Load data from MinIO
StarRocks provides the following options for loading data from MinIO:
- Synchronous loading using INSERT+
FILES() - Asynchronous loading using Broker Load
Each of these options has its own advantages, which are detailed in the following sections.
In most cases, we recommend that you use the INSERT+FILES() method, which is much easier to use.
However, the INSERT+FILES() method currently supports only the Parquet, ORC, and CSV file formats. Therefore, if you need to load data of other file formats such as JSON, or perform data changes such as DELETE during data loading, you can resort to Broker Load.
Before you begin
Make source data ready
Make sure the source data you want to load into StarRocks is properly stored in a MinIO bucket. You may also consider where the data and the database are located, because data transfer costs are much lower when your bucket and your StarRocks cluster are located in the same region.
In this topic, we provide you with a sample dataset. You can download this with curl:
curl -O https://starrocks-examples.s3.amazonaws.com/user_behavior_ten_million_rows.parquet
Load the Parquet file into your MinIO system and note the bucket name. The examples in this guide
use a bucket name of /starrocks.
Check privileges
You can load data into StarRocks tables only as a user who has the INSERT privilege on those StarRocks tables. If you do not have the INSERT privilege, follow the instructions provided in GRANT to grant the INSERT privilege to the user that you use to connect to your StarRocks cluster. The syntax is GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}.
Gather connection details
In a nutshell, to use MinIO Access Key authentication you need to gather the following information:
- The bucket that stores your data
- The object key (object name) if accessing a specific object in the bucket
- The MinIO endpoint
- The access key and secret key used as access credentials.
Use INSERT+FILES()
This method is available from v3.1 onwards and currently supports only the Parquet, ORC, and CSV (from v3.3.0 onwards) file formats.
Advantages of INSERT+FILES()
FILES() can read the file stored in cloud storage based on the path-related properties you specify, infer the table schema of the data in the file, and then return the data from the file as data rows.
With FILES(), you can:
- Query the data directly from MinIO using SELECT.
- Create and load a table using CREATE TABLE AS SELECT (CTAS).
- Load the data into an existing table using INSERT.
Typical examples
Querying directly from MinIO using SELECT
Querying directly from MinIO using SELECT+FILES() can give a good preview of the content of a dataset before you create a table. For example:
- Get a preview of the dataset without storing the data.
- Query for the min and max values and decide what data types to use.
- Check for
NULLvalues.
The following example queries the sample dataset previously added to your MinIO system.
The highlighted section of the command includes the settings that you may need to change:
- Set the
endpointandpathto match your MinIO system. - If your MinIO system uses SSL set
enable_ssltotrue. - Substitute your MinIO access key and secret for
AAAandBBB.
SELECT * FROM FILES
(
"aws.s3.endpoint" = "http://minio:9000",
"path" = "s3://starrocks/user_behavior_ten_million_rows.parquet",
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"format" = "parquet",
"aws.s3.use_aws_sdk_default_behavior" = "false",
"aws.s3.use_instance_profile" = "false",
"aws.s3.enable_path_style_access" = "true"
)
LIMIT 3;
The system returns the following query result:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 543711 | 829192 | 2355072 | pv | 2017-11-27 08:22:37 |
| 543711 | 2056618 | 3645362 | pv | 2017-11-27 10:16:46 |
| 543711 | 1165492 | 3645362 | pv | 2017-11-27 10:17:00 |
+--------+---------+------------+--------------+---------------------+
3 rows in set (0.41 sec)
Notice that the column names returned above are provided by the Parquet file.
Creating and loading a table using CTAS
This is a continuation of the previous example. The previous query is wrapped in CREATE TABLE AS SELECT (CTAS) to automate the table creation using schema inference. This means StarRocks will infer the table schema, create the table you want, and then load the data into the table. The column names and types are not required to create a table when using the FILES() table function with Parquet files as the Parquet format includes the column names.
The syntax of CREATE TABLE when using schema inference does not allow setting the number of replicas, so set it before creating the table. The example below is for a system with a single replica:
ADMIN SET FRONTEND CONFIG ('default_replication_num' = '1');
Create a database and switch to it:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Use CTAS to create a table and load the data of the sample dataset previously added to your MinIO system.
The highlighted section of the command includes the settings that you may need to change:
- Set the
endpointandpathto match your MinIO system. - If your MinIO system uses SSL set
enable_ssltotrue. - Substitute your MinIO access key and secret key for
AAAandBBB.
CREATE TABLE user_behavior_inferred AS
SELECT * FROM FILES
(
"aws.s3.endpoint" = "http://minio:9000",
"path" = "s3://starrocks/user_behavior_ten_million_rows.parquet",
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"format" = "parquet",
"aws.s3.use_aws_sdk_default_behavior" = "false",
"aws.s3.use_instance_profile" = "false",
"aws.s3.enable_path_style_access" = "true"
);
Query OK, 10000000 rows affected (3.17 sec)
{'label':'insert_a5da3ff5-9ee4-11ee-90b0-02420a060004', 'status':'VISIBLE', 'txnId':'17'}
After creating the table, you can view its schema by using DESCRIBE:
DESCRIBE user_behavior_inferred;
The system returns the following query result:
+--------------+------------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+------------------+------+-------+---------+-------+
| UserID | bigint | YES | true | NULL | |
| ItemID | bigint | YES | true | NULL | |
| CategoryID | bigint | YES | true | NULL | |
| BehaviorType | varchar(1048576) | YES | false | NULL | |
| Timestamp | varchar(1048576) | YES | false | NULL | |
+--------------+------------------+------+-------+---------+-------+
Query the table to verify that the data has been loaded into it. Example:
SELECT * from user_behavior_inferred LIMIT 3;
The following query result is returned, indicating that the data has been successfully loaded:
+--------+--------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+--------+------------+--------------+---------------------+
| 58 | 158350 | 2355072 | pv | 2017-11-27 13:06:51 |
| 58 | 158590 | 3194735 | pv | 2017-11-27 02:21:04 |
| 58 | 215073 | 3002561 | pv | 2017-11-30 10:55:42 |
+--------+--------+------------+--------------+---------------------+
Loading into an existing table using INSERT
You may want to customize the table that you are inserting into, for example, the:
- column data type, nullable setting, or default values
- key types and columns
- data partitioning and bucketing
Creating the most efficient table structure requires knowledge of how the data will be used and the content of the columns. This topic does not cover table design. For information about table design, see Table types.
In this example, we are creating a table based on knowledge of how the table will be queried and the data in the Parquet file. The knowledge of the data in the Parquet file can be gained by querying the file directly in MinIO.
- Since a query of the dataset in MinIO indicates that the
Timestampcolumn contains data that matches adatetimedata type, the column type is specified in the following DDL. - By querying the data in MinIO, you can find that there are no
NULLvalues in the dataset, so the DDL does not set any columns as nullable. - Based on knowledge of the expected query types, the sort key and bucketing column are set to the column
UserID. Your use case might be different for this data, so you might decide to useItemIDin addition to or instead ofUserIDfor the sort key.
Create a database and switch to it:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Create a table by hand (we recommend that the table have the same schema as the Parquet file you want to load from MinIO):
CREATE TABLE user_behavior_declared
(
UserID int(11) NOT NULL,
ItemID int(11) NOT NULL,
CategoryID int(11) NOT NULL,
BehaviorType varchar(65533) NOT NULL,
Timestamp datetime NOT NULL
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID)
PROPERTIES
(
'replication_num' = '1'
);
Display the schema so that you can compare it with the inferred schema produced by the FILES() table function:
DESCRIBE user_behavior_declared;
+--------------+----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------+------+-------+---------+-------+
| UserID | int | NO | true | NULL | |
| ItemID | int | NO | false | NULL | |
| CategoryID | int | NO | false | NULL | |
| BehaviorType | varchar(65533) | NO | false | NULL | |
| Timestamp | datetime | NO | false | NULL | |
+--------------+----------------+------+-------+---------+-------+
5 rows in set (0.00 sec)
Compare the schema you just created with the schema inferred earlier using the FILES() table function. Look at:
- data types
- nullable
- key fields
To better control the schema of the destination table and for better query performance, we recommend that you specify the table schema by hand in production environments. Having a datetime data type for the timestamp field is more efficient than using a varchar.
After creating the table, you can load it with INSERT INTO SELECT FROM FILES():
The highlighted section of the command includes the settings that you may need to change:
- Set the
endpointandpathto match your MinIO system. - If your MinIO system uses SSL set
enable_ssltotrue. - Substitute your MinIO access key and secret key for
AAAandBBB.
INSERT INTO user_behavior_declared
SELECT * FROM FILES
(
"aws.s3.endpoint" = "http://minio:9000",
"path" = "s3://starrocks/user_behavior_ten_million_rows.parquet",
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"format" = "parquet",
"aws.s3.use_aws_sdk_default_behavior" = "false",
"aws.s3.use_instance_profile" = "false",
"aws.s3.enable_path_style_access" = "true"
);
After the load is complete, you can query the table to verify that the data has been loaded into it. Example:
SELECT * from user_behavior_declared LIMIT 3;
The following query result is returned, indicating that the data has been successfully loaded:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 58 | 4309692 | 1165503 | pv | 2017-11-25 14:06:52 |
| 58 | 181489 | 1165503 | pv | 2017-11-25 14:07:22 |
| 58 | 3722956 | 1165503 | pv | 2017-11-25 14:09:28 |
+--------+---------+------------+--------------+---------------------+
Check load progress
You can query the progress of INSERT jobs from the loads view in the StarRocks Information Schema. This feature is supported from v3.1 onwards. Example:
SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;
For information about the fields provided in the loads view, see loads.
If you have submitted multiple load jobs, you can filter on the LABEL associated with the job. Example:
SELECT * FROM information_schema.loads WHERE LABEL = 'insert_e3b882f5-7eb3-11ee-ae77-00163e267b60' \G
*************************** 1. row ***************************
JOB_ID: 10243
LABEL: insert_e3b882f5-7eb3-11ee-ae77-00163e267b60
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: INSERT
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):300; max_filter_ratio:0.0
CREATE_TIME: 2023-11-09 11:56:01
ETL_START_TIME: 2023-11-09 11:56:01
ETL_FINISH_TIME: 2023-11-09 11:56:01
LOAD_START_TIME: 2023-11-09 11:56:01
LOAD_FINISH_TIME: 2023-11-09 11:56:44
JOB_DETAILS: {"All backends":{"e3b882f5-7eb3-11ee-ae77-00163e267b60":[10142]},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":311710786,"InternalTableLoadRows":10000000,"ScanBytes":581574034,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"e3b882f5-7eb3-11ee-ae77-00163e267b60":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
INSERT is a synchronous command. If an INSERT job is still running, you need to open another session to check its execution status.
Compare the table sizes on disk
This query compares the table with the inferred schema and the one where the schema is declared. Because the inferred schema has nullable columns and a varchar for the timestamp the data length is larger:
SELECT TABLE_NAME,
TABLE_ROWS,
AVG_ROW_LENGTH,
DATA_LENGTH
FROM information_schema.tables
WHERE TABLE_NAME like 'user_behavior%'\G
*************************** 1. row ***************************
TABLE_NAME: user_behavior_declared
TABLE_ROWS: 10000000
AVG_ROW_LENGTH: 10
DATA_LENGTH: 102562516
*************************** 2. row ***************************
TABLE_NAME: user_behavior_inferred
TABLE_ROWS: 10000000
AVG_ROW_LENGTH: 17
DATA_LENGTH: 176803880
2 rows in set (0.04 sec)
Use Broker Load
An asynchronous Broker Load process handles making the connection to MinIO, pulling the data, and storing the data in StarRocks.
This method supports the following file formats:
- Parquet
- ORC
- CSV
- JSON (supported from v3.2.3 onwards)
Advantages of Broker Load
- Broker Load runs in the background and clients do not need to stay connected for the job to continue.
- Broker Load is preferred for long-running jobs, with the default timeout spanning 4 hours.
- In addition to Parquet and ORC file format, Broker Load supports CSV file format and JSON file format (JSON file format is supported from v3.2.3 onwards).
Data flow
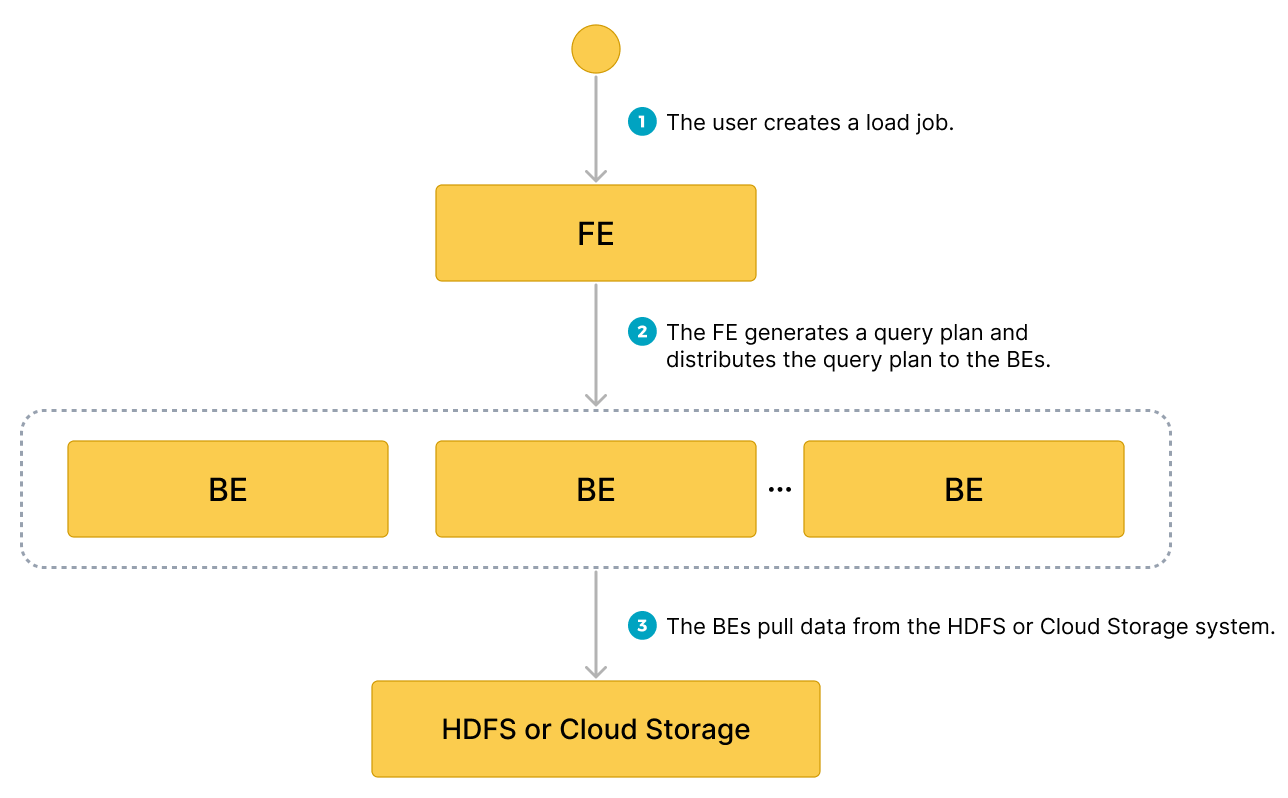
- The user creates a load job.
- The frontend (FE) creates a query plan and distributes the plan to the backend nodes (BEs) or compute nodes (CNs).
- The BEs or CNs pull the data from the source and load the data into StarRocks.
Typical example
Create a table, start a load process that pulls the sample dataset previously loaded to your MinIO system.
Create a database and a table
Create a database and switch to it:
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
Create a table by hand (we recommend that the table has the same schema as the Parquet file that you want to load from MinIO):
CREATE TABLE user_behavior
(
UserID int(11) NOT NULL,
ItemID int(11) NOT NULL,
CategoryID int(11) NOT NULL,
BehaviorType varchar(65533) NOT NULL,
Timestamp datetime NOT NULL
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID)
PROPERTIES
(
'replication_num' = '1'
);
Start a Broker Load
Run the following command to start a Broker Load job that loads data from the sample dataset user_behavior_ten_million_rows.parquet to the user_behavior table:
The highlighted section of the command includes the settings that you may need to change:
- Set the
endpointandDATA INFILEto match your MinIO system. - If your MinIO system uses SSL set
enable_ssltotrue. - Substitute your MinIO access key and secret for
AAAandBBB.
LOAD LABEL UserBehavior
(
DATA INFILE("s3://starrocks/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
)
WITH BROKER
(
"aws.s3.endpoint" = "http://minio:9000",
"aws.s3.enable_ssl" = "false",
"aws.s3.access_key" = "AAAAAAAAAAAAAAAAAAAA",
"aws.s3.secret_key" = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB",
"aws.s3.use_aws_sdk_default_behavior" = "false",
"aws.s3.use_instance_profile" = "false",
"aws.s3.enable_path_style_access" = "true"
)
PROPERTIES
(
"timeout" = "72000"
);
This job has four main sections:
LABEL: A string used when querying the state of the load job.LOADdeclaration: The source URI, source data format, and destination table name.BROKER: The connection details for the source.PROPERTIES: The timeout value and any other properties to apply to the load job.
For detailed syntax and parameter descriptions, see BROKER LOAD.
Check load progress
You can query the progress of Broker Load jobs from the loads view in the StarRocks Information Schema. This feature is supported from v3.1 onwards.
SELECT * FROM information_schema.loads;
For information about the fields provided in the loads view, see loads.
If you have submitted multiple load jobs, you can filter on the LABEL associated with the job. Example:
SELECT * FROM information_schema.loads
WHERE LABEL = 'UserBehavior'\G
*************************** 1. row ***************************
JOB_ID: 10176
LABEL: userbehavior
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: BROKER
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):72000; max_filter_ratio:0.0
CREATE_TIME: 2023-12-19 23:02:41
ETL_START_TIME: 2023-12-19 23:02:44
ETL_FINISH_TIME: 2023-12-19 23:02:44
LOAD_START_TIME: 2023-12-19 23:02:44
LOAD_FINISH_TIME: 2023-12-19 23:02:46
JOB_DETAILS: {"All backends":{"4aeec563-a91e-4c1e-b169-977b660950d1":[10004]},"FileNumber":1,"FileSize":132251298,"InternalTableLoadBytes":311710786,"InternalTableLoadRows":10000000,"ScanBytes":132251298,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"4aeec563-a91e-4c1e-b169-977b660950d1":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
1 row in set (0.02 sec)
After you confirm that the load job has finished, you can check a subset of the destination table to see if the data has been successfully loaded. Example:
SELECT * from user_behavior LIMIT 3;
The following query result is returned, indicating that the data has been successfully loaded:
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+
