Prometheus と Grafana を使用した監視とアラート
StarRocks は、Prometheus と Grafana を使用して監視とアラートのソリューションを提供します。これにより、クラスターの稼働状況を視覚化し、監視やトラブルシューティングを容易にします。
概要
StarRocks は、Prometheus 互換の情報収集インターフェースを提供します。Prometheus は、BE および FE ノードの HTTP ポートに接続して StarRocks のメトリック情報を取得し、自身の時系列データベースに情報を保存できます。Grafana は、Prometheus をデータソースとして使用してメトリック情報を視覚化できます。StarRocks が提供するダッシュボードテンプレートを使用することで、StarRocks クラスターを簡単に監視し、Grafana でアラートを設定できます。
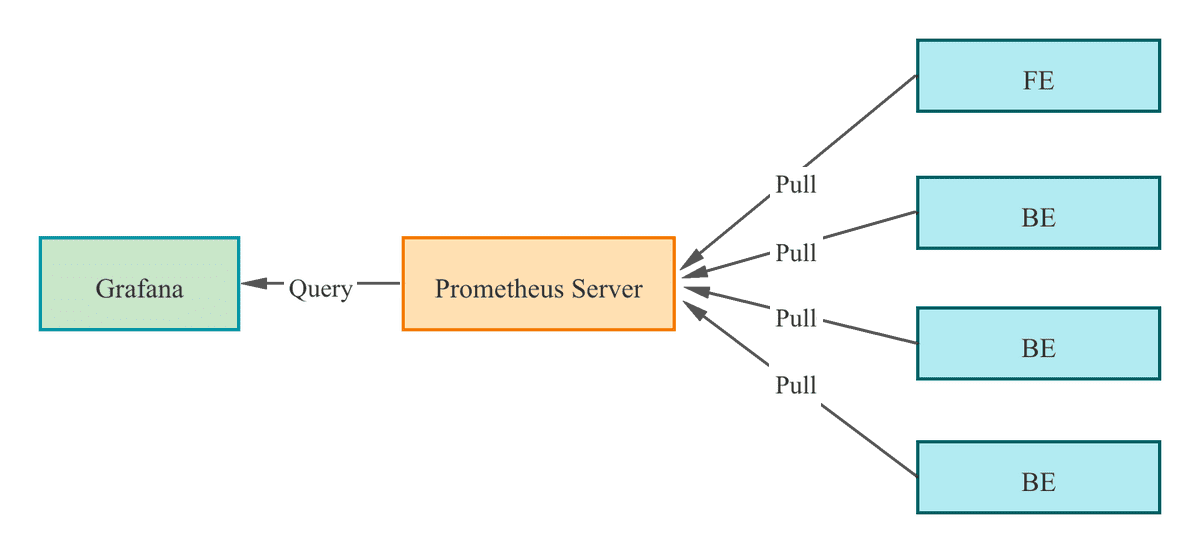
以下の手順に従って、StarRocks クラスターを Prometheus と Grafana に統合します。
- 必要なコンポーネントをインストールする - Prometheus と Grafana。
- StarRocks のコア監視メトリックを理解する。
- アラートチャネルとアラートルールを設定する。
ステップ 1: 監視コンポーネントのインストール
Prometheus と Grafana のデフォルトポートは StarRocks のポートと競合しません。ただし、プロダクション環境では、StarRocks クラスターとは異なるサーバーにデプロイすることをお勧めします。これにより、リソースの競合のリスクが軽減され、サーバーの異常なシャットダウンによるアラートの失敗を回避できます。
さらに、Prometheus と Grafana は自身のサービスの可用性を監視できないことに注意してください。そのため、プロダクション環境では、Supervisor を使用してこれらのサービスにハートビートサービスを設定することをお勧めします。
以下のチュートリアルでは、監視ノード (IP: 192.168.110.23) に監視コンポーネントをデプロイし、以下の StarRocks クラスター (デフォルトポートを使用) を監視します。このチュートリアルに基づいて独自の StarRocks クラスターの監視サービスを設定する場合は、IP アドレスを置き換えるだけです。
| ホスト | IP | OS ユーザー | サービス |
|---|---|---|---|
| node01 | 192.168.110.101 | root | 1 FE + 1 BE |
| node02 | 192.168.110.102 | root | 1 FE + 1 BE |
| node03 | 192.168.110.103 | root | 1 FE + 1 BE |
注意
Prometheus と Grafana は、FE、BE、CN ノードのみを監視でき、Broker ノードは監視できません。
1.1 Prometheus のデプロイ
1.1.1 Prometheus のダウンロード
StarRocks の場合、Prometheus サーバーのインストールパッケージをダウンロードするだけで済みます。監視ノードにパッケージをダウンロードします。
Prometheus をダウンロードするにはここをクリック。
LTS バージョン v2.45.0 を例にとり、パッケージをクリックしてダウンロードします。
または、wget コマンドを使用してダウンロードすることもできます。
# 以下の例では、LTS バージョン v2.45.0 をダウンロードします。
# コマンド内のバージョン番号を置き換えることで、他のバージョンをダウンロードできます。
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
ダウンロードが完了したら、インストールパッケージを監視ノードのディレクトリ /opt にアップロードまたはコピーします。
1.1.2 Prometheus のインストール
-
/opt に移動し、Prometheus インストールパッケージを解凍します。
cd /opt
tar xvf prometheus-2.45.0.linux-amd64.tar.gz -
管理を容易にするため、解凍したディレクトリの名前を prometheus に変更します。
mv prometheus-2.45.0.linux-amd64 prometheus -
Prometheus のデータストレージパスを作成します。
mkdir prometheus/data -
管理を容易にするため、Prometheus のシステムサービス起動ファイルを作成します。
vim /etc/systemd/system/prometheus.serviceファイルに以下の内容を追加します。
[Unit]
Description=Prometheus service
After=network.target
[Service]
User=root
Type=simple
ExecReload=/bin/sh -c "/bin/kill -1 `/usr/bin/pgrep prometheus`"
ExecStop=/bin/sh -c "/bin/kill -9 `/usr/bin/pgrep prometheus`"
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/opt/prometheus/data --storage.tsdb.retention.time=30d --storage.tsdb.retention.size=30GB
[Install]
WantedBy=multi-user.targetその後、エディタを保存して終了します。
注意
Prometheus を異なるパスにデプロイする場合は、上記ファイルの ExecStart コマンド内のパスを同期することを確認してください。また、ファイルは Prometheus データストレージの有効期限条件を「30 日以上」または「30 GB を超える」と設定しています。必要に応じてこれを変更できます。
-
Prometheus の設定ファイル prometheus/prometheus.yml を変更します。このファイルは、内容のフォーマットに厳しい要件があります。変更を行う際は、スペースとインデントに特に注意してください。
vim prometheus/prometheus.ymlファイルに以下の内容を追加します。
global:
scrape_interval: 15s # グローバルなスクレイプ間隔を15秒に設定します。デフォルトは1分です。
evaluation_interval: 15s # グローバルなルール評価間隔を15秒に設定します。デフォルトは1分です。
scrape_configs:
- job_name: 'StarRocks_Cluster01' # 監視されるクラスターはジョブに対応します。ここでStarRocksクラスター名をカスタマイズできます。
metrics_path: '/metrics' # 監視メトリックを取得するためのRestful APIを指定します。
static_configs:
# 以下の設定は、3つのFEノードを含むFEグループを指定します。
# ここで、各FEに対応するIPとHTTPポートを記入する必要があります。
# クラスター展開中にHTTPポートを変更した場合は、それに応じて調整してください。
- targets: ['192.168.110.101:8030','192.168.110.102:8030','192.168.110.103:8030']
labels:
group: fe
# 以下の設定は、3つのBEノードを含むBEグループを指定します。
# ここで、各BEに対応するIPとHTTPポートを記入する必要があります。
# クラスター展開中にHTTPポートを変更した場合は、それに応じて調整してください。
- targets: ['192.168.110.101:8040','192.168.110.102:8040','192.168.110.103:8040']
labels:
group: be設定ファイルを変更した後、
promtoolを使用して変更が有効かどうかを確認できます。./prometheus/promtool check config prometheus/prometheus.yml以下のプロンプトが表示されれば、チェックが通過したことを示します。次に進むことができます。
SUCCESS: prometheus/prometheus.yml is valid prometheus config file syntax -
Prometheus を起動します。
systemctl daemon-reload
systemctl start prometheus.service -
Prometheus のステータスを確認します。
systemctl status prometheus.serviceActive: active (running)が返された場合、Prometheus が正常に起動したことを示します。また、
netstatを使用してデフォルトの Prometheus ポート (9090) のステータスを確認することもできます。netstat -nltp | grep 9090 -
Prometheus を起動時に自動的に開始するように設定します。
systemctl enable prometheus.service
その他のコマンド:
-
Prometheus を停止します。
systemctl stop prometheus.service -
Prometheus を再起動します。
systemctl restart prometheus.service -
実行時に設定をリロードします。
systemctl reload prometheus.service -
起動時の自動開始を無効にします。
systemctl disable prometheus.service
1.1.3 Prometheus へのアクセス
ブラウザを通じて Prometheus Web UI にアクセスできます。デフォルトポートは 9090 です。このチュートリアルの監視ノードの場合、192.168.110.23:9090 にアクセスする必要があります。
Prometheus のホームページで、トップメニューの Status --> Targets に移動します。ここで、prometheus.yml ファイルに設定された各グループジョブのすべての監視ノードを確認できます。通常、すべてのノードのステータスは UP であるべきで、サービス通信が正常であることを示します。
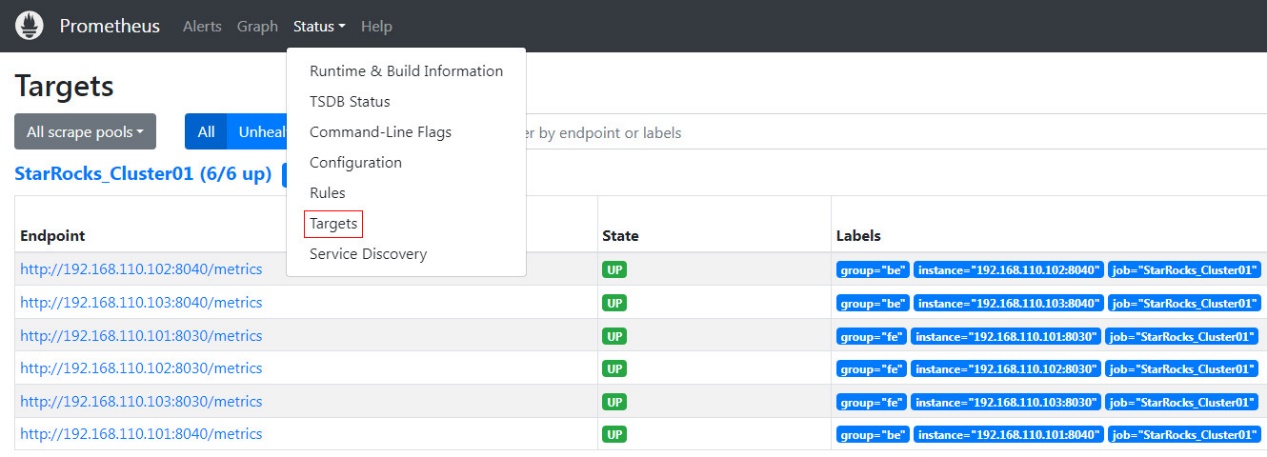
この時点で、Prometheus は設定され、セットアップされています。詳細情報については、Prometheus ドキュメントを参照してください。
1.2 Grafana のデプロイ
1.2.1 Grafana のダウンロード
または、wget コマンドを使用して Grafana RPM インストールパッケージをダウンロードすることもできます。
# 以下の例では、LTS バージョン v10.0.3 をダウンロードします。
# コマンド内のバージョン番号を置き換えることで、他のバージョンをダウンロードできます。
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.3-1.x86_64.rpm
1.2.2 Grafana のインストール
-
yumコマンドを使用して Grafana をインストールします。このコマンドは、Grafana に必要な依存関係を自動的にインストールします。yum -y install grafana-enterprise-10.0.3-1.x86_64.rpm -
Grafana を起動します。
systemctl start grafana-server.service -
Grafana のステータスを確認します。
systemctl status grafana-server.serviceActive: active (running)が返された場合、Grafana が正常に起動したことを示します。また、
netstatを使用してデフォルトの Grafana ポート (3000) のステータスを確認することもできます。netstat -nltp | grep 3000 -
Grafana を起動時に自動的に開始するように設定します。
systemctl enable grafana-server.service
その他のコマンド:
-
Grafana を停止します。
systemctl stop grafana-server.service -
Grafana を再起動します。
systemctl restart grafana-server.service -
起動時の自動開始を無効にします。
systemctl disable grafana-server.service
詳細については、Grafana ドキュメントを参照してください。
1.2.3 Grafana へのアクセス
ブラウザを通じて Grafana Web UI にアクセスできます。デフォルトポートは 3000 です。このチュートリアルの監視ノードの場合、192.168.110.23:3000 にアクセスする必要があります。ログインに必要なデフォルトのユーザー名とパスワードはどちらも admin に設定されています。初回ログイン時に、Grafana はデフォルトのログインパスワードを変更するよう促します。今はスキップしたい場合は、Skip をクリックできます。その後、Grafana Web UI ホームページにリダイレクトされます。
1.2.4 データソースの設定
左上のメニューボタンをクリックし、Administration を展開し、Data sources をクリックします。
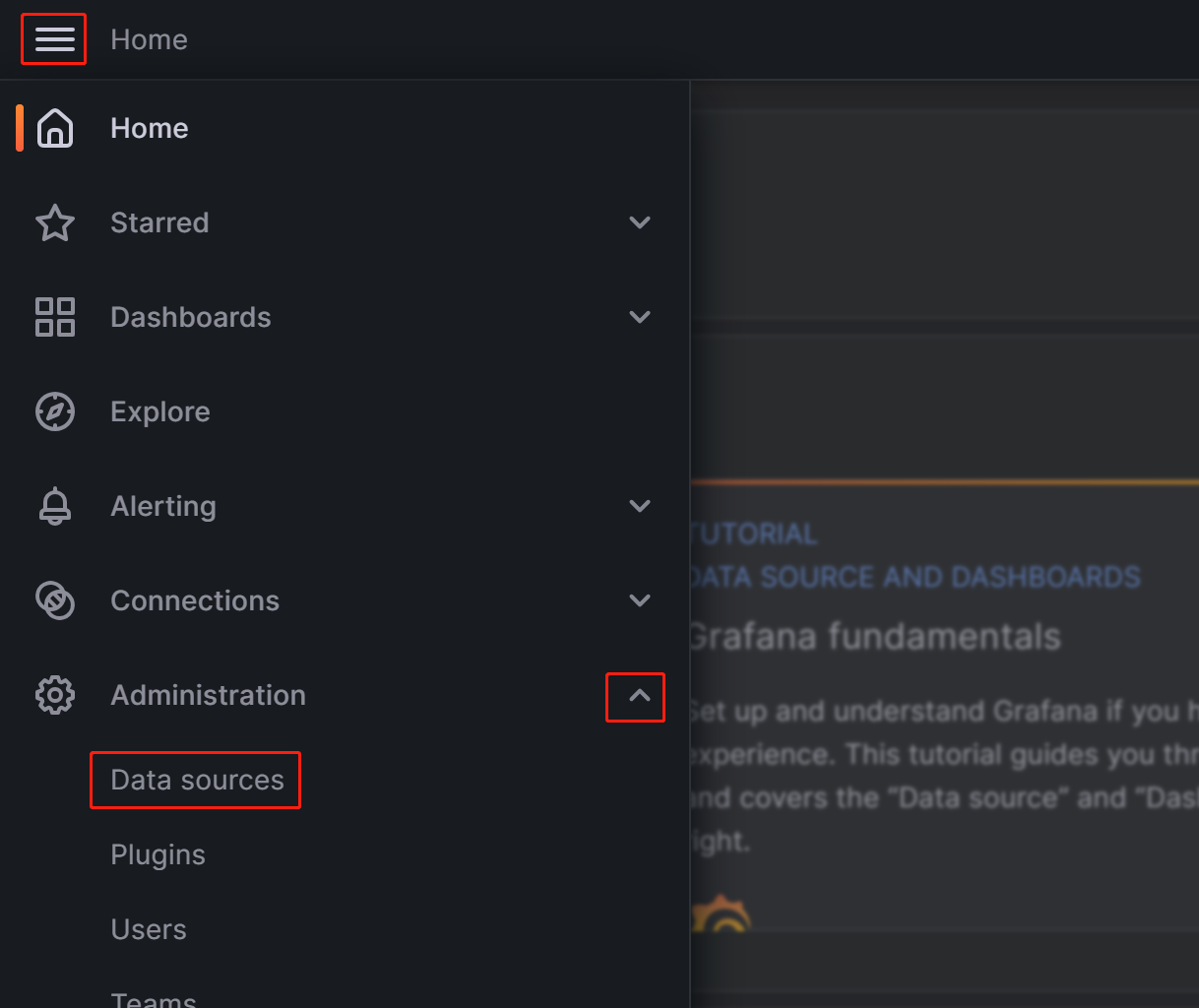
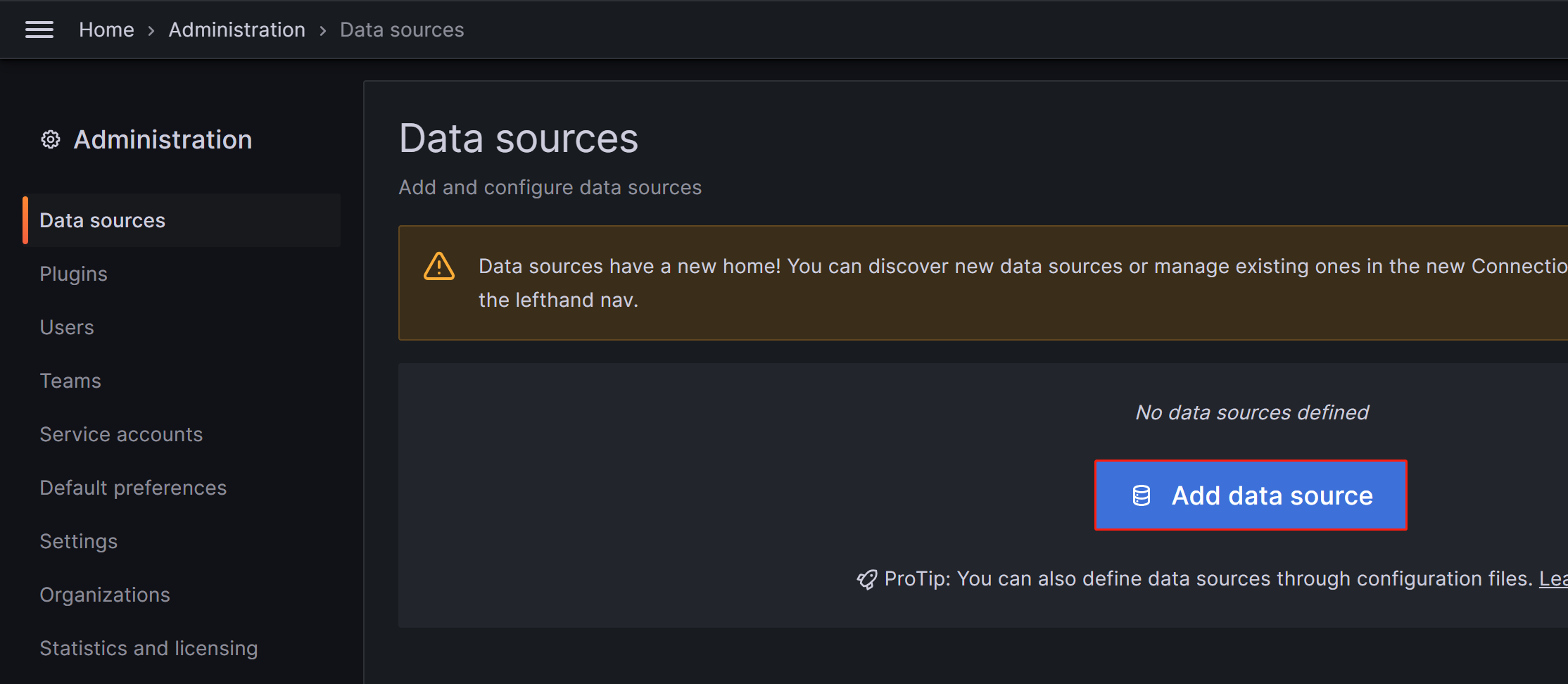
表示されたページで、Add data source をクリックし、Prometheus を選択します。
Grafana を Prometheus サービスと統合するには、次の設定を変更する必要があります。
-
Name: データソースの名前。データソースの名前をカスタマイズできます。

-
Prometheus Server URL: Prometheus サーバーの URL。このチュートリアルでは
http://192.168.110.23:9090です。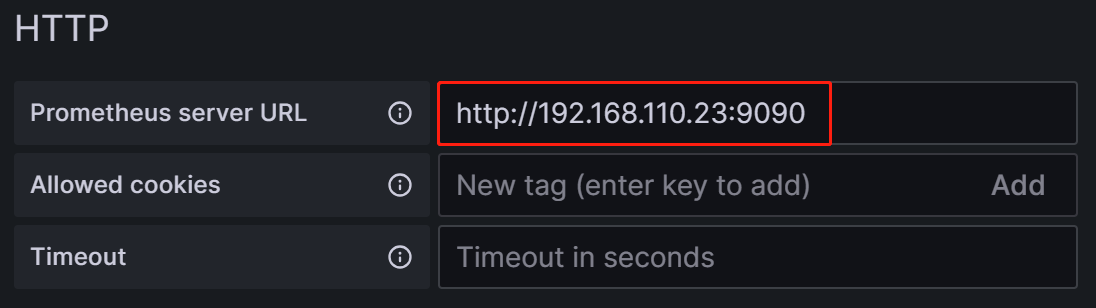
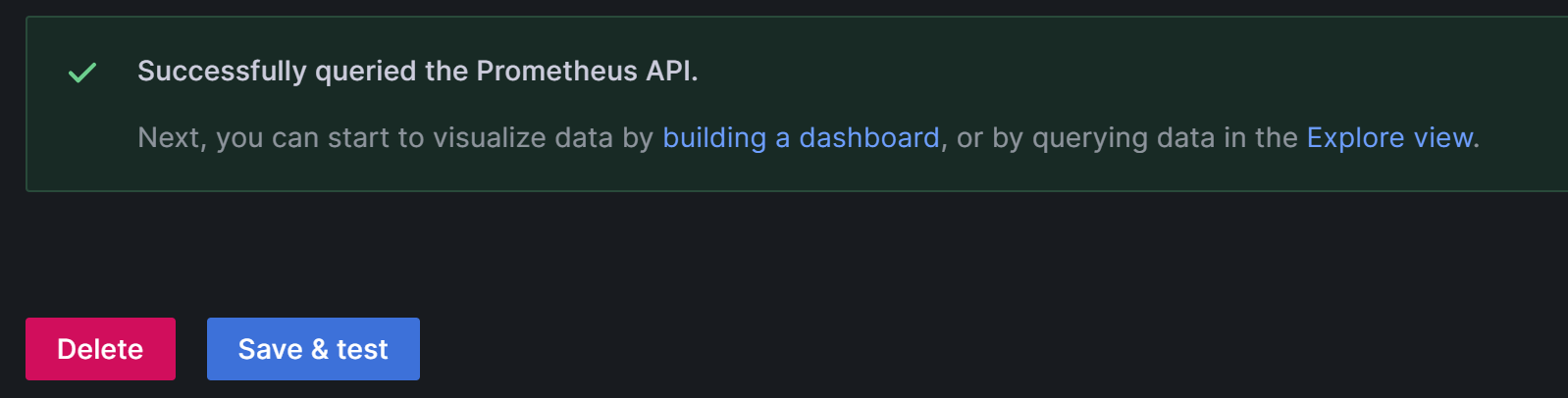
設定が完了したら、Save & Test をクリックして設定を保存し、テストします。Successfully queried the Prometheus API が表示された場合、データソースがアクセス可能であることを意味します。
1.2.5 ダッシュボードの設定
-
StarRocks バージョンに基づいて対応するダッシュボードテンプレートをダウンロードします。
注意
テンプレートファイルは Grafana Web UI を通じてアップロードする必要があります。そのため、テンプレートファイルを Grafana にアクセスするマシンにダウンロードする必要があり、監視ノード自体にはダウンロードしないでください。
-
ダッシュボードテンプレートを設定します。
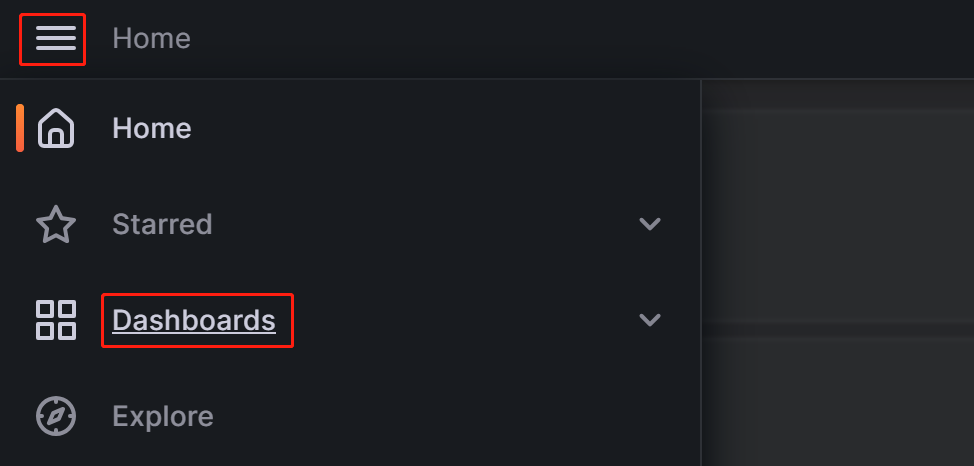
左上のメニューボタンをクリックし、Dashboards をクリックします。
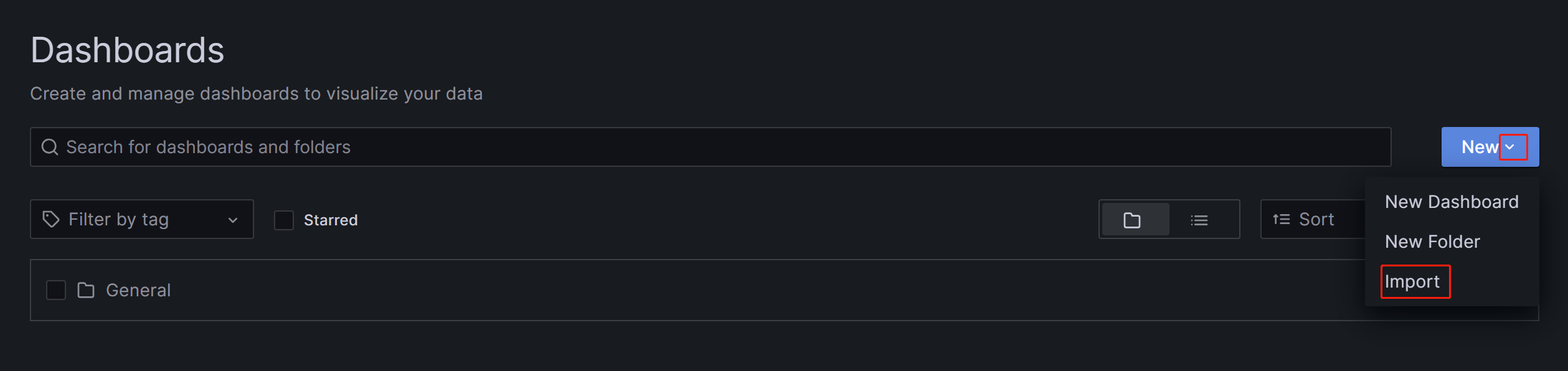
表示されたページで、New ボタンを展開し、Import をクリックします。
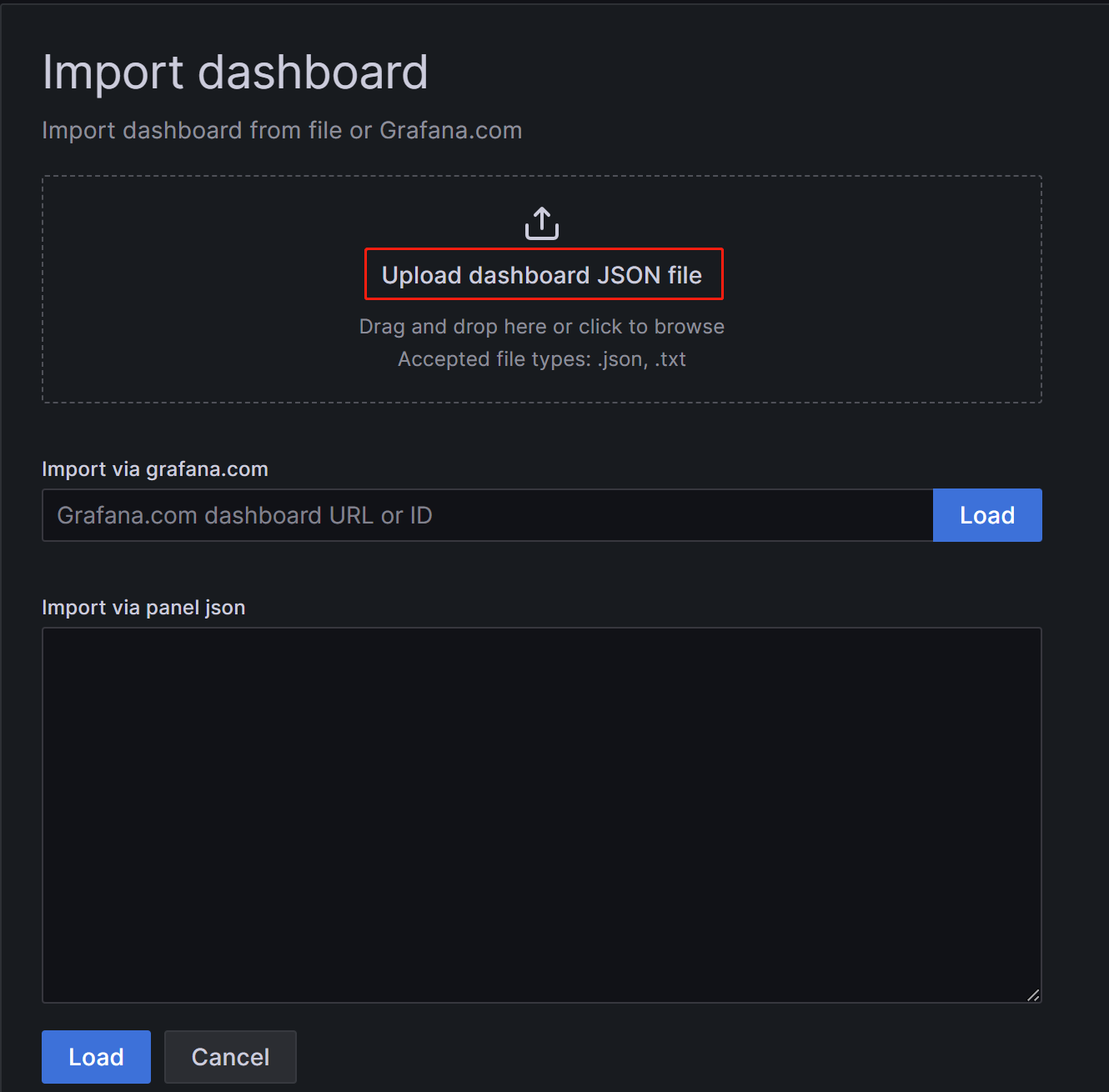
新しいページで、Upload Dashboard JSON file をクリックし、先ほどダウンロードしたテンプレートファイルをアップロードします。
ファイルをアップロードした後、ダッシュボードの名前を変更できます。デフォルトでは
StarRocks Overviewと名付けられています。その後、先ほど作成したデータソース (starrocks_monitor) を選択し、Import をクリックします。
インポートが完了すると、StarRocks ダッシュボードが表示されるはずです。
1.2.6 Grafana を使用した StarRocks の監視
Grafana Web UI にログインし、左上のメニューボタンをクリックして Dashboards を選択します。
表示されたページで、General ディレクトリから StarRocks Overview を選択します。
StarRocks 監視ダッシュボードに入った後、ページの右上で手動でページを更新するか、StarRocks クラスターの状態を監視するための自動更新間隔を設定できます。
ステップ 2: コア監視メトリックを理解する
開発、運用、DBA などのニーズに対応するために、StarRocks は幅広い監視メトリックを提供しています。このセクションでは、ビジネスで一般的に使用される重要なメトリックとそのアラートルールのみを紹介します。他のメトリックの詳細については、Monitoring Metrics を参照してください。
2.1 FE および BE ステータスのメトリック
| メトリック | 説明 | アラートルール | 備考 |
|---|---|---|---|
| Frontends Status | FE ノードのステータス。ライブノードのステータスは 1 で表され、ダウンしたノード (DEAD) は 0 と表示されます。 | すべての FE ノードのステータスはライブであるべきで、DEAD のステータスを持つ FE ノードはアラートをトリガーする必要があります。 | いずれかの FE または BE ノードの障害は重大と見なされ、障害の原因を特定するために迅速なトラブルシューティングが必要です。 |
| Backends Status | BE ノードのステータス。ライブノードのステータスは 1 で表され、ダウンしたノード (DEAD) は 0 と表示されます。 | すべての BE ノードのステータスはライブであるべきで、DEAD のステータスを持つ BE ノードはアラートをトリガーする必要があります。 |
2.2 クエリ失敗のメトリック
| メトリック | 説明 | アラートルール | 備考 |
|---|---|---|---|
| Query Error | 1 分間のクエリ失敗 (タイムアウトを含む) 率。この値は、1 分間に失敗したクエリの数を 60 秒で割ったものです。 | ビジネスの実際の QPS に基づいてこれを設定できます。たとえば、0.05 を初期設定として使用できます。必要に応じて後で調整できます。 | 通常、クエリ失敗率は低く保たれるべきです。このしきい値を 0.05 に設定することは、1 分間に最大 3 件のクエリ失敗を許可することを意味します。この項目からアラートを受け取った場合は、リソース使用率を確認するか、クエリタイムアウトを適切に設定してください。 |
2.3 外部操作失敗のメトリック
| メトリック | 説明 | アラートルール | 備考 |
|---|---|---|---|
| Schema Change | Schema Change 操作の失敗率。 | Schema Change は低頻度の操作です。この項目を設定して、失敗時に即座にアラートを送信することができます。 | 通常、Schema Change 操作は失敗しないはずです。この項目でアラートがトリガーされた場合は、Schema Change 操作のメモリ制限を増やすことを検討できます。デフォルトでは 2GB に設定されています。 |
2.4 内部操作失敗のメトリック
| メトリック | 説明 | アラートルール | 備考 |
|---|---|---|---|
| BE Compaction Score | すべての BE ノードの中で最も高い Compaction Score を示し、現在のコンパクション圧力を示します。 | 通常のオフラインシナリオでは、この値は通常 100 未満です。ただし、多数のロードタスクがある場合、Compaction Score は大幅に増加する可能性があります。ほとんどの場合、この値が 800 を超えると介入が必要です。 | 通常、Compaction Score が 1000 を超えると、StarRocks は「Too many versions」というエラーを返します。このような場合、ロードの同時実行数と頻度を減らすことを検討できます。 |
| Clone | tablet クローン操作の失敗率。 | この項目を設定して、失敗時に即座にアラートを送信することができます。 | この項目でアラートがトリガーされた場合は、BE ノードのステータス、ディスクステータス、ネットワークステータスを確認できます。 |
2.5 サービス可用性のメトリック
| メトリック | 説明 | アラートルール | 備考 |
|---|---|---|---|
| Meta Log Count | FE ノード上の BDB メタデータログエントリの数。 | この項目を設定して、10 万を超えた場合に即座にアラートをトリガーすることをお勧めします。 | デフォルトでは、leader FE ノードはログの数が 5 万を超えるとチェックポイントをトリガーしてログをディスクにフラッシュします。この値が 5 万を大幅に超える場合、通常はチェックポイントの失敗を示します。fe.conf で Xmx ヒープメモリの設定が適切かどうかを確認できます。 |
2.6 システム負荷のメトリック
| メトリック | 説明 | アラートルール | 備考 |
|---|---|---|---|
| BE CPU Idle | BE ノードの CPU アイドル率。 | この項目を設定して、30 秒間連続してアイドル率が 10% 未満の場合にアラートをトリガーすることをお勧めします。 | この項目は、CPU リソースのボトルネックを監視するために使用されます。CPU 使用率は大きく変動する可能性があり、小さなポーリング間隔を設定すると誤警報が発生する可能性があります。したがって、実際のビジネス条件に基づいてこの項目を調整する必要があります。複数のバッチ処理タスクや多数のクエリがある場合は、しきい値を低く設定することを検討できます。 |
| BE Mem | BE ノードのメモリ使用量。 | この項目を各 BE の利用可能なメモリサイズの 90% に設定することをお勧めします。 | この値は Process Mem の値に相当し、BE のデフォルトのメモリ制限はサーバーのメモリサイズの 90% です (be.conf の設定 mem_limit によって制御されます)。同じサーバーに他のサービスをデプロイしている場合は、OOM を避けるためにこの値を調整することを確認してください。この項目のアラートしきい値は、BE の実際のメモリ制限の 90% に設定する必要があります。これにより、BE メモリリソースがボトルネックに達しているかどうかを確認できます。 |
| Disks Avail Capacity | 各 BE ノードのローカルディスクの利用可能なディスクスペース比率 (パーセンテージ)。 | この項目を設定して、値が 20% 未満の場合にアラートをトリガーすることをお勧めします。 | ビジネス要件に基づいて、StarRocks のために十分な利用可能スペースを確保することをお勧めします。 |
| FE JVM Heap Stat | クラスター内の各 FE ノードの JVM ヒープメモリ使用率。 | この項目を設定して、値が 80%以上の場合にアラートをトリガーすることをお勧めします。 | この項目でアラートがトリガーされた場合、fe.conf で Xmx ヒープメモリの設定を増やすことをお勧めします。そうしないと、クエリの効率に影響を与えたり、FE OOM 問題を引き起こす可能性があります。 |
ステップ 3: メールによるアラートの設定
3.1 SMTP サービスの設定
Grafana は、メールや Webhooks など、さまざまなアラートソリューションをサポートしています。このチュートリアルでは、メールを例として使用します。
メールアラートを有効にするには、まず Grafana に SMTP 情報を設定し、Grafana がメールをあなたのメールボックスに送信できるようにする必要があります。一般的に使用されるメールプロバイダーのほとんどは SMTP サービスをサポートしており、メールアカウントの SMTP サービスを有効にし、認証コードを取得する必要があります。
これらの手順を完了した後、Grafana がデプロイされているノードで Grafana の設定ファイルを変更します。
vim /usr/share/grafana/conf/defaults.ini
例:
###################### SMTP / Emailing #####################
[smtp]
enabled = true
host = <smtp_server_address_and_port>
user = johndoe@gmail.com
# If the password contains # or ; you have to wrap it with triple quotes.Ex """#password;"""
password = ABCDEFGHIJKLMNOP # The authorization password obtained after enabling SMTP.
cert_file =
key_file =
skip_verify = true ## Verify SSL for SMTP server
from_address = johndoe@gmail.com ## Address used when sending out emails.
from_name = Grafana
ehlo_identity =
startTLS_policy =
[emails]
welcome_email_on_sign_up = false
templates_pattern = emails/*.html, emails/*.txt
content_types = text/html
次の設定項目を変更する必要があります。
enabled: Grafana がメールアラートを送信できるかどうか。trueに設定します。host: メールの SMTP サーバーアドレスとポートをコロン (:) で区切って指定します。例:smtp.gmail.com:465。user: SMTP ユーザー名。password: SMTP を有効にした後に取得した認証パスワード。skip_verify: SMTP サーバーの SSL 検証をスキップするかどうか。trueに設定します。from_address: アラートメールを送信する際に使用されるメールアドレス。
設定が完了したら、Grafana を再起動します。
systemctl daemon-reload
systemctl restart grafana-server.service
3.2 アラートチャネルの作成
Grafana でアラートがトリガーされたときに連絡先に通知する方法を指定するために、アラートチャネル (Contact Point) を作成する必要があります。
-
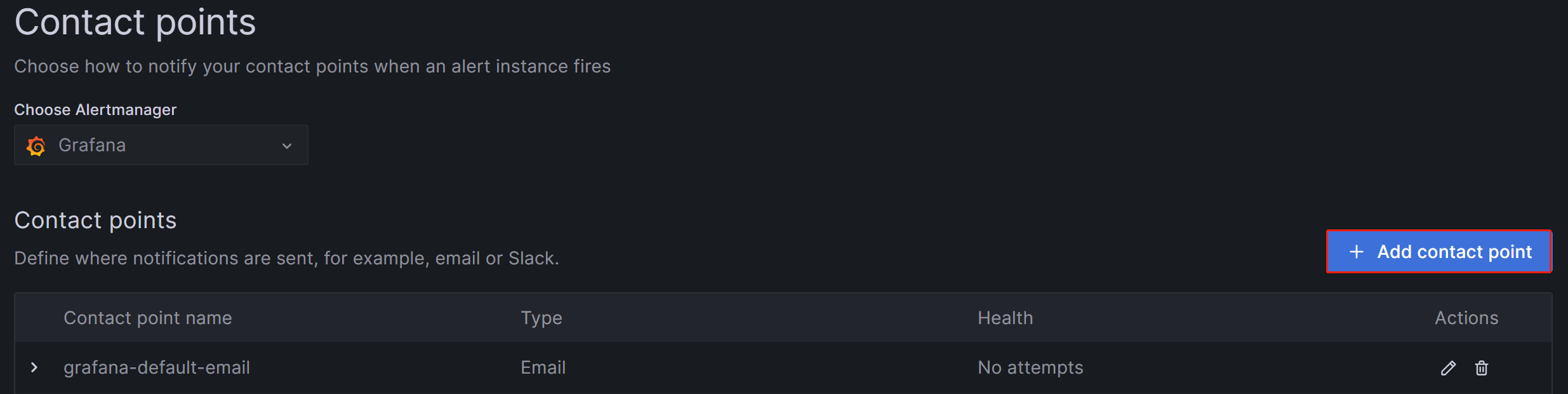
Grafana Web UI にログインし、左上のメニューボタンをクリックして Alerting を展開し、Contact Points を選択します。Contact points ページで、Add contact point をクリックして新しいアラートチャネルを作成します。
-
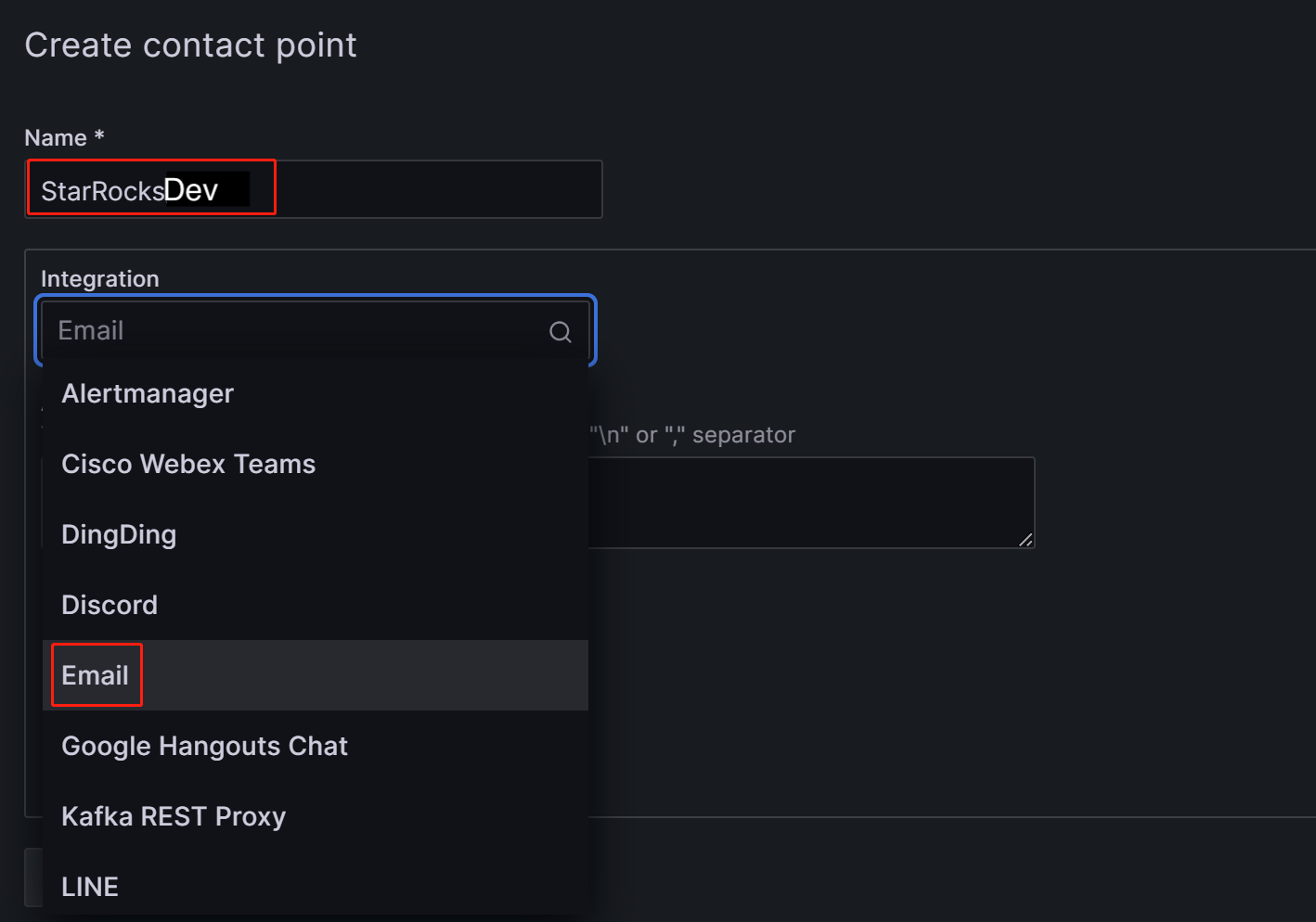
Name フィールドで、コンタクトポイントの名前をカスタマイズします。その後、Integration ドロップダウンリストから Email を選択します。
-
Addresses フィールドに、アラートを受信する連絡先のメールアドレスを入力します。複数のメールアドレスがある場合は、セミコロン (
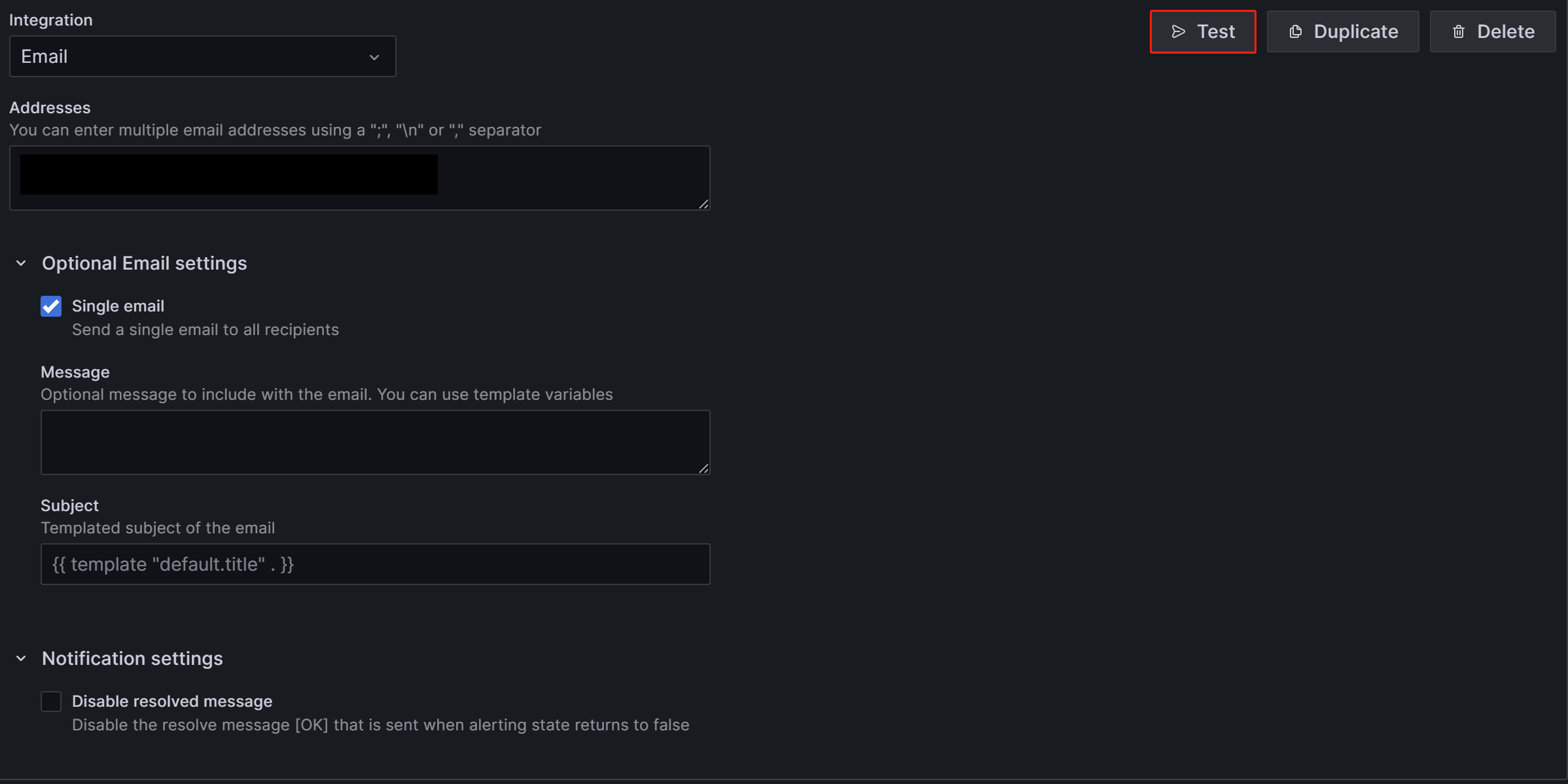
;)、カンマ (,)、または改行でアドレスを区切ります。ページの設定は、次の 2 つの項目を除いてデフォルト値のままにしておくことができます。
- Single email: 有効にすると、複数の連絡先がある場合、アラートは単一のメールで送信されます。この項目を有効にすることをお勧めします。
- Disable resolved message: デフォルトでは、アラートの原因が解決されると、Grafana はサービスの復旧を通知する別の通知を送信します。この復旧通知が不要な場合は、この項目を無効にすることができます。このオプションを無効にすることはお勧めしません。
-
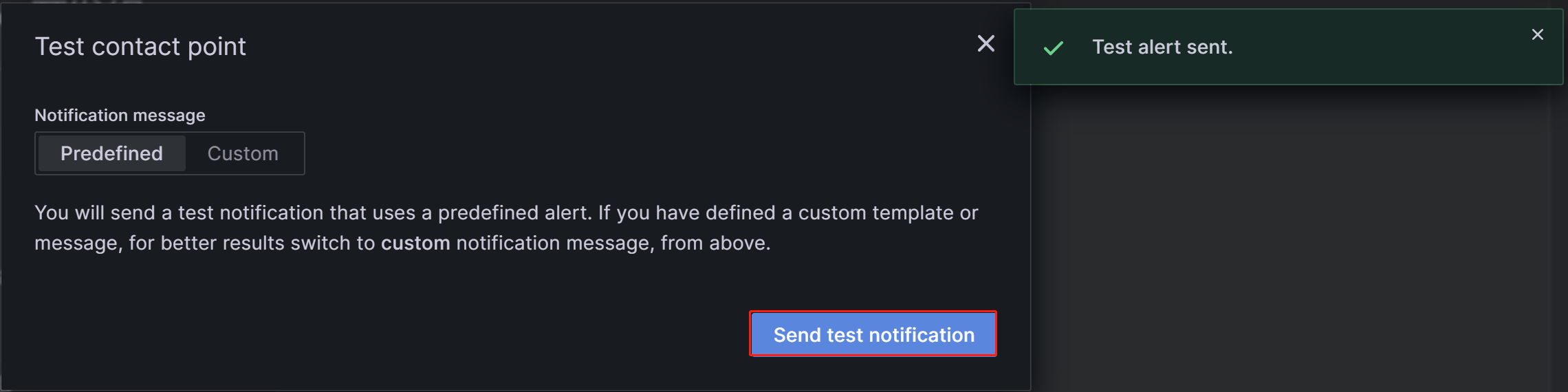
設定が完了したら、ページの右上にある Test ボタンをクリックします。表示されたプロンプトで Sent test notification をクリックします。SMTP サービスとアドレスの設定が正しい場合、ターゲットのメールアカウントは「TestAlert Grafana」という件名のテストメールを受信するはずです。テストアラートメールを正常に受信できることを確認したら、ページ下部の Save contact point ボタンをクリックして設定を完了します。
各コンタクトポイントに対して「Add contact point integration」を通じて複数の通知方法を設定できますが、ここでは詳細を省略します。Contact Points の詳細については、Grafana Documentation を参照してください。
以降のデモンストレーションでは、このステップで異なるメールアドレスを使用して「StarRocksDev」と「StarRocksOp」という 2 つのコンタクトポイントを作成したと仮定します。
3.3 通知ポリシーの設定
Grafana は通知ポリシーを使用してコンタクトポイントとアラートルールを関連付けます。通知ポリシーは、ラベルを使用して異なるアラートを異なる連絡先にルーティングする柔軟な方法を提供し、O&M 中のアラートのグループ化を可能にします。
-
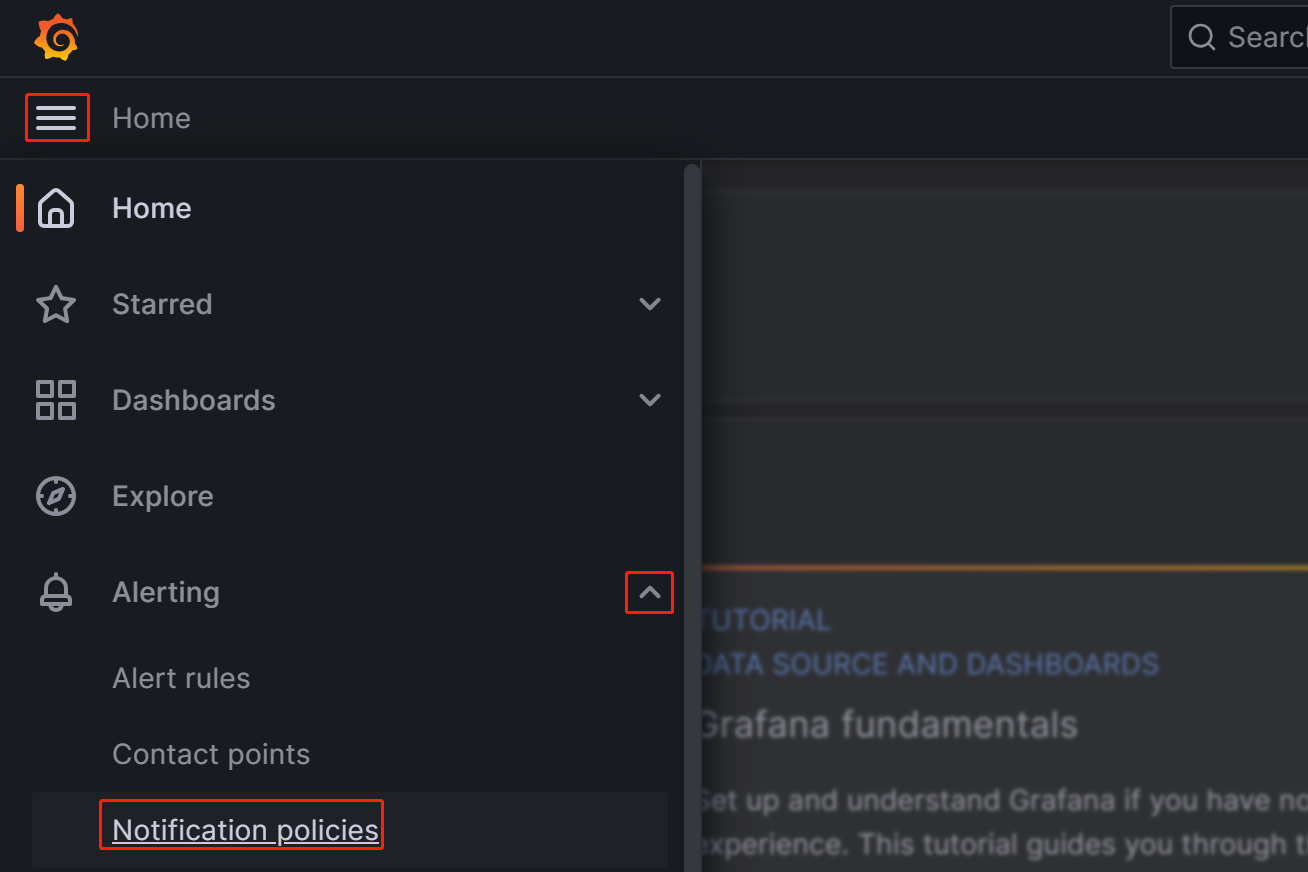
Grafana Web UI にログインし、左上のメニューボタンをクリックして Alerting を展開し、Notification policies を選択します。
-
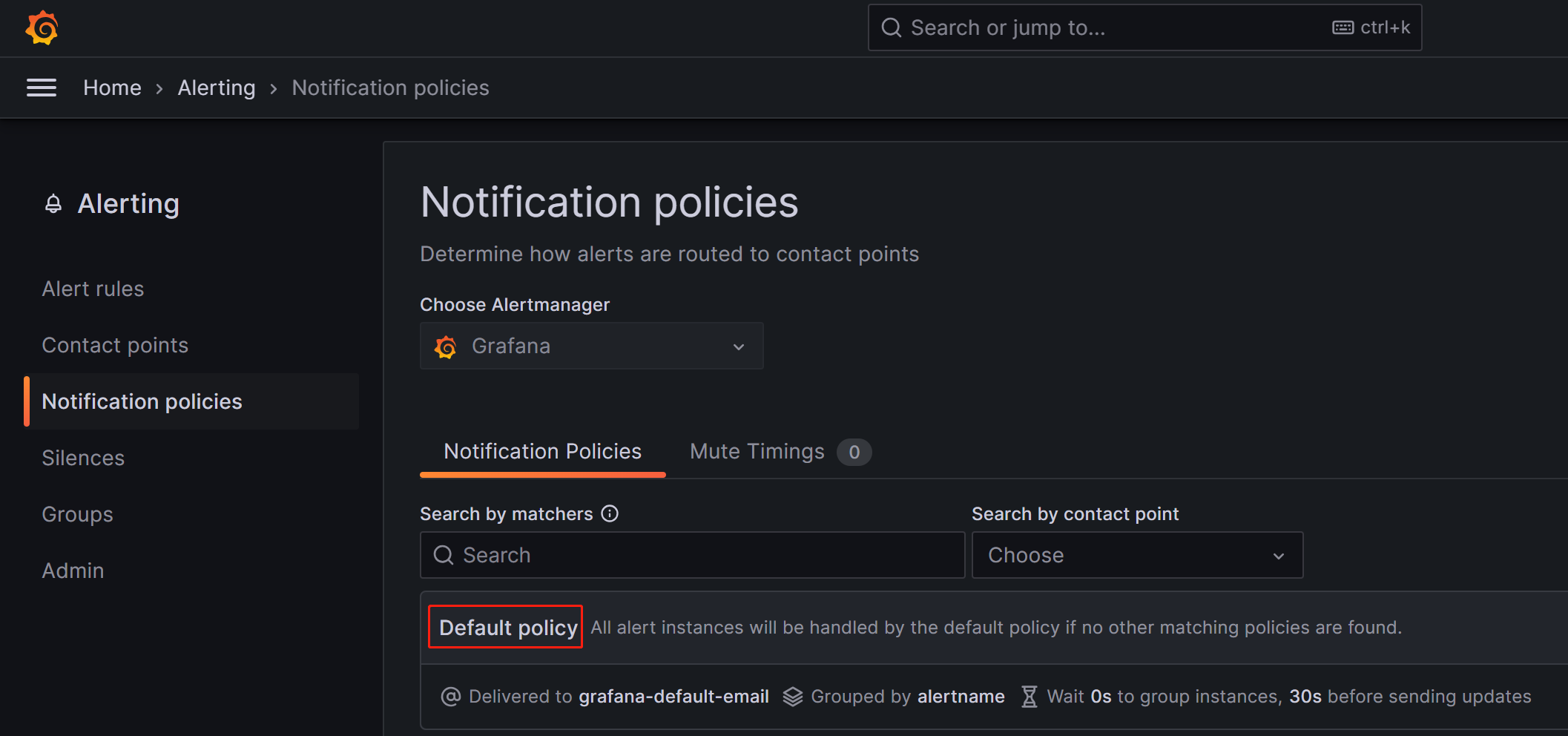
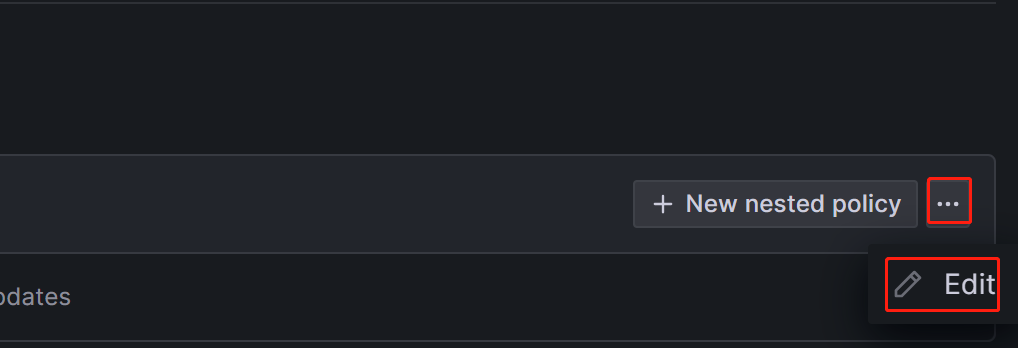
Notification policies ページで、Default policy の右にある詳細 (...) アイコンをクリックし、Edit をクリックして Default policy を変更します。
通知ポリシーはツリー構造を使用し、Default policy は通知のデフォルトのルートポリシーを表します。他のポリシーが設定されていない場合、すべてのアラートルールはデフォルトでこのポリシーに一致します。その後、デフォルトポリシー内で設定されたデフォルトのコンタクトポイントを使用して通知を行います。
-
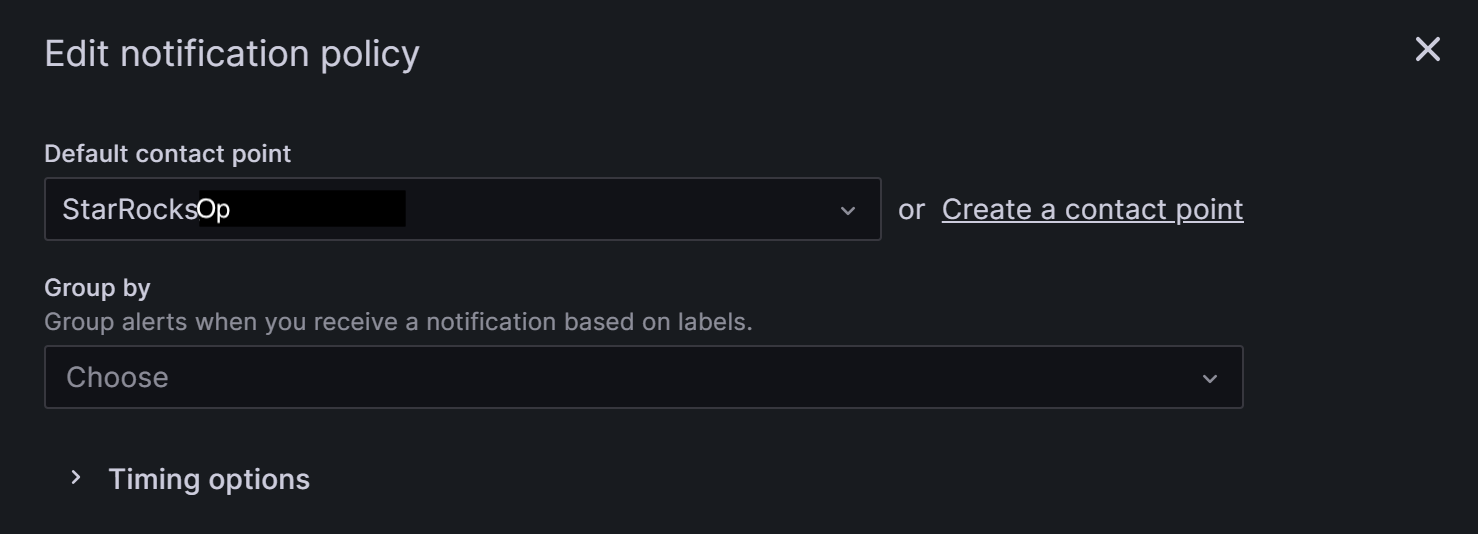
Default contact point フィールドで、以前に作成したコンタクトポイントを選択します。たとえば、「StarRocksOp」。
-
Group by は Grafana Alerting のキーコンセプトで、類似の特性を持つアラートインスタンスを単一のファネルにグループ化します。このチュートリアルではグループ化を行わないため、デフォルト設定を使用できます。
-
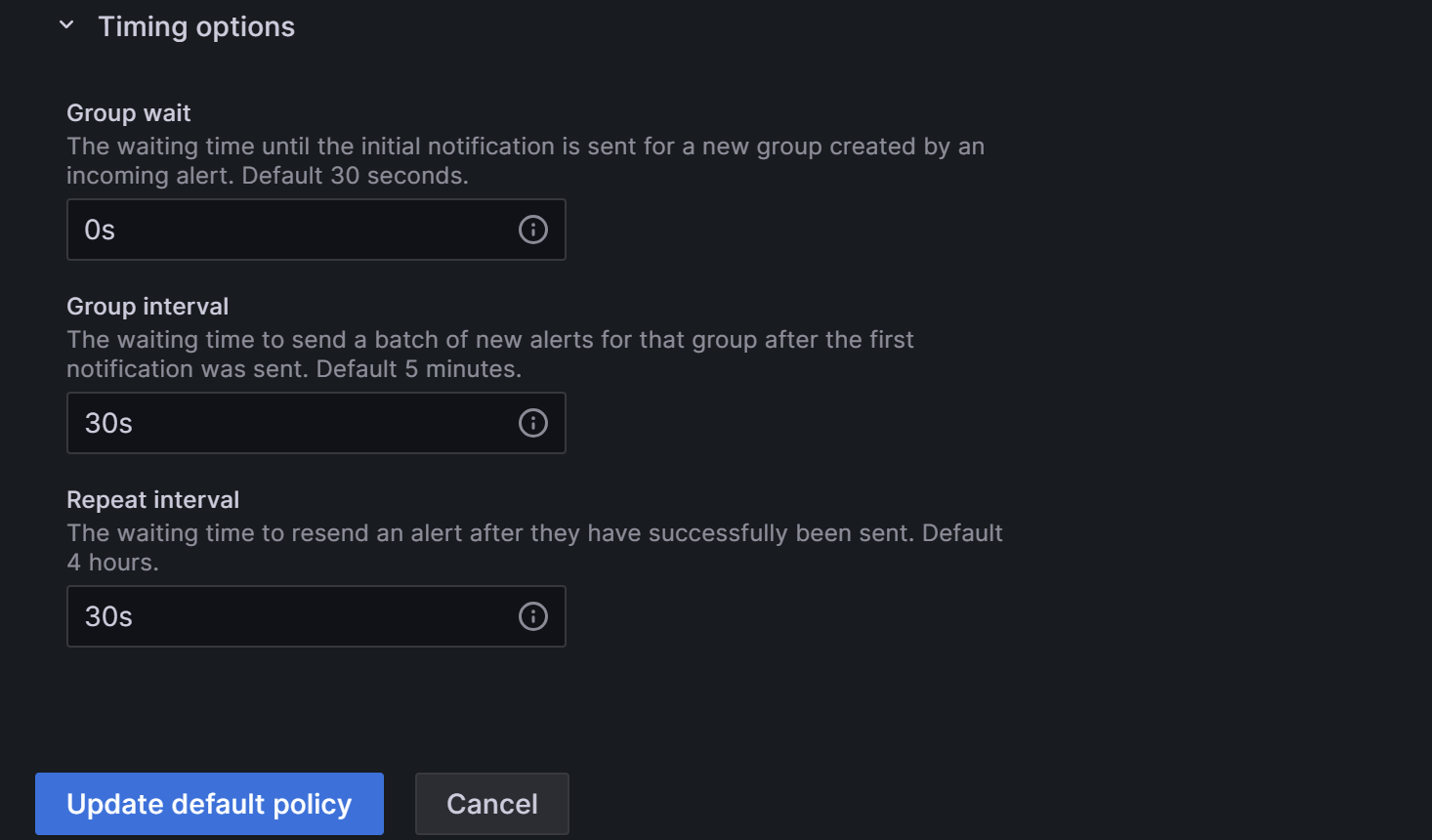
Timing options フィールドを展開し、Group wait、Group interval、Repeat interval を設定します。
- Group wait: 新しいアラートが新しいグループを作成した後、最初の通知を送信するまでの待機時間。デフォルトは 30 秒です。
- Group interval: 既存のグループに対してアラートが送信される間隔。デフォルトは 5 分で、これは前回のアラートが送信されてから 5 分以内にこのグループに通知が送信されないことを意味します。これは、これらのアラートインスタンスのアラートルール間隔が短くても、最後の更新バッチが配信されてから 5 分 (デフォルト) 以内に通知が送信されないことを意味します。
- Repeat interval: アラートが正常に送信された後に再送信するまでの待機時間。既存のグループに対してアラートが送信される間隔。デフォルトは 5 分で、これは前回のアラートが送信されてから 5 分以内にこのグループに通知が送信されないことを意味します。
以下のようにパラメータを設定することで、Grafana はこれらのルールに従ってアラートを送信します: アラート条件が満たされた後、0 秒 (Group wait) で最初のアラートメールを送信します。その後、Grafana は 1 分ごとにアラートを再送信します (Group interval + Repeat interval)。
注意
前述の「アラート条件が満たされる」という表現は、「アラートしきい値に達する」という表現を避けるために使用されています。誤警報を避けるために、しきい値に達した後、一定の時間が経過してからアラートをトリガーするように設定することをお勧めします。
-
-
設定が完了したら、Update default policy をクリックします。
-
ネストされたポリシーを作成する必要がある場合は、Notification policies ページで New nested policy をクリックします。
ネストされたポリシーは、ラベルを使用して一致ルールを定義します。ネストされたポリシーで定義されたラベルは、後でアラートルールを設定する際の条件として使用できます。以下の例では、ラベルを
Group=Development_teamとして設定しています。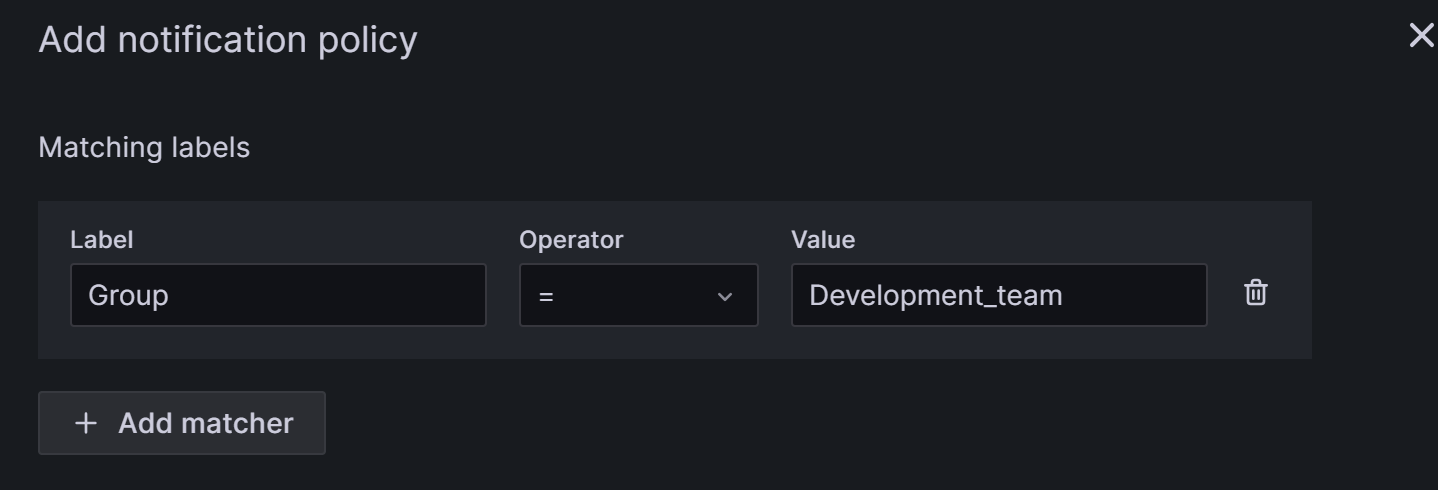
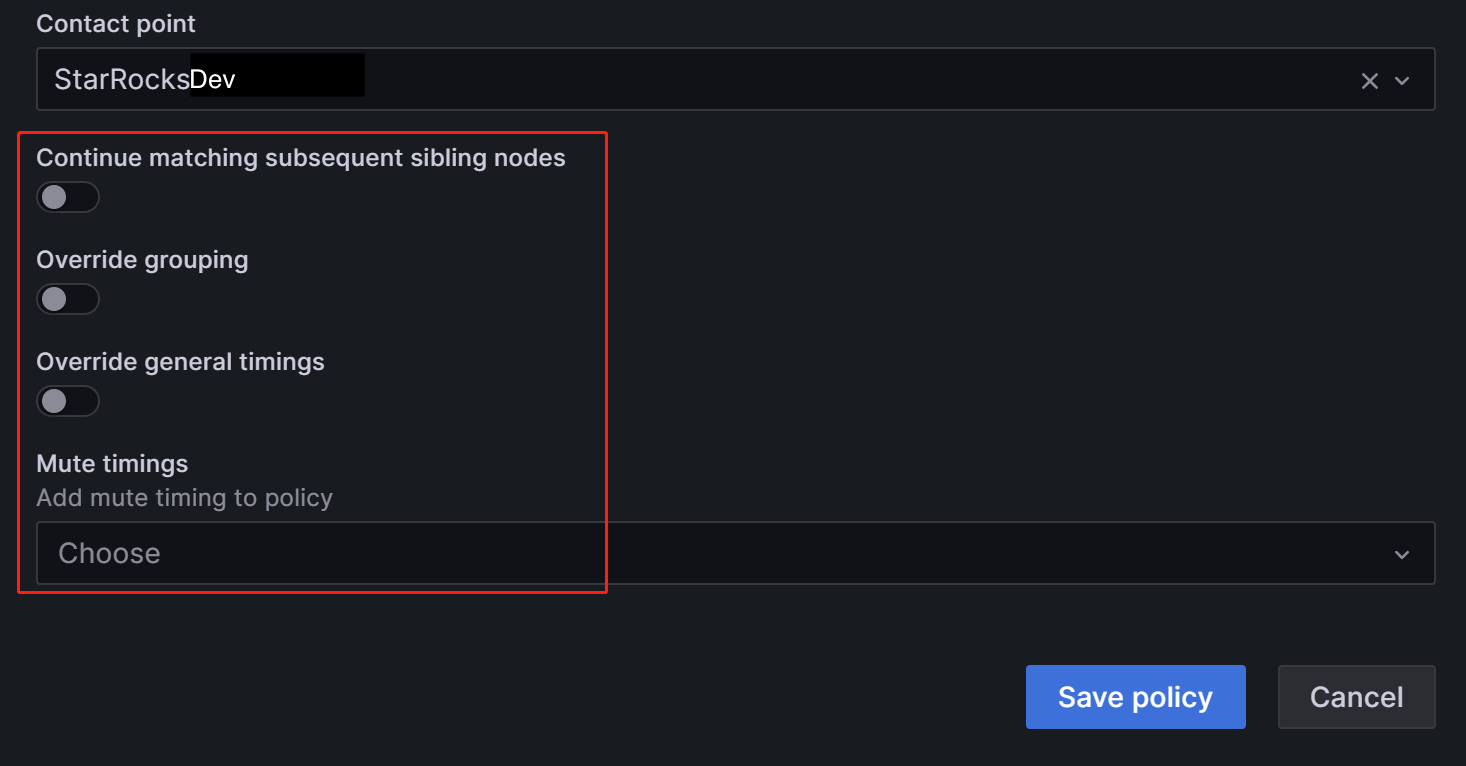
Contact point フィールドで「StarRocksDev」を選択します。これにより、
Group=Development_teamというラベルを持つアラートルールを設定する際に、「StarRocksDev」がアラートを受信するように設定されます。ネストされたポリシーは、親ポリシーからタイミングオプションを継承することができます。設定が完了したら、Save policy をクリックしてポリシーを保存します。
通知ポリシーの詳細や、ビジネスにより複雑なアラートシナリオがある場合は、Grafana Documentation を参照してください。
3.4 アラートルールの定義
通知ポリシーを設定した後、StarRocks のアラートルールも定義する必要があります。
Grafana Web UI にログインし、以前に設定した StarRocks Overview ダッシュボードを検索して移動します。

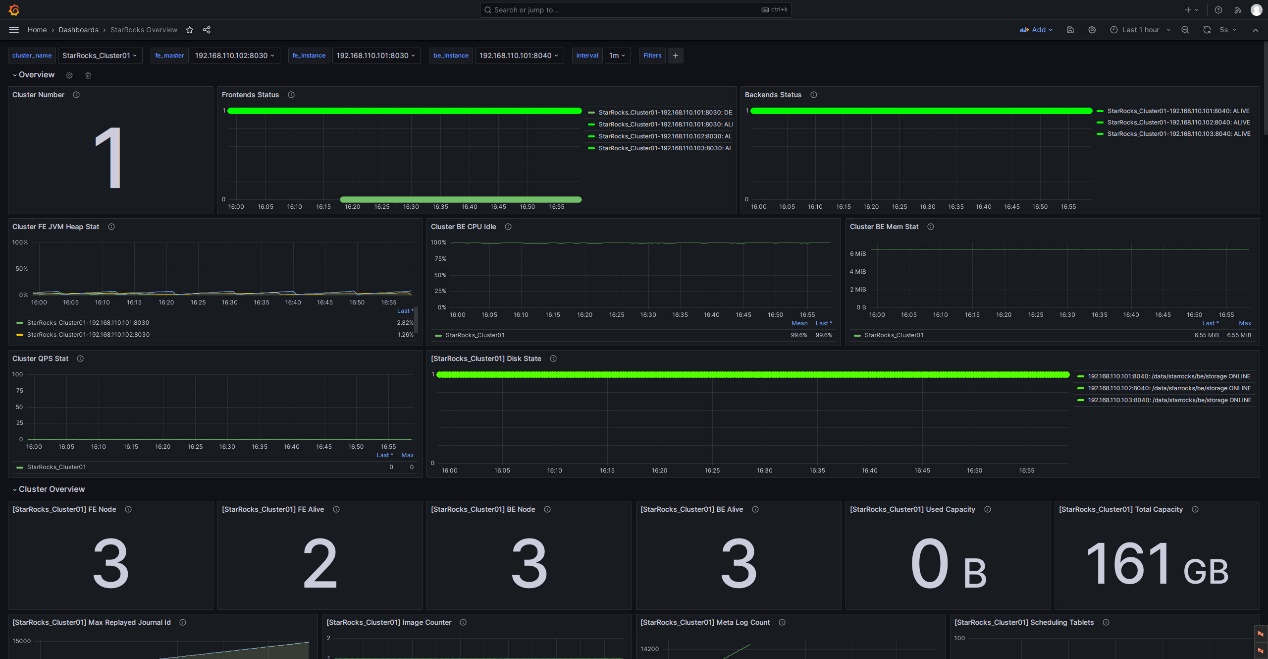
3.4.1 FE および BE ステータスのアラートルール
StarRocks クラスターでは、すべての FE および BE ノードのステータスがライブである必要があります。DEAD のステータスを持つノードはアラートをトリガーする必要があります。
以下の例では、StarRocks Overview の下にある Frontends Status および Backends Status メトリックを使用して FE および BE のステータスを監視します。Prometheus で複数の StarRocks クラスターを設定できるため、Frontends Status および Backends Status メトリックは登録されたすべてのクラスターに対して適用されます。
FE のアラートルールを設定する
Frontends Status のアラートを設定するには、次の手順に従います。
-
Frontends Status 監視項目の右にある詳細 (...) アイコンをクリックし、Edit をクリックします。
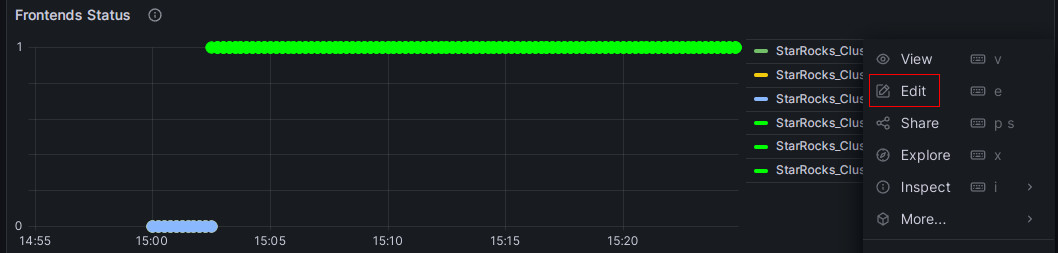
-
新しいページで Alert を選択し、このパネルから Create alert rule をクリックしてルール作成ページに移動します。
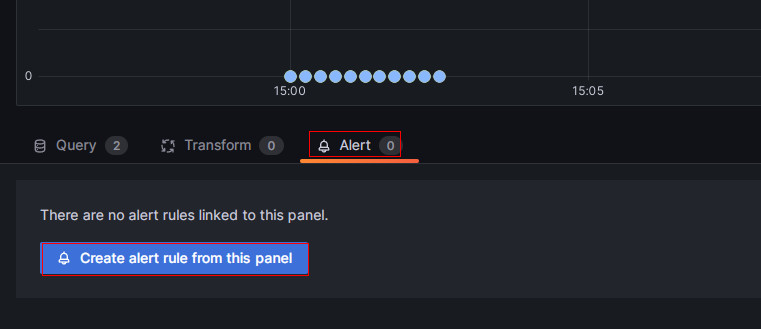
-
Rule name フィールドでルール名を設定します。デフォルト値は監視メトリックのタイトルです。複数のクラスターがある場合は、区別のためにクラスター名をプレフィックスとして追加できます。例: "[PROD]Frontends Status"。
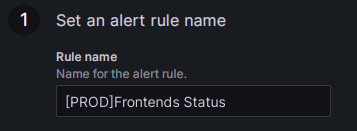
-
アラートルールを次のように設定します。
- Grafana managed alert を選択します。
- セクション B のルールを
(up{group="fe"})に変更します。 - セクション A の右にある削除アイコンをクリックしてセクション A を削除します。
- セクション C の Input フィールドを B に変更します。
- セクション D の条件を
IS BELOW 1に変更します。
これらの設定を完了すると、ページは次のように表示されます。
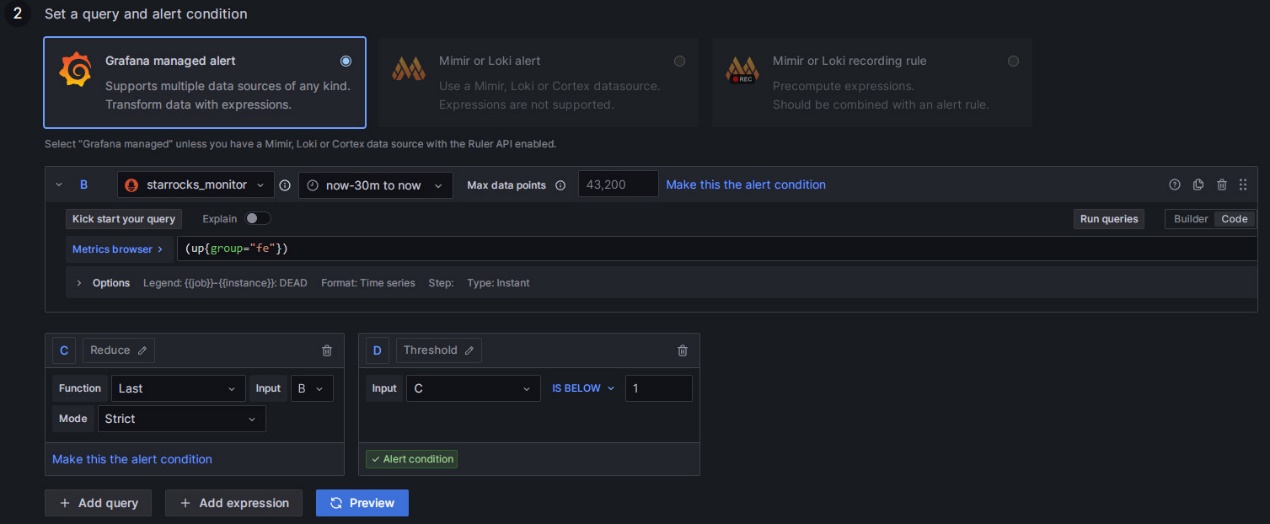
詳細な手順を見るにはクリックしてください
Grafana でアラートルールを設定する際には、通常、次の 3 つのステップがあります。
- PromQL クエリを通じて Prometheus からメトリック値を取得します。PromQL は Prometheus によって開発されたデータクエリ DSL 言語であり、ダッシュボードの JSON テンプレートでも使用されます。各監視項目の
exprプロパティは、それぞれの PromQL に対応しています。ルール設定ページで Run queries をクリックしてクエリ結果を確認できます。 - 結果データに関数とモードを適用して処理します。通常、Last 関数を使用して最新の値を取得し、Strict モードを使用して返された値が数値データでない場合に
NaNとして表示できるようにします。 - 処理されたクエリ結果に対してルールを設定します。FE を例にとると、FE ノードのステータスがライブである場合、出力結果は
1です。FE ノードがダウンしている場合、結果は0です。したがって、ルールをIS BELOW 1に設定し、この条件が発生したときにアラートをトリガーします。
-
アラート評価ルールを設定します。
Grafana ドキュメントによれば、アラートルールを評価する頻度とそのステータスが変化する頻度を設定する必要があります。簡単に言えば、「アラートルールをどのくらいの頻度でチェックするか」と「異常状態が検出された後、アラートをトリガーするまでの持続時間 (一時的なスパイクによる誤警報を避けるため)」を設定することです。各 Evaluation group には、アラートルールをチェックする頻度を決定する独立した評価間隔があります。StarRocks プロダクションクラスター専用の PROD フォルダーを新たに作成し、その中に Evaluation group
01を作成します。次に、このグループを10秒ごとにチェックし、異常が30秒間持続した場合にアラートをトリガーするように設定します。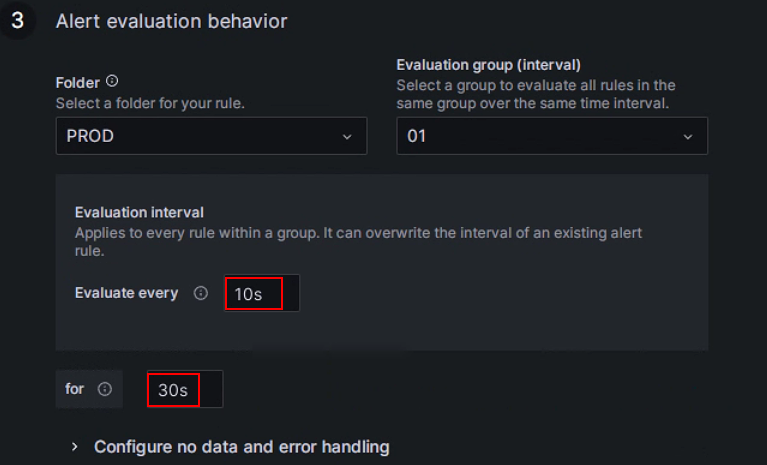
注意
アラートチャネル設定セクションで言及された「Disable resolved message」オプションは、クラスタサービスの復旧に関するメール送信のタイミングを制御しますが、上記の「Evaluate every」パラメータにも影響を受けます。つまり、Grafana が新しいチェックを行い、サービスが復旧したことを検出すると、連絡先に通知するためのメールを送信します。
-
アラート注釈を追加します。
Add details for your alert rule セクションで Add annotation をクリックし、アラートメールの内容を設定します。Dashboard UID と Panel ID フィールドは変更しないでください。
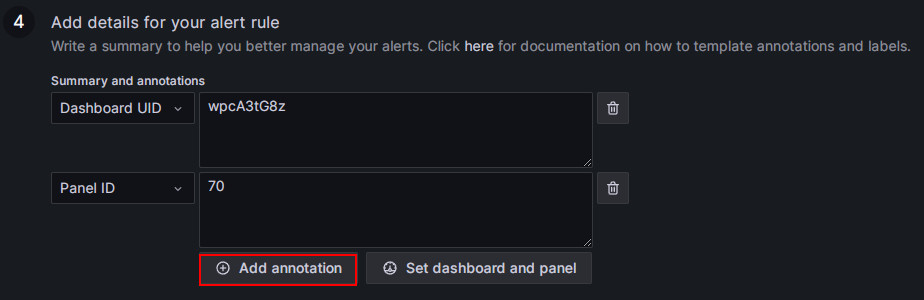
Choose ドロップダウンリストで Description を選択し、アラートメールの説明内容を追加します。例: "FE node in your StarRocks production cluster failed, please check!"
-
通知ポリシーを一致させます。
アラートルールの通知ポリシーを指定します。デフォルトでは、すべてのアラートルールは Default policy に一致します。アラート条件が満たされた場合、Grafana は Default policy の「StarRocksOp」コンタクトポイントを使用して、設定されたメールグループにアラートメッセージを送信します。
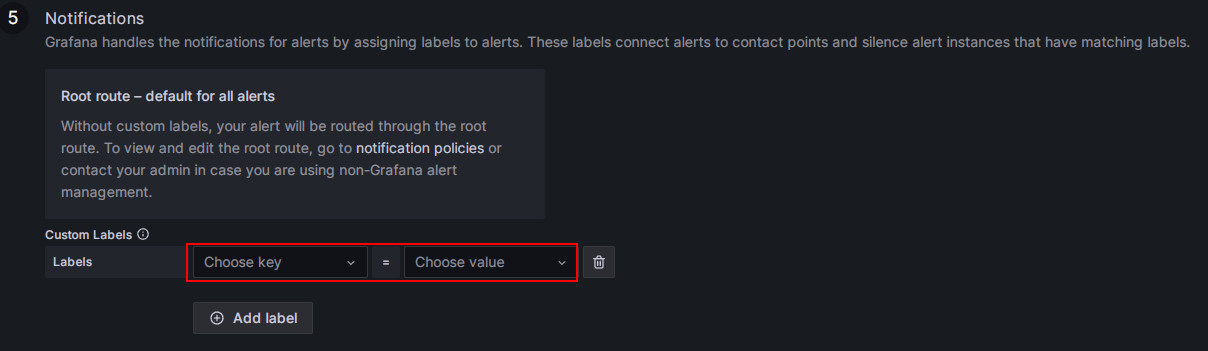
ネストされたポリシーを使用したい場合は、Label フィールドを対応するネストされたポリシーに設定します。例:
Group=Development_team。例:

アラート条件が満たされた場合、Default policy の「StarRocksOp」ではなく「StarRocksDev」にメールが送信されます。
-
すべての設定が完了したら、Save rule and exit をクリックします。

アラートトリガーのテスト
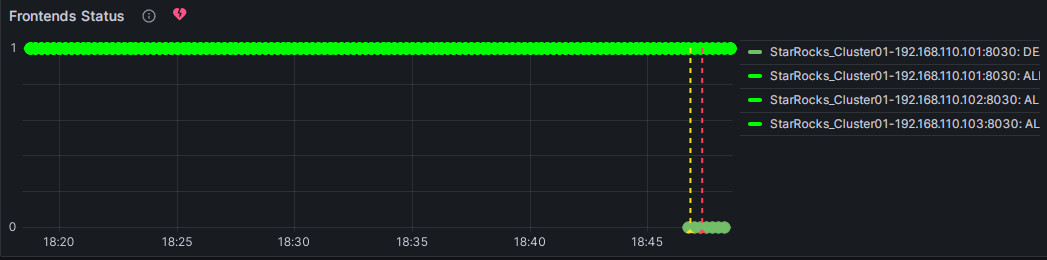
FE ノードを手動で停止してアラートをテストできます。この時、Frontends Status の右にあるハート型のシンボルが緑から黄色、そして赤に変わります。
緑: 最後の定期チェックで、メトリック項目の各インスタンスのステータスが正常であり、アラートがトリガーされなかったことを示します。緑のステータスは、現在のノードが正常な状態にあることを保証するものではありません。ノードサービスの異常後、ステータスの変化に遅延がある場合がありますが、通常、遅延は数分単位ではありません。
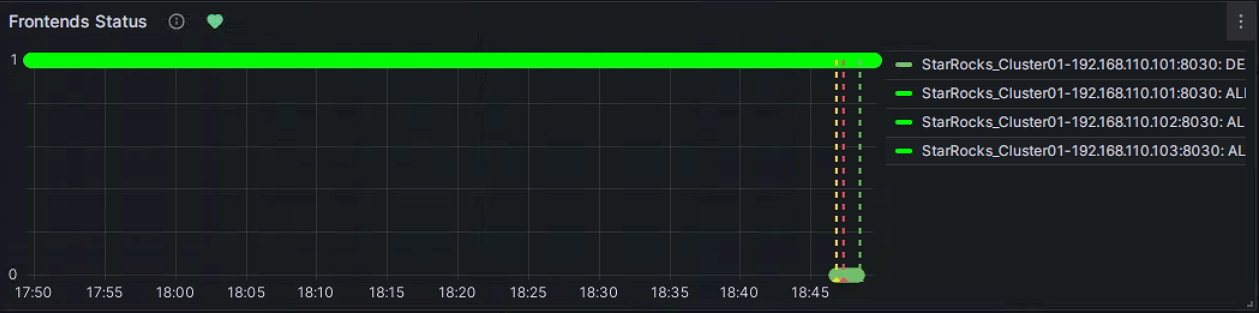
黄色: 最後の定期チェックで、メトリック項目のインスタンスが異常であることが検出されましたが、異常状態の持続時間がまだ上記で設定した「Duration」に達していません。この時点で、Grafana はアラートを送信せず、異常状態の持続時間が設定した「Duration」に達するまで定期チェックを続けます。この期間中にステータスが復旧した場合、シンボルは緑に戻ります。
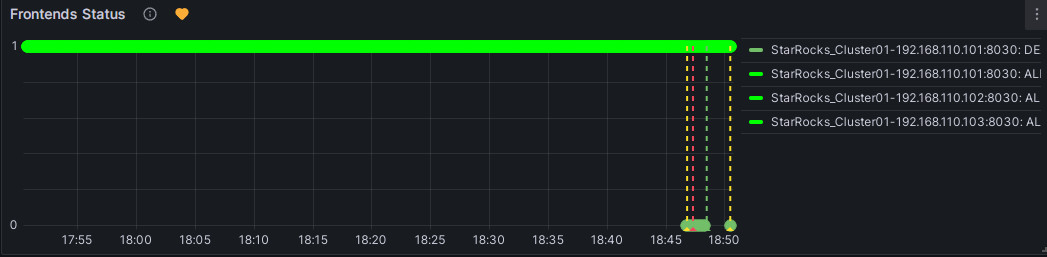
赤: 異常状態の持続時間が設定した「Duration」に達すると、シンボルが赤に変わり、Grafana はメールアラートを送信します。異常状態が解決されるまでシンボルは赤のままで、その後緑に戻ります。
アラートを手動で一時停止する
異常の解決に長時間が必要な場合や、異常以外の理由でアラートが継続的にトリガーされる場合、Grafana がアラートメールを送信し続けるのを防ぐために、アラートルールの評価を一時的に停止することができます。
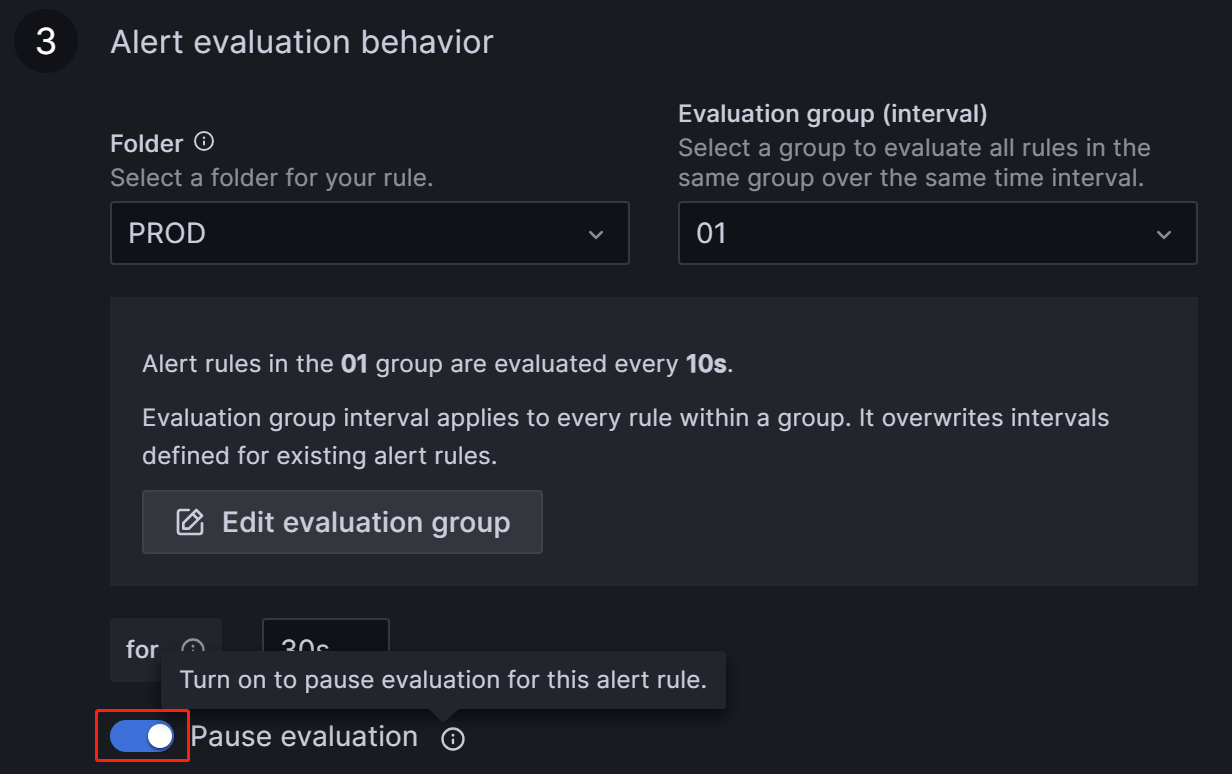
ダッシュボードのメトリック項目に対応する Alert タブに移動し、編集アイコンをクリックします。
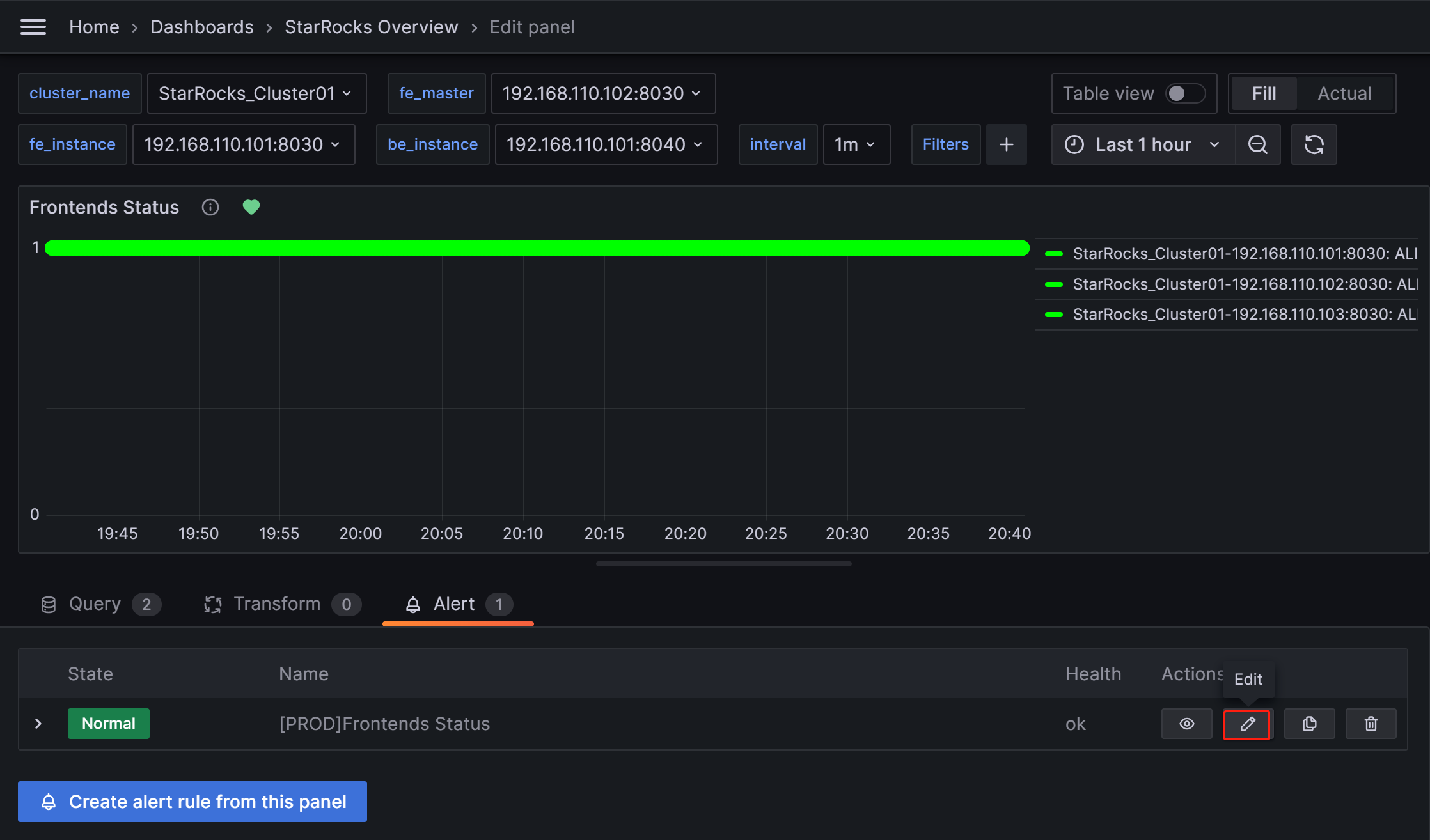
Alert Evaluation Behavior セクションで、Pause Evaluation スイッチを ON に切り替えます。
注意
評価を一時停止した後、サービスが復旧したことを通知するメールを受け取ります。
BE のアラートルールを設定する
上記のプロセスに従って BE のアラートルールを設定できます。
Backends Status メトリック項目の設定を編集します。
- Set an alert rule name セクションで、名前を "[PROD]Backends Status" に設定します。
- Set a query and alert condition セクションで、PromSQL を
(up{group="be"})に設定し、他の項目は FE アラートルールと同じ設定を使用します。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "BE node in your StarRocks production cluster failed, please check! BE の障害のスタック情報は BE ログファイル be.out に出力されます。ログに基づいて原因を特定できます"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
3.4.2 クエリアラートルール
クエリ失敗のメトリック項目は Query Statistic の下にある Query Error です。
「Query Error」メトリック項目のアラートルールを次のように設定します。
- Set an alert rule name セクションで、名前を "[PROD] Query Error" に設定します。
- Set a query and alert condition セクションで、セクション B を削除します。セクション A の Input を C に設定します。セクション C では、PromQL のデフォルト値を使用します。これは
rate(starrocks_fe_query_err{job="StarRocks_Cluster01"}[1m])で、1 分間に失敗したクエリの数を 60 秒で割ったものです。これは、失敗したクエリとタイムアウトしたクエリの両方を含みます。その後、セクション D でルールをA IS ABOVE 0.05に設定します。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "High query failure rate, please check the resource usage or configure query timeout reasonably. If queries are failing due to timeouts, you can adjust the query timeout by setting the system variable
query_timeout"。 - Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
3.4.3 ユーザー操作失敗のアラートルール
この項目は、Schema Change 操作の失敗率を監視し、BE tasks の下にある Schema Change メトリック項目に対応します。0 を超える場合にアラートを設定する必要があります。
- Set an alert rule name セクションで、名前を "[PROD] Schema Change" に設定します。
- Set a query and alert condition セクションで、セクション A を削除します。セクション C の Input を B に設定します。セクション B では、PromQL のデフォルト値を使用します。これは
irate(starrocks_be_engine_requests_total{job="StarRocks_Cluster01", type="create_rollup", status="failed"}[1m])で、1 分間に失敗した Schema Change タスクの数を 60 秒で割ったものです。その後、セクション D でルールをC IS ABOVE 0に設定します。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Failed Schema Change tasks detected, please check promptly. You can increase the memory limit available for Schema Change by adjusting the BE configuration parameter
memory_limitation_per_thread_for_schema_change, which is set to 2GB by default"。 - Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
3.4.4 StarRocks 操作失敗のアラートルール
BE Compaction Score
この項目は Cluster Overview の下にある BE Compaction Score に対応し、クラスターのコンパクション圧力を監視するために使用されます。
- Set an alert rule name セクションで、名前を "[PROD] BE Compaction Score" に設定します。
- Set a query and alert condition セクションで、セクション C のルールを
B IS ABOVE 0に設定します。他の項目にはデフォルト値を使用できます。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "High compaction pressure. Please check whether there are high-frequency or high-concurrency loading tasks and reduce the loading frequency. If the cluster has sufficient CPU, memory, and I/O resources, consider adjusting the cluster compaction strategy"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
Clone
この項目は BE tasks の Clone に対応し、通常は失敗しない StarRocks 内のレプリカバランシングまたはレプリカ修復操作を監視するために使用されます。
- Set an alert rule name セクションで、名前を "[PROD] Clone" に設定します。
- Set a query and alert condition セクションで、セクション A を削除します。セクション C の Input を B に設定します。セクション B では、PromQL のデフォルト値を使用します。これは
irate(starrocks_be_engine_requests_total{job="StarRocks_Cluster01", type="clone", status="failed"}[1m])で、1 分間に失敗した Clone タスクの数を 60 秒で割ったものです。その後、セクション D でルールをC IS ABOVE 0に設定します。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Detected a failure in the clone task. Please check the cluster BE status, disk status, and network status"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
3.4.5 サービス可用性のアラートルール
この項目は BDB のメタデータログ数を監視し、Cluster Overview の Meta Log Count 監視項目に対応します。
- Set an alert rule name セクションで、名前を "[PROD] Meta Log Count" に設定します。
- Set a query and alert condition セクションで、セクション C のルールを
B IS ABOVE 100000に設定します。他の項目にはデフォルト値を使用できます。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Detected that the metadata count in FE BDB is significantly higher than the expected value, which can indicate a failed Checkpoint operation. Please check whether the Xmx heap memory configuration in the FE configuration file fe.conf is reasonable"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
3.4.6 システムオーバーロードのアラートルール
BE CPU Idle
この項目は BE ノードの CPU アイドル率を監視します。
- Set an alert rule name セクションで、名前を "[PROD] BE CPU Idle" に設定します。
- Set a query and alert condition セクションで、セクション C のルールを
B IS BELOW 10に設定します。他の項目にはデフォルト値を使用できます。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Detected that BE CPU load is consistently high. It will impact other tasks in the cluster. Please check whether the cluster is abnormal or if there is a CPU resource bottleneck"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
BE Memory
この項目は BE の BE Mem に対応し、BE ノードのメモリ使用量を監視します。
- Set an alert rule name セクションで、名前を "[PROD] BE Mem" に設定します。
- Set a query and alert condition セクションで、PromSQL を
starrocks_be_process_mem_bytes{job="StarRocks_Cluster01"}/(<be_mem_limit>*1024*1024*1024)に設定します。ここで<be_mem_limit>は現在の BE ノードの利用可能なメモリ制限に置き換える必要があります。つまり、サーバーのメモリサイズに BE 設定項目mem_limitの値を掛けたものです。例:starrocks_be_process_mem_bytes{job="StarRocks_Cluster01"}/(49*1024*1024*1024)。その後、セクション C でルールをB IS ABOVE 0.9に設定します。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Detected that BE memory usage is consistently high. To prevent query failure, please consider expanding memory size or adding BE nodes"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
Disks Avail Capacity
この項目は BE の Disk Usage に対応し、BE ストレージパスがあるディレクトリの残りスペース比率を監視します。
- Set an alert rule name セクションで、名前を "[PROD] Disks Avail Capacity" に設定します。
- Set a query and alert condition セクションで、セクション C のルールを
B IS BELOW 0.2に設定します。他の項目にはデフォルト値を使用できます。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Detected that BE disk available space is below 20%, please release disk space or expand the disk"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
FE JVM Heap Stat
この項目は Overview の Cluster FE JVM Heap Stat に対応し、FE の JVM メモリ使用率と FE ヒープメモリ制限の割合を監視します。
- Set an alert rule name セクションで、名前を "[PROD] FE JVM Heap Stat" に設定します。
- Set a query and alert condition セクションで、セクション C のルールを
B IS ABOVE 80に設定します。他の項目にはデフォルト値を使用できます。 - Alert evaluation behavior セクションで、以前に作成した PROD ディレクトリと Evaluation group 01 を選択し、持続時間を 30 秒に設定します。
- Add details for your alert rule セクションで Add annotation をクリックし、Description を選択してアラート内容を入力します。例: "Detected that FE heap memory usage is high, please adjust the heap memory limit in the FE configuration file fe.conf"。
- Notifications セクションで、Labels を FE アラートルールと同じように設定します。Labels が設定されていない場合、Grafana は Default policy を使用し、「StarRocksOp」アラートチャネルにアラートメールを送信します。
Q&A
Q: ダッシュボードが異常を検出できないのはなぜですか?
A: Grafana ダッシュボードは、ホストされているサーバーのシステム時間に依存して監視項目の値を取得します。クラスターの異常後に Grafana ダッシュボードページが変化しない場合、サーバーのシステムクロックが同期されているかどうかを確認し、その後クラスターの時間校正を行うことができます。
Q: アラートのグレードを実装するにはどうすればよいですか?
A: Query Error 項目を例にとると、異なるアラートしきい値で 2 つのアラートルールを作成できます。たとえば:
- リスクレベル: 失敗率を 0.05 より大きく設定し、リスクを示します。アラートを開発チームに送信します。
- 重大度レベル: 失敗率を 0.20 より大きく設定し、重大度を示します。この時点で、アラート通知は開発チームと運用チームの両方に同時に送信されます。