データ分散
テーブルを作成する際には、パーティション数とテーブル内のタブレット数を設定してデータ分散の手法を指定する必要があります。適切なデータ分散の手法は、StarRocks クラスターのノード全体にデータを均等に分散させ、テーブルスキャンを減らし、クラスターの並列性を最大限に活用することで、クエリパフォーマンスを向上させます。
基本概念
データ分散の設計と管理の詳細に入る前に、以下の概念を理解しておきましょう。
-
パーティション化
パーティション化は、指定したパーティション列に基づいてテーブルを複数のセグメント(パーティション)に分割します。パーティションには、レプリカの数、ホットデータやコールドデータの保存戦略、記憶媒体などのストレージ戦略を設定できます。StarRocks では、クラスター内で複数の記憶媒体を使用することができます。例えば、最新のデータを SSD に保存してクエリパフォーマンスを向上させ、履歴データを SATA ハードドライブに保存してストレージコストを削減することができます。
-
バケッティング
バケッティングは、パーティションをタブレットと呼ばれるより管理しやすい部分に分割します。タブレットは、使用および割り当て可能な最小のストレージ単位です。StarRocks はハッシュアルゴリズムを使用してデータをバケット化します。バケッティング列のハッシュ値が同じデータは同じタブレットに分配されます。StarRocks はデータ損失を防ぐために、各タブレットに対して複数のレプリカ(デフォルトで3つ)を作成します。これらのレプリカは、別のローカルストレージエンジンによって管理されます。テーブルを作成する際には、バケッティング列を指定する必要があります。
パーティション化の手法
現代の分散データベースシステムは、一般的に4つの基本的なパーティション化の手法を使用します: ラウンドロビン、レンジ、リスト、ハッシュ。
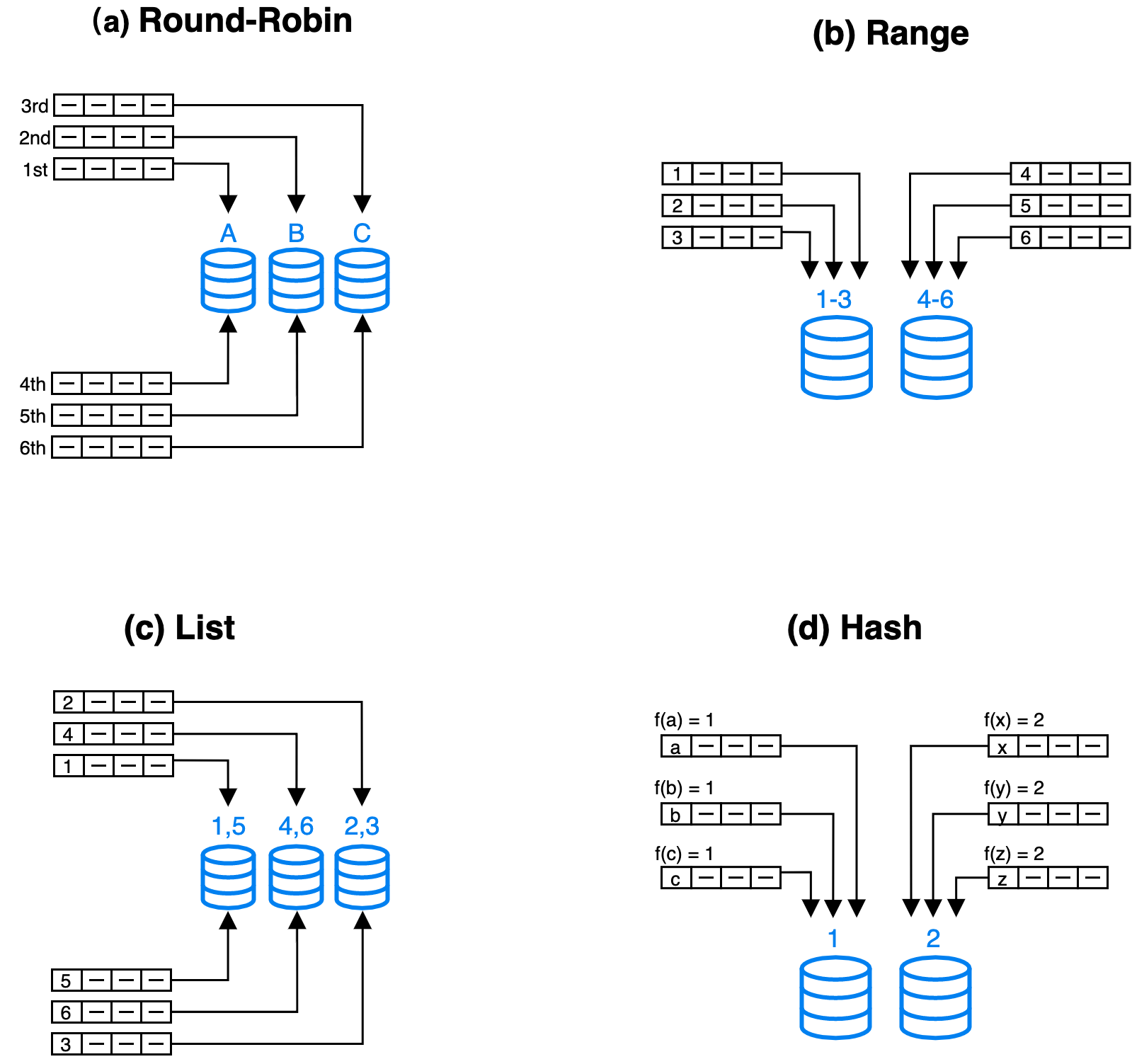
- ラウンドロビン: データを異なるノードに循環的に分配します。
- レンジ: パーティション列の値の範囲に基づいてデータを異なるノードに分配します。
- リスト: パーティション列の離散値(例: 年齢)に基づいてデータを異なるノードに分配します。
- ハッシュ: ハッシュアルゴリズムに基づいてデータを異なるノードに分配します。
より柔軟なデータ分散を実現するために、ビジネス要件に基づいて、前述の4つのパーティション化の手法を組み合わせることができます。例えば、ハッシュ-ハッシュ、レンジ-ハッシュ、ハッシュ-リストなどです。StarRocks は次の2つのパーティション化の手法を提供します:
-
ハッシュ: ハッシュパーティション化されたテーブルは1つのパーティション(テーブル全体が1つのパーティションと見なされます)しか持ちません。パーティションは、バケッティング列と指定したタブレット数に基づいてタブレットに分割されます。
例えば、次のステートメントは
site_accessというテーブルを作成します。このテーブルはsite_id列に基づいて10個のタブレットに分割されます。CREATE TABLE site_access(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id) BUCKETS 10; -
レンジ-ハッシュ: レンジ-ハッシュパーティション化されたテーブルは、パーティション列に基づいてデータを複数のパーティションに分割します。各パーティションは、バケッティング列と指定したタブレット数に基づいてさらにタブレットに分割されます。
例えば、次のステートメントは
event_day列でパーティション化されたsite_accessというテーブルを作成します。このテーブルはp1、p2、p3の3つのパーティションを含みます。各パーティションはsite_id列に基づいて10個のタブレットに分割されます。CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
パーティション化とバケッティングのルールを設計する
テーブルをパーティション化する前に、パーティション列、バケッティング列、およびタブレット数を決定します。
パーティション列を選ぶ
パーティション化されたテーブルのデータは、パーティション列(パーティションキーとも呼ばれます)に基づいて分割されます。一般的に、日付や地域がパーティション列として使用されます。StarRocks では、DATE、DATETIME、または INT 型の列のみがパーティション列として使用できます。以下の提案に従ってパーティション列を決定することをお勧めします。
- 低基数の列。
- クエリでフィルターとしてよく使用される列。
- 各パーティションのデータ量は100 GB未満である必要があります。
バケッティング列を選ぶ
パーティション内のデータは、バケッティング列のハッシュ値とバケット数に基づいてタブレットに細分化されます。以下の2つの要件を満たす列をバケッティング列として選ぶことをお勧めします。
- 高基数の列(例: ID)
- クエリでフィルターとしてよく使用される列
しかし、両方の要件を満たす列が存在しない場合は、クエリの複雑さに応じてバケッティング列を決定する必要があります。
- クエリが複雑な場合、各バケット内のデータができるだけ均等になるように高基数の列をバケッティング列として選択し、クラスターリソースの利用率を向上させることをお勧めします。
- クエリが比較的単純な場合は、クエリ条件でよく使用される列をバケッティング列として選択し、クエリ効率を向上させることをお勧めします。
1つのバケッティング列を使用してパーティションデータを各タブレットに均等に分配できない場合は、複数のバケッティング列を選択することができます。以下のシナリオに基づいてバケッティング列の数を決定できます。
- 1つのバケッティング列: この方法はノード間のデータ転送を減らすことができます。短時間で実行されるクエリのパフォーマンスを向上させます。短時間で実行されるクエリは1つのサーバーでのみ実行され、少量のデータをスキャンします。
- 複数のバケッティング列: この方法は分散クラスターの並列性能を最大限に活用します。長時間実行されるクエリのパフォーマンスを向上させます。長時間実行されるクエリは複数のサーバーにまたがって実行され、複数のサーバーを並列に使用して大量のデータをスキャンします。最大で3つのバケッティング列を選択することをお勧めします。
注意事項
- テーブルを作成する際には、バケッティング列を指定する必要があります。
- バケッティング列のデータ型は INTEGER、DECIMAL、DATE/DATETIME、または CHAR/VARCHAR/STRING である必要があります。
- バケッティング列は指定後に変更できません。
- バケッティング列の値は更新できません。
例
次のステートメントは site_access という名前のテーブルを作成します。
CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
city_code VARCHAR(100),
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, site_id, city_code, user_name)
PARTITION BY RANGE(event_day)
(
PARTITION p1 VALUES LESS THAN ("2020-01-31"),
PARTITION p2 VALUES LESS THAN ("2020-02-29"),
PARTITION p3 VALUES LESS THAN ("2020-03-31")
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10;
この例では、site_access は site_id をバケッティング列として使用しています。この列はクエリでフィルターとして常に使用されるためです。バケッティング列がクエリでフィルターとして使用されると、StarRocks は関連するタブレットのみをスキャンし、クエリパフォーマンスが大幅に向上します。
次のステートメントを実行して site_access をクエリすると仮定します。クエリを送信した後、StarRocks は site_access の1つのタブレット内のデータのみをスキャンします。全体のクエリ速度は10個のタブレットをスキャンするよりもはるかに速くなります。
select sum(pv)
from site_access
where site_id = 54321;
しかし、site_id が不均等に分布しており、多くのクエリが少数のサイトに集中している場合、前述のバケッティング方法は深刻なデータスキューを引き起こし、システムのパフォーマンスボトルネックを引き起こします。この場合、バケッティング列の組み合わせを使用することができます。例えば、次のステートメントは site_id と city_code をバケッティング列として使用します。
CREATE TABLE site_access
(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id,city_code) BUCKETS 10;
タブレット数を決定する
タブレットは、StarRocks におけるデータファイルの組織化方法を反映しています。StarRocks 2.5 以降では、テーブルを作成する際にバケット数を設定する必要はなく、StarRocks が自動的にバケット数を設定します。
CREATE TABLE site_access(
site_id INT DEFAULT '10',
city_code SMALLINT,
user_name VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(site_id, city_code, user_name)
DISTRIBUTED BY HASH(site_id,city_code); --バケット数を設定する必要はありません
バケット数を設定する場合、StarRocks 2.4 以降のバージョンでは、クエリ中にタブレットを並列にスキャンするために複数のスレッドを使用することがサポートされています。これにより、スキャンパフォーマンスのタブレット数への依存が減少します。各タブレットには約10 GBの生データが含まれることをお勧めします。テーブルの各パーティションのデータ量を見積もり、タブレット数を決定できます。タブレットでの並列スキャンを有効にするには、GLOBAL enable_tablet_internal_parallel が有効になっていることを確認してください。
注: 既存のパーティションのタブレット数を変更することはできません。パーティションを追加する際にのみタブレット数を変更できます。
パーティションを管理する
パーティションを作成する
PARTITION BY RANGE 句を使用して、3つの方法でテーブルをパーティション化できます。
-
LESS THAN 句を使用してテーブルをパーティション化します。詳細は CREATE TABLE を参照してください。
PARTITION BY RANGE (k1, k2, ...)
(
PARTITION partition_name1 VALUES LESS THAN ("value1", "value2", ...),
PARTITION partition_name2 VALUES LESS THAN ("value1", "value2", ...),
PARTITION partition_name3 VALUES LESS THAN (MAXVALUE)
) -
固定範囲の値を指定してテーブルをパーティション化します。詳細は CREATE TABLE を参照してください。
PARTITION BY RANGE (k1, k2, k3, ...)
(
PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)],
PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, )],
"k3-upper1-2", ...
) -
START、END、および EVERY を指定してテーブルをパーティション化します。この方法を使用すると、一度に複数のパーティションを作成できます。詳細は CREATE TABLE を参照してください。
PARTITION BY RANGE (k1, k2, ...)
(
START ("value1") END ("value2") EVERY (INTERVAL value3 day)
)
例
次の例は、START、END、および EVERY を指定してテーブルをパーティション化する方法を示しています。
-
パーティション列のデータ型が DATE であり、START と END を介してパーティションの時間範囲を指定し、EVERY を介して時間範囲を定義します。例:
CREATE TABLE site_access (
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10
PROPERTIES ("replication_num" = "3"
);この例の PARTITION BY RANGE 句は次のように等価です。
PARTITION BY RANGE (datekey) (
PARTITION p20210101 VALUES [('2021-01-01'), ('2021-01-02')),
PARTITION p20210102 VALUES [('2021-01-02'), ('2021-01-03')),
PARTITION p20210103 VALUES [('2021-01-03'), ('2021-01-04'))
) -
パーティション列のデータ型が DATE であり、異なる時間範囲に対して異なる EVERY 句を指定します(互いに重複してはなりません)。例:
CREATE TABLE site_access(
datekey DATE,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey)
(
START ("2019-01-01") END ("2021-01-01") EVERY (INTERVAL 1 YEAR),
START ("2021-01-01") END ("2021-05-01") EVERY (INTERVAL 1 MONTH),
START ("2021-05-01") END ("2021-05-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10
PROPERTIES(
"replication_num" = "1"
);
この例の PARTITION BY RANGE 句は次のように等価です。
PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
)
-
パーティション列のデータ型が INT であり、START と END を使用してパーティションの値範囲を指定し、EVERY を使用して増分値を定義します。例:
注: EVERY で定義された増分値をダブルクォートしないでください。
CREATE TABLE site_access (
datekey INT,
site_id INT,
city_code SMALLINT,
user_name VARCHAR(32),
pv BIGINT DEFAULT '0'
)
ENGINE=olap
DUPLICATE KEY(datekey, site_id, city_code, user_name)
PARTITION BY RANGE (datekey) (START ("1") END ("5") EVERY (1)
)
DISTRIBUTED BY HASH(site_id) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);この例の PARTITION BY RANGE 句は次のように等価です。
PARTITION BY RANGE (datekey) (
PARTITION p2019 VALUES [('2019-01-01'), ('2020-01-01')),
PARTITION p2020 VALUES [('2020-01-01'), ('2021-01-01')),
PARTITION p202101 VALUES [('2021-01-01'), ('2021-02-01')),
PARTITION p202102 VALUES [('2021-02-01'), ('2021-03-01')),
PARTITION p202103 VALUES [('2021-03-01'), ('2021-04-01')),
PARTITION p202104 VALUES [('2021-04-01'), ('2021-05-01')),
PARTITION p20210501 VALUES [('2021-05-01'), ('2021-05-02')),
PARTITION p20210502 VALUES [('2021-05-02'), ('2021-05-03')),
PARTITION p20210503 VALUES [('2021-05-03'), ('2021-05-04'))
) -
テーブルが作成された後、ALTER TABLE ステートメントを使用してテーブルにパーティションを追加できます。
ALTER TABLE site_access
ADD PARTITIONS START ("2021-01-04") END ("2021-01-06") EVERY (INTERVAL 1 DAY);
パーティションを追加する
新しいパーティションを追加して、テーブルに入力データを保存できます。デフォルトでは、新しいパーティションのタブレット数は既存のパーティションのタブレット数と等しくなります。また、新しいパーティションのデータ量に応じてタブレット数を調整することもできます。
次のステートメントは、4月に生成されたデータを保存するためにテーブル site_access に新しいパーティション p4 を追加します。
ALTER TABLE site_access
ADD PARTITION p4 VALUES LESS THAN ("2020-04-30")
DISTRIBUTED BY HASH(site_id) BUCKETS 20;
パーティションを削除する
次のステートメントは、テーブル site_access からパーティション p1 を削除します。
ALTER TABLE site_access
DROP PARTITION p1;
注: パーティションが削除されてから24時間以内であれば、そのパーティションのデータはゴミ箱に残ります。この期間中に RECOVER ステートメントを実行して、このデータを復元することができます。
パーティションを復元する
次のステートメントは、テーブル site_access にパーティション p1 を復元します。
RECOVER PARTITION p1 FROM site_access;
パーティションを表示する
次のステートメントは、テーブル site_access のすべてのパーティションを表示します。
SHOW PARTITIONS FROM site_access;