Query plan
Optimizing query performance is a common challenge in analytics systems. Slow queries can impair user experience and overall cluster performance. In StarRocks, understanding and interpreting query plans and query profiles is the foundation for diagnosing and improving slow queries. These tools help you:
- Identify bottlenecks and expensive operations
- Spot suboptimal join strategies or missing indexes
- Understand how data is filtered, aggregated, and moved
- Troubleshoot and optimize resource usage
A query plan is a detailed roadmap generated by the StarRocks FE that describes how your SQL statement will be executed. It breaks down the query into a series of operations—such as scans, joins, aggregations, and sorts—and determines the most efficient way to perform them.
StarRocks provides several ways to inspect the query plan:
-
EXPLAIN statement:
UseEXPLAINto display the logical or physical execution plan for a query. You can add options to control the output:EXPLAIN LOGICAL <query>: Shows the simplified plan.EXPLAIN <query>: Shows the basic physical planEXPLAIN VERBOSE <query>: Shows the physical plan with detailed information.EXPLAIN COSTS <query>: Includes estimated costs for each operation, which is used to diagnose the statistics issue
-
EXPLAIN ANALYZE:
UseEXPLAIN ANALYZE <query>to execute the query and display the actual execution plan along with real runtime statistics. See the Explain Analyze documentation for details.Example:
EXPLAIN ANALYZE SELECT * FROM sales_orders WHERE amount > 1000; -
Query Profile:
After running a query, you can view its detailed execution profile, which includes timing, resource usage, and operator-level statistics. See the Query Profile documentation for how to access and interpret this information.- SQL commands:
SHOW PROFILELISTandANALYZE PROFILE FOR <query_id>: can be used to retrieve the execution profile for a specific query. - FE HTTP Service: Access query profiles via the StarRocks FE web UI by navigating to the Query or Profile section, where you can search for and inspect query execution details.
- Managed Version: In cloud or managed deployments, use the provided web console or monitoring dashboard to view query plans and profiles, often with enhanced visualization and filtering options.
- SQL commands:
Typically, the query plan is used to diagnose issues related to how a query is planned and optimized, while the query profile helps identify performance problems during query execution. In the following sections, we'll explore the key concepts of query execution and walk through a concrete example of analyzing a query plan.
Query execution flow
The lifecycle of a query in StarRocks consists of three main phases:
- Planning: The query undergoes parsing, analysis, and optimization, culminating in the generation of a query plan.
- Scheduling: The scheduler and coordinator distribute the plan to all participating backend nodes.
- Execution: The plan is executed using the pipeline execution engine.
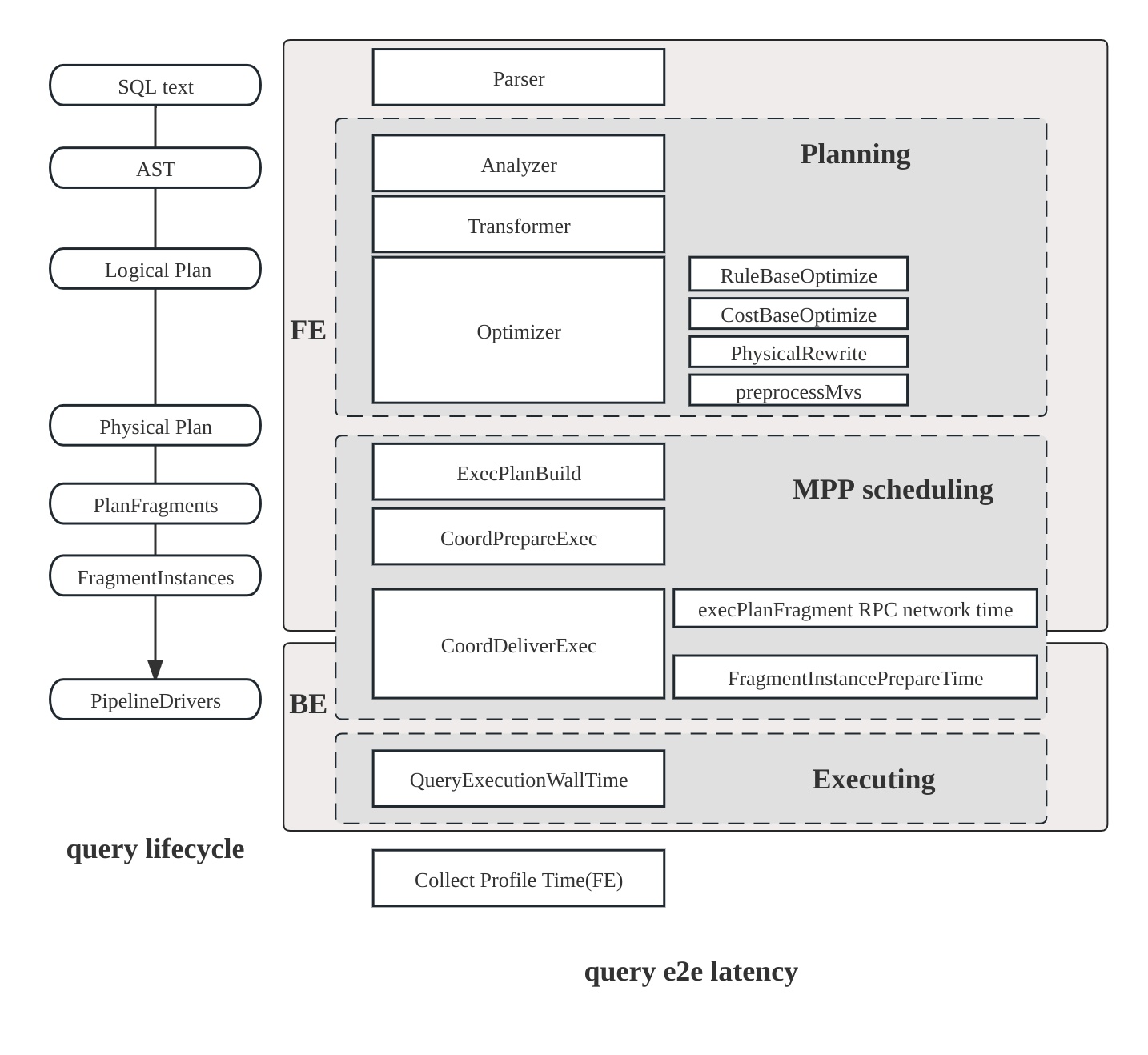
Plan structure
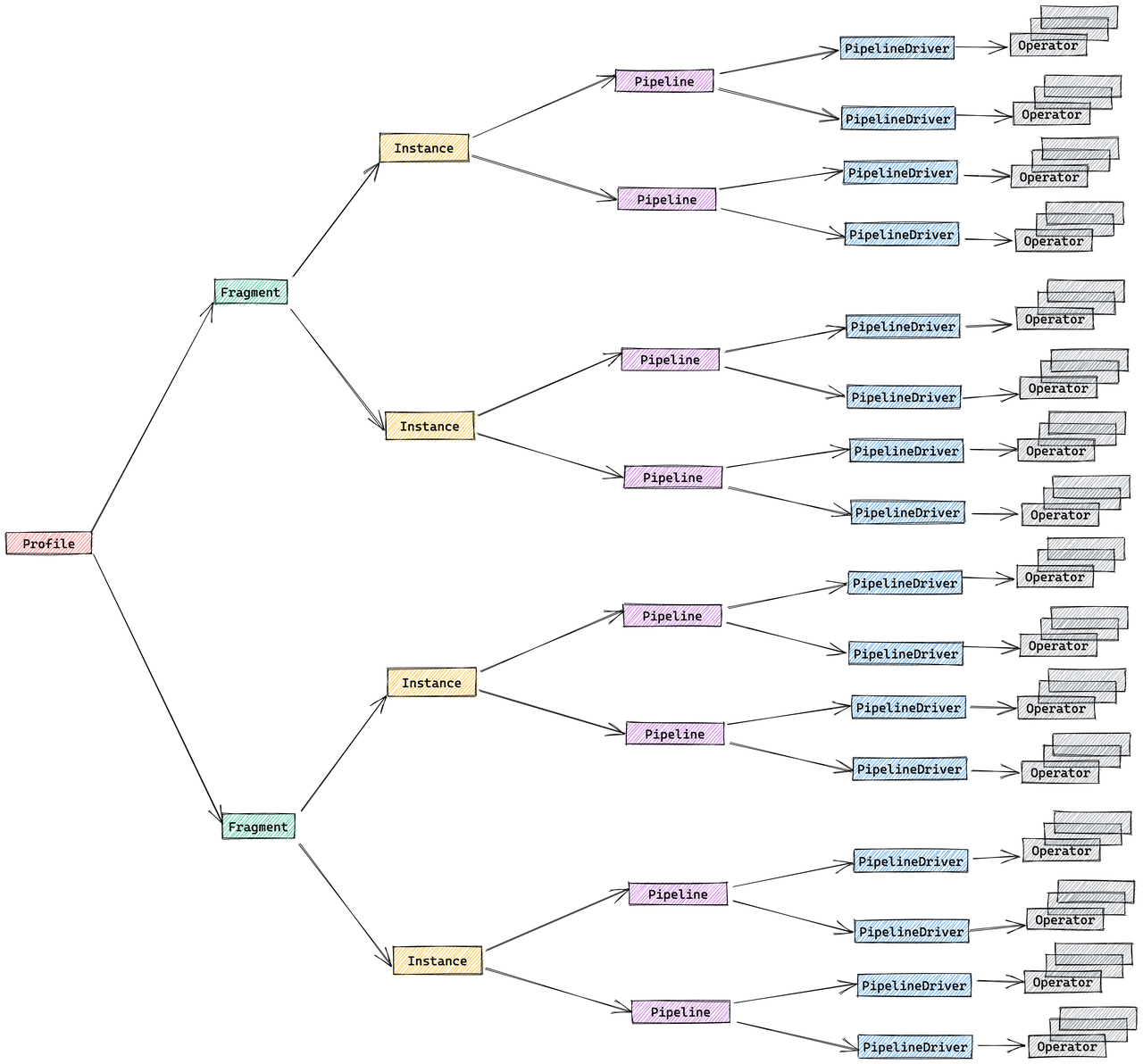
The StarRocks plan is hierarchical:
- Fragment: Top-level slice of work; each fragment spawns multiple FragmentInstances that run on different backend nodes.
- Pipeline: Within an instance, a pipeline strings operators together; several PipelineDrivers run the same pipeline concurrently on separate CPU cores.
- Operator: The atomic step—scan, join, aggregate—that actually processes data.
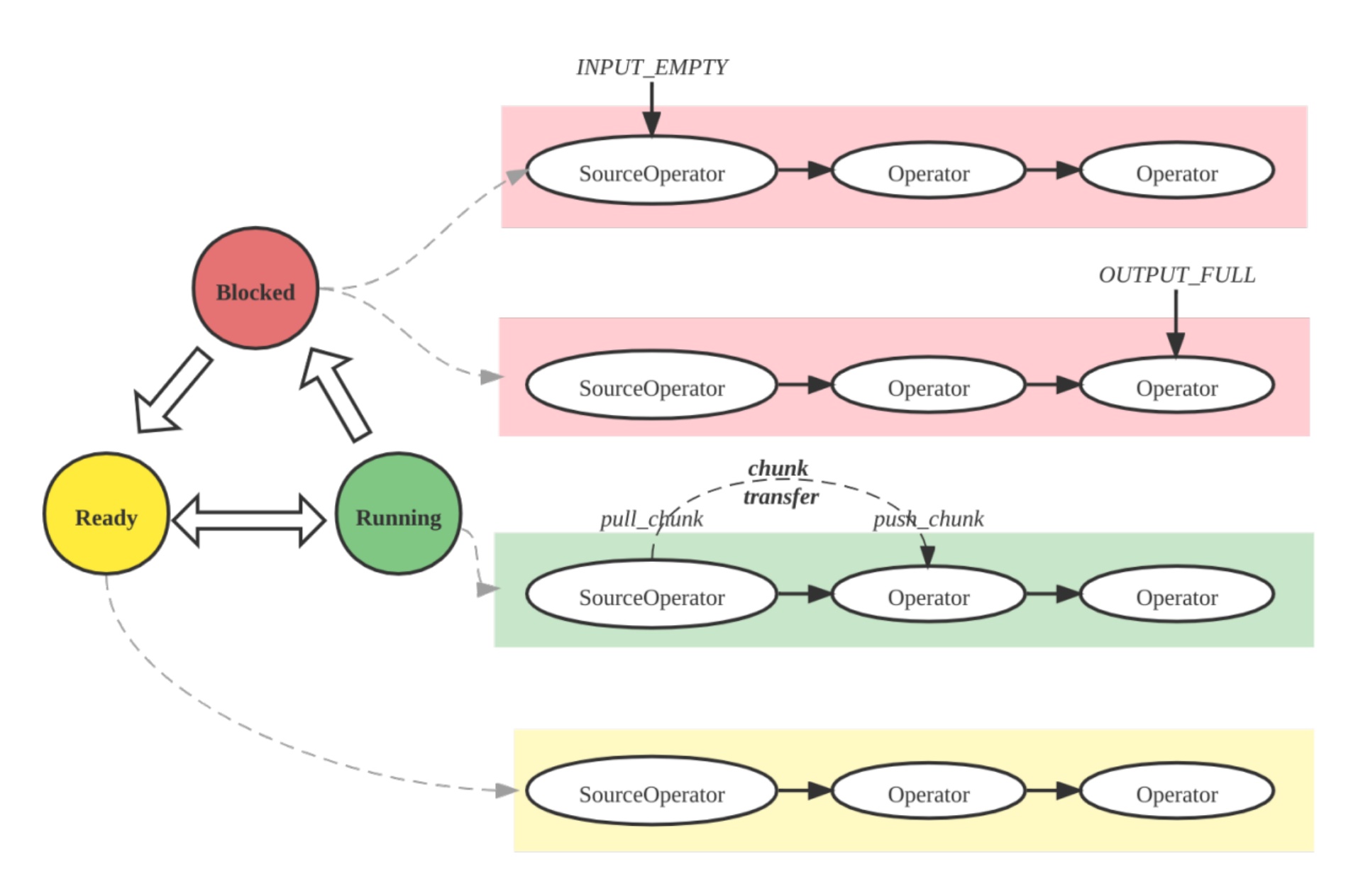
Pipeline execution engine
The Pipeline Engine executes the query plan in a parallel and efficient manner, handling complex plans and large data volumes for high performance and scalability.
Metric merging strategy
By default, StarRocks merges the FragmentInstance and PipelineDriver layers to reduce profile volume, resulting in a simplified three-layer structure:
- Fragment
- Pipeline
- Operator
You can control this merging behavior through the session variable pipeline_profile_level.
Example
How to read a query plan and profile
-
Understand the structure: Query plans are split into fragments, each representing a stage of execution. Read from the bottom up: scan nodes first, then joins, aggregations, and finally the result.
-
Overall analysis:
- Check total runtime, memory usage, and CPU/wall time ratio.
- Find slow operators by sorting by operator time.
- Ensure filters are pushed down where possible.
- Look for data skew (uneven operator times or row counts).
- Monitor for high memory or disk spill; adjust join order or use rollup views if needed.
- Use materialized views and query hints (
BROADCAST,SHUFFLE,COLOCATE) to optimize as needed.
-
Scan operations: Look for
OlapScanNodeor similar. Note which tables are scanned, what filters are applied, and if pre-aggregation or materialized views are used. -
Join operations: Identify join types (
HASH JOIN,BROADCAST,SHUFFLE,COLOCATE,BUCKET SHUFFLE). The join method affects performance:- Broadcast: Small table sent to all nodes; good for small tables.
- Shuffle: Rows are partitioned and shuffled; good for large tables.
- Colocate: Tables partitioned the same way; enables local joins.
- Bucket Shuffle: Only one table is shuffled to reduce network cost.
-
Aggregation and sorting: Look for
AGGREGATE,TOP-N, orORDER BY. These can be expensive with large or high-cardinality data. -
Data movement:
EXCHANGEnodes show data transfer between fragments or nodes. Too much data movement can hurt performance. -
Predicate pushdown: Filters applied early (at scan) reduce downstream data. Check
PREDICATESorPushdownPredicatesto see which filters are pushed down.
Example query plan
This is query 96 from the TPC-DS benchmark.
explain logical
select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
The output is a hierarchical plan showing how StarRocks will execute the query. The plan is structured as a tree of operators, read from bottom to top. The logical plan shows the sequence of operations with cost estimates:
- Output => [69:count]
- TOP-100(FINAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669801.20}
- TOP-100(PARTIAL)[69: count ASC NULLS FIRST]
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 8.00, cost: 68669769.20}
- AGGREGATE(GLOBAL) []
Estimates: {row: 1, cpu: 8.00, memory: 8.00, network: 0.00, cost: 68669737.20}
69:count := count(69:count)
- EXCHANGE(GATHER)
Estimates: {row: 1, cpu: 8.00, memory: 0.00, network: 8.00, cost: 68669717.20}
- AGGREGATE(LOCAL) []
Estimates: {row: 1, cpu: 3141.35, memory: 0.80, network: 0.00, cost: 68669701.20}
69:count := count()
- HASH/INNER JOIN [9:ss_store_sk = 40:s_store_sk] => [71:auto_fill_col]
Estimates: {row: 3490, cpu: 111184.52, memory: 8.80, network: 0.00, cost: 68668128.93}
71:auto_fill_col := 1
- HASH/INNER JOIN [7:ss_hdemo_sk = 25:hd_demo_sk] => [9:ss_store_sk]
Estimates: {row: 19940, cpu: 1841177.20, memory: 2880.00, network: 0.00, cost: 68612474.92}
- HASH/INNER JOIN [4:ss_sold_time_sk = 30:t_time_sk] => [7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 199876, cpu: 69221191.15, memory: 7077.97, network: 0.00, cost: 67671726.32}
- SCAN [store_sales] => [4:ss_sold_time_sk, 7:ss_hdemo_sk, 9:ss_store_sk]
Estimates: {row: 5501341, cpu: 66016092.00, memory: 0.00, network: 0.00, cost: 33008046.00}
partitionRatio: 1/1, tabletRatio: 192/192
predicate: 7:ss_hdemo_sk IS NOT NULL
- EXCHANGE(BROADCAST)
Estimates: {row: 1769, cpu: 7077.97, memory: 7077.97, network: 7077.97, cost: 38928.81}
- SCAN [time_dim] => [30:t_time_sk]
Estimates: {row: 1769, cpu: 21233.90, memory: 0.00, network: 0.00, cost: 10616.95}
partitionRatio: 1/1, tabletRatio: 5/5
predicate: 33:t_hour = 8 AND 34:t_minute >= 30
- EXCHANGE(BROADCAST)
Estimates: {row: 720, cpu: 2880.00, memory: 2880.00, network: 2880.00, cost: 14400.00}
- SCAN [household_demographics] => [25:hd_demo_sk]
Estimates: {row: 720, cpu: 5760.00, memory: 0.00, network: 0.00, cost: 2880.00}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 28:hd_dep_count = 5
- EXCHANGE(BROADCAST)
Estimates: {row: 2, cpu: 8.80, memory: 8.80, network: 8.80, cost: 44.15}
- SCAN [store] => [40:s_store_sk]
Estimates: {row: 2, cpu: 17.90, memory: 0.00, network: 0.00, cost: 8.95}
partitionRatio: 1/1, tabletRatio: 1/1
predicate: 45:s_store_name = 'ese'
Reading the plan bottom-up
The query plan should be read from the bottom (leaf nodes) upward to the top (root node), following the data flow:
-
Scan Operations (Bottom Level): The
SCANoperators at the bottom read data from the base tables:SCAN [store_sales]reads the main fact table with predicatess_hdemo_sk IS NOT NULLSCAN [time_dim]reads the time dimension table with predicatest_hour = 8 AND t_minute >= 30SCAN [household_demographics]reads the demographics table with predicatehd_dep_count = 5SCAN [store]reads the store table with predicates_store_name = 'ese'
Each scan operation shows:
- Estimates: Row count, CPU, memory, network, and cost estimates
- Partition and tablet ratios: How many partitions/tablets are scanned (e.g.,
partitionRatio: 1/1, tabletRatio: 192/192) - Predicates: Query conditions that are pushed down to the scan level, reducing the amount of data read
-
Data Exchange (Broadcast): The
EXCHANGE(BROADCAST)operations distribute smaller dimension tables to all nodes processing the larger fact table. This is efficient when dimension tables are small compared to the fact table, as seen withtime_dim,household_demographics, andstorebeing broadcast. -
Join Operations (Middle Level): Data flows upward through
HASH/INNER JOINoperations:- First,
store_salesis joined withtime_dimonss_sold_time_sk = t_time_sk - Then, the result is joined with
household_demographicsonss_hdemo_sk = hd_demo_sk - Finally, the result is joined with
storeonss_store_sk = s_store_sk
Each join shows the join condition and estimates for the resulting row count and resource usage.
- First,
-
Aggregation (Upper Level):
AGGREGATE(LOCAL)performs local aggregation on each node, computingcount()EXCHANGE(GATHER)collects results from all nodesAGGREGATE(GLOBAL)merges the local results into the final count
-
Final Operations (Top Level):
TOP-100(PARTIAL)andTOP-100(FINAL)operations handle theORDER BY count(*) LIMIT 100clause, selecting the top 100 results after ordering
The logical plan provides cost estimates for each operation, helping you understand where the query spends most of its resources. The actual physical execution plan (from EXPLAIN or EXPLAIN VERBOSE) includes additional details about how operations are distributed across nodes and executed in parallel.
