |
| INSERT INTO SELECT |
AWS S3 からデータをロードする場合、Parquet 形式または ORC 形式のファイルのみがサポートされます。 |
| 固定されていません(データ量はメモリサイズに基づいて変動します。) | StarRocks テーブル | 同期 | MySQL |
| INSERT INTO VALUES |
|
| 少量 | SQL | 同期 | MySQL |
ビジネスシナリオ、データ量、データソース、データファイル形式、ロード頻度に基づいて、選択するロード方法を決定できます。さらに、ロード方法を選択する際には、次の点に注意してください。
-
Kafka からデータをロードする場合、Routine Load を使用することをお勧めします。ただし、データがマルチテーブルジョインや ETL 操作を必要とする場合、Apache Flink® を使用して Kafka からデータを読み取り、前処理を行い、その後 flink-connector-starrocks を使用してデータを StarRocks にロードできます。
-
Hive、Iceberg、Hudi、または Delta Lake からデータをロードする場合、Hive catalog、Iceberg catalog、Hudi Catalog、または Delta Lake Catalog を作成し、その後 INSERT を使用してデータをロードすることをお勧めします。
-
別の StarRocks クラスターまたは Elasticsearch クラスターからデータをロードする場合、StarRocks external table または Elasticsearch external table を作成し、その後 INSERT を使用してデータをロードすることをお勧めします。
NOTICE
StarRocks external tables はデータの書き込みのみをサポートします。データの読み取りはサポートしていません。
-
MySQL データベースからデータをロードする場合、MySQL external table を作成し、その後 INSERT を使用してデータをロードすることをお勧めします。リアルタイムでデータをロードしたい場合は、Realtime synchronization from MySQL に記載されている手順に従ってデータをロードすることをお勧めします。
-
Oracle、PostgreSQL、SQL Server などの他のデータソースからデータをロードする場合、JDBC external table を作成し、その後 INSERT を使用してデータをロードすることをお勧めします。
次の図は、StarRocks がサポートするさまざまなデータソースと、これらのデータソースからデータをロードするために使用できるロード方法の概要を示しています。
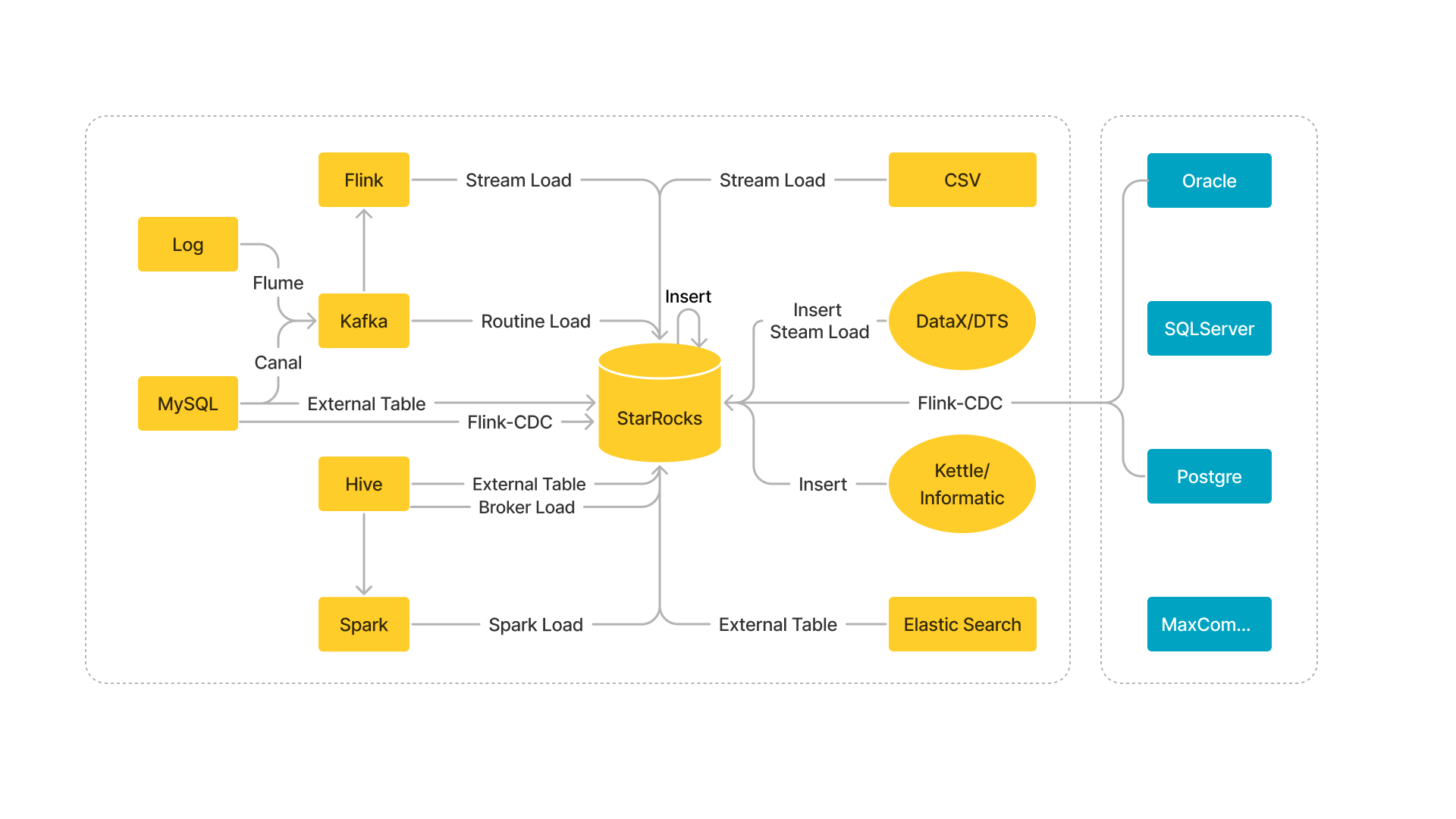
メモリ制限
StarRocks は、各ロードジョブのメモリ使用量を制限するためのパラメータを提供し、特に高い同時実行性のシナリオでメモリ消費を削減します。ただし、過度に低いメモリ使用量制限を指定しないでください。メモリ使用量制限が過度に低い場合、ロードジョブのメモリ使用量が指定された制限に達するため、データが頻繁にメモリからディスクにフラッシュされる可能性があります。ビジネスシナリオに基づいて適切なメモリ使用量制限を指定することをお勧めします。
メモリ使用量を制限するために使用されるパラメータは、各ロード方法によって異なります。詳細については、Stream Load、Broker Load、Routine Load、Spark Load、および INSERT を参照してください。ロードジョブは通常、複数の BEs で実行されるため、パラメータは関与する各 BE での各ロードジョブのメモリ使用量を制限し、すべての関与する BEs でのロードジョブの総メモリ使用量を制限するものではありません。
StarRocks はまた、各個別の BE で実行されるすべてのロードジョブの総メモリ使用量を制限するためのパラメータを提供しています。詳細については、このトピックの "System configurations" セクションを参照してください。
使用上の注意
ロード中に宛先列を自動的に埋める
データをロードする際、データファイルの特定のフィールドからデータをロードしないことを選択できます。
-
StarRocks テーブルを作成する際に、ソースフィールドにマッピングされる宛先 StarRocks テーブル列に
DEFAULTキーワードを指定した場合、StarRocks は指定されたデフォルト値を宛先列に自動的に埋めます。Stream Load、Broker Load、Routine Load、および INSERT は、
DEFAULT current_timestamp、DEFAULT <default_value>、およびDEFAULT (<expression>)をサポートしています。Spark Load はDEFAULT current_timestampとDEFAULT <default_value>のみをサポートしています。NOTE
DEFAULT (<expression>)は、関数uuid()およびuuid_numeric()のみをサポートしています。 -
StarRocks テーブルを作成する際に、ソースフィールドにマッピングされる宛先 StarRocks テーブル列に
DEFAULTキーワードを指定しなかった場合、StarRocks は宛先列にNULLを自動的に埋めます。NOTE
宛先列が
NOT NULLと定義されている場合、ロードは失敗します。Stream Load、Broker Load、Routine Load、および Spark Load では、列マッピングを指定するために使用されるパラメータを使用して、宛先列に埋めたい値を指定することもできます。
NOT NULL および DEFAULT の使用法については、CREATE TABLE を参照してください。
データロードのための書き込みクォーラムを設定する
StarRocks クラスターに複数のデータレプリカがある場合、テーブルに対して異なる書き込みクォーラムを設定できます。つまり、StarRocks がロードタスクを成功と判断する前に、ロード成功を返す必要があるレプリカの数を指定できます。CREATE TABLE 時に write_quorum プロパティを追加するか、ALTER TABLE を使用して既存のテーブルにこのプロパティを追加できます。このプロパティは v2.5 からサポートされています。
システム構成
このセクションでは、StarRocks が提供するすべてのロード方法に適用されるいくつかのパラメータ構成について説明します。
FE 構成
各 FE の構成ファイル fe.conf で次のパラメータを構成できます。
-
max_load_timeout_secondおよびmin_load_timeout_secondこれらのパラメータは、各ロードジョブの最大タイムアウト期間と最小タイムアウト期間を指定します。タイムアウト期間は秒単位で測定されます。デフォルトの最大タイムアウト期間は 3 日間で、デフォルトの最小タイムアウト期間は 1 秒です。指定する最大タイムアウト期間と最小タイムアウト期間は、1 秒から 3 日間の範囲内でなければなりません。これらのパラメータは、同期ロードジョブと非同期ロードジョブの両方に有効です。
-
desired_max_waiting_jobsこのパラメータは、キューで待機中のロードジョブの最大数を指定します。デフォルト値は 1024 です(v2.4 以前では 100、v2.5 以降では 1024)。FE 上の PENDING 状態のロードジョブの数が指定した最大数に達すると、FE は新しいロード要求を拒否します。このパラメータは非同期ロードジョブにのみ有効です。
-
max_running_txn_num_per_dbこのパラメータは、StarRocks クラスターの各データベースで許可される進行中のロードトランザクションの最大数を指定します。ロードジョブは 1 つ以上のトランザクションを含むことができます。デフォルト値は 100 です。データベースで実行中のロードトランザクションの数が指定した最大数に達すると、送信した後続のロードジョブはスケジュールされません。この状況では、同期ロードジョブを送信すると、ジョブは拒否されます。非同期ロードジョブを送信すると、ジョブはキューで待機します。
NOTE
StarRocks はすべてのロードジョブを一緒にカウントし、同期ロードジョブと非同期ロードジョブを区別しません。
-
label_keep_max_secondこのパラメータは、FINISHED または CANCELLED 状態のロードジョブの履歴記録の保持期間を指定します。デフォルトの保持期間は 3 日間です。このパラメータは、同期ロードジョブと非同期ロードジョブの両方に有効です。
BE 構成
各 BE の構成ファイル be.conf で次のパラメータを構成できます。
-
write_buffer_sizeこのパラメータは、最大メモリブロックサイズを指定します。デフォルトサイズは 100 MB です。ロードされたデータは最初に BE 上のメモリブロックに書き込まれます。ロードされたデータの量が指定した最大メモリブロックサイズに達すると、データはディスクにフラッシュされます。ビジネスシナリオに基づいて適切な最大メモリブロックサイズを指定する必要があります。
- 最大メモリブロックサイズが非常に小さい場合、BE 上に多数の小さなファイルが生成される可能性があります。この場合、クエリパフォーマンスが低下します。生成されるファイルの数を減らすために、最大メモリブロックサイズを増やすことができます。
- 最大メモリブロックサイズが非常に大きい場合、リモートプロシージャコール (RPC) がタイムアウトする可能性があります。この場合、ビジネスニーズに基づいてこのパラメータの値を調整できます。
-
streaming_load_rpc_max_alive_time_sec各 Writer プロセスの待機タイムアウト期間。デフォルト値は 600 秒です。データロードプロセス中、StarRocks は各タブレットにデータを受信し、データを書き込むために Writer プロセスを開始します。指定した待機タイムアウト期間内に Writer プロセスがデータを受信しない場合、StarRocks は Writer プロセスを停止します。StarRocks クラスターが低速でデータを処理する場合、Writer プロセスは次のデータバッチを長時間受信せず、「TabletWriter add batch with unknown id」エラーを報告する可能性があります。この場合、このパラメータの値を増やすことができます。
-
load_process_max_memory_limit_bytesおよびload_process_max_memory_limit_percentこれらのパラメータは、各個別の BE でのすべてのロードジョブに対して消費されるメモリの最大量を指定します。StarRocks は、2 つのパラメータの値のうち、より小さいメモリ消費量を許可される最終的なメモリ消費量として識別します。
-
load_process_max_memory_limit_bytes: 最大メモリサイズを指定します。デフォルトの最大メモリサイズは 100 GB です。 -
load_process_max_memory_limit_percent: 最大メモリ使用量を指定します。デフォルト値は 30% です。このパラメータはmem_limitパラメータとは異なります。mem_limitパラメータは StarRocks クラスターの総最大メモリ使用量を指定し、デフォルト値は 90% x 90% です。BE が存在するマシンのメモリ容量が M の場合、ロードジョブに消費されるメモリの最大量は次のように計算されます:
M x 90% x 90% x 30%。
-
システム変数構成
次の system variable を構成できます。
-
query_timeoutクエリのタイムアウト期間。単位: 秒。値の範囲:
1から259200。デフォルト値:300。この変数は、現在の接続内のすべてのクエリステートメント、および INSERT ステートメントに影響を与えます。
トラブルシューティング
詳細については、FAQ about data loading を参照してください。